TOC
Open TOC
Info
https://alfredthiel.gitbook.io/pintosbook/
download
$ systemctl restart docker$ docker run -it pkuflyingpig/pintos bashboot pintos
$ git clone git@github.com:PKU-OS/pintos.git$ docker run -it --rm --name pintos --mount type=bind,source=/home/vgalaxy/Desktop/pintos,target=/home/PKUOS/pintos pkuflyingpig/pintos bashcode guide
- https://alfredthiel.gitbook.io/pintosbook/appendix/reference-guide
- https://pku-os.github.io/pintos-doxygen/html/
build pintos
在每个 lab 的目录下构建
cd pintos/src/threadsmake注意 Make.vars 的使用
run pintos
一个工具 pintos
root@b00e4d9d168d:~/pintos/src/threads/build# which pintos/home/PKUOS/toolchain/x86_64/bin/pintos使用如下
pintos option1 option2 ... -- arg1 arg2 ...pintos -h在 build 文件夹下使用
cd buildpintos --pintos -- run alarm-multiple键入 Ctrl + c 或 Ctrl + a + x 关闭 qemu
虚拟化栈如下
- First, You used docker to run a Ubuntu container that functions as a full-edged Linux OS inside your host OS.
- Then you used Qemu to simulate a 32-bit x86 computer inside your container.
- Finally, you boot a tiny toy OS — Pintos on the computer which Qemu simulates.
https://github.com/PKU-OS/Pintos-dockerfile/blob/main/dockerfile
reproducibility
- 可复现,非实时
pintos --bochs -j 1 -- run alarm-multiple可以设定随机种子
- 不可复现,实时
pintos --bochs -r -- run alarm-multiple默认的 QEMU 仅支持这个模式
testing
make tests/threads/alarm-multiple.result更多的选项
VERBOSE=1PINTOSOPTS='-j 1'
一键回归测试
make checkdebugging
pintos --gdb -- run alarm-multiple然后键入
docker exec -it pintos bash打开另一个终端
使用另一个工具 pintos-gdb
cd pintos/src/threads/buildpintos-gdb kernel.o在 gdb 中键入命令
target remote localhost:1234或使用宏
debugpintosmore
- printf 二分调试
- 死循环二分调试 -> triple fault
- assert 断言与回溯地址
- 使用 backtrace 工具解析回溯地址
- special attributes
Lab0: Getting Real
Loading
- threads/loader.S
- threads/start.S
- threads/init.c
Task 1: Booting Pintos
Exercise 1.1
Take screenshots of the successful booting of Pintos in QEMU and Bochs.
使用 qemu

使用 bochs
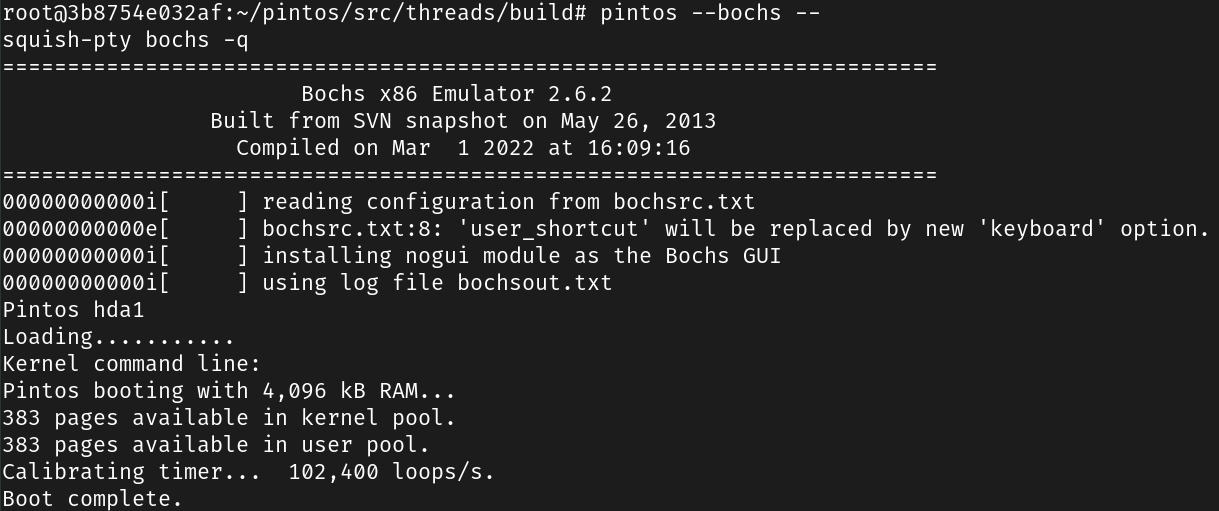
Task 2: Debugging
Exercise 2.1
Your first task in this section is to use GDB to trace the QEMU BIOS a bit to understand how an IA-32 compatible computer boots. Answer the following questions in your design document:
- What is the first instruction that gets executed?
使用 gdb 调试
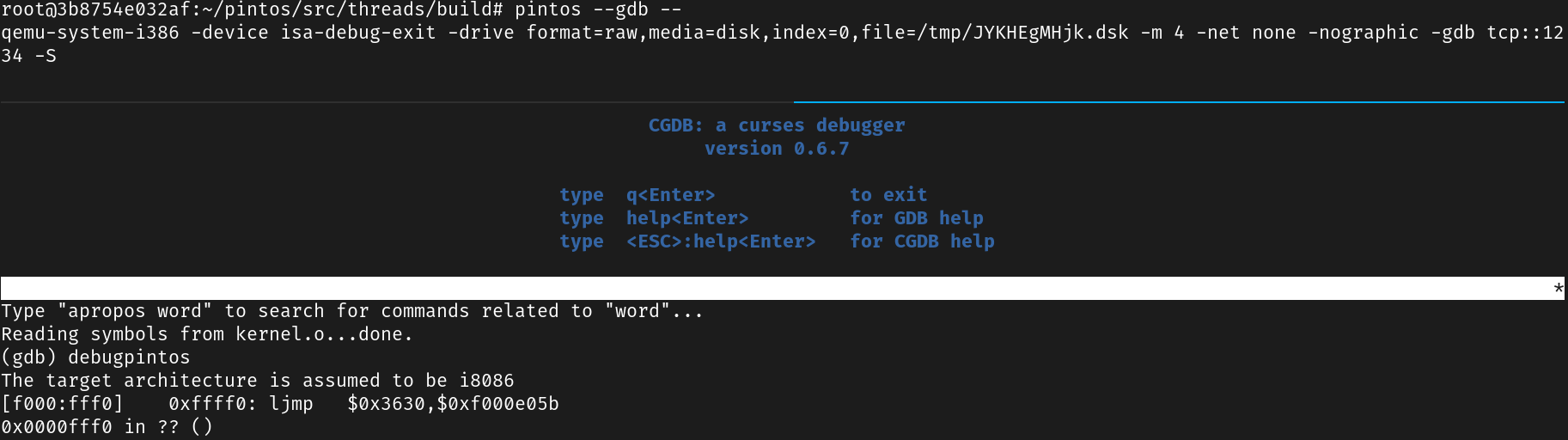
可知第一条指令
ljmp $0x3630,$0xf000e05b- At which physical address is this instruction located?
0xffff0位于 BIOS ROM 区,该部分的代码会寻找 bootable device,并加载前 512 字节到 0x7c00 位置
下面的示意图展示了物理地址空间布局
+------------------+ <- 0x00100000 (1MB)| BIOS ROM |+------------------+ <- 0x000F0000 (960KB)/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\+------------------+ <- 0x00007e00 (31.5KB)| pintos loader |+------------------+ <- 0x00007c00 (31KB)Exercise 2.2
Trace the Pintos bootloader and answer the following questions in your design document:
- How does the bootloader read disk sectors? In particular, what BIOS interrupt is used?
参考 read_sector 例程
#### Sector read subroutine. Takes a drive number in DL (0x80 = hard#### disk 0, 0x81 = hard disk 1, ...) and a sector number in EBX, and#### reads the specified sector into memory at ES:0000. Returns with#### carry set on error, clear otherwise. Preserves all#### general-purpose registers.
read_sector: pusha sub %ax, %ax push %ax # LBA sector number [48:63] push %ax # LBA sector number [32:47] push %ebx # LBA sector number [0:31] push %es # Buffer segment push %ax # Buffer offset (always 0) push $1 # Number of sectors to read push $16 # Packet size mov $0x42, %ah # Extended read mov %sp, %si # DS:SI -> packet int $0x13 # Error code in CF popa # Pop 16 bytes, preserve flagspopa_ret: popa ret # Error code still in CF其中 int $0x13 触发 BIOS 中断
- How does the bootloader decide whether it successfully finds the Pintos kernel?
从 read_mbr 开始,先 read_sector,读取成功后,检查 MBR signature,然后检查是否为 unused partition / Pintos kernel partition / bootable partition,所有检查都通过后,才会 load_kernel
- What happens when the bootloader could not find the Pintos kernel?
打印 Not found
no_such_drive:no_boot_partition: # Didn't find a Pintos kernel partition anywhere, give up. call puts .string "\rNot found\r"
# Notify BIOS that boot failed. See [IntrList]. int $0x18- At what point and how exactly does the bootloader transfer control to the Pintos kernel?
加载内核完成后,从 ELF header 中读取 start address,然后跳转
#### Transfer control to the kernel that we loaded. We read the start#### address out of the ELF header (see [ELF1]) and convert it from a#### 32-bit linear address into a 16:16 segment:offset address for#### real mode, then jump to the converted address. The 80x86 doesn't#### have an instruction to jump to an absolute segment:offset kept in#### registers, so in fact we store the address in a temporary memory#### location, then jump indirectly through that location. To save 4#### bytes in the loader, we reuse 4 bytes of the loader's code for#### this temporary pointer.
mov $0x2000, %ax mov %ax, %es mov %es:0x18, %dx mov %dx, start movw $0x2000, start + 2 ljmp *start所有的输出汇总如下
Pintos hda1Loading...........一些注意点,gdb 显示汇编,注意 dest 在后面
(gdb) x/6i 0x7c00 0x7c00: sub %eax,%eax 0x7c02: mov %eax,%ds 0x7c04: mov %eax,%ss 0x7c06: mov $0xf000,%sp 0x7c0a: add %al,(%eax) 0x7c0c: sub %edx,%edxloader.asm 对应如下
sub %ax, %ax 7c00: 29 c0 sub %eax,%eax mov %ax, %ds 7c02: 8e d8 mov %eax,%ds mov %ax, %ss 7c04: 8e d0 mov %eax,%ss mov $0xf000, %esp 7c06: 66 bc 00 f0 mov $0xf000,%sp 7c0a: 00 00 add %al,(%eax)
# Configure serial port so we can report progress without connected VGA.# See [IntrList] for details. sub %dx, %dx # Serial port 0. 7c0c: 29 d2 sub %edx,%edx然而,loader.S 中没有 add %al,(%eax),在实际执行时会直接跳过
sub %ax, %ax mov %ax, %ds mov %ax, %ss mov $0xf000, %esp
# Configure serial port so we can report progress without connected VGA.# See [IntrList] for details. sub %dx, %dx # Serial port 0.Exercise 2.3
Trace the Pintos kernel and answer the following questions in your design document:
- At the entry of
pintos_init(), what is the value of the expressioninit_page_dir[pd_no(ptov(0))]in hexadecimal format?
(gdb) p init_page_dir[pd_no(ptov(0))]=> 0xc000efef: int3=> 0xc000efef: int3$8 = 0- When
palloc_get_page()is called for the first time,
what does the call stack look like?
(gdb) bt#0 palloc_get_page (flags=(PAL_ASSERT | PAL_ZERO)) at ../../threads/palloc.c:113#1 0xc00203aa in paging_init () at ../../threads/init.c:168#2 0xc002031b in pintos_init () at ../../threads/init.c:100#3 0xc002013d in start () at ../../threads/start.S:180what is the return value in hexadecimal format?
(gdb) p palloc_get_multiple (flags, 1)=> 0xc000ef7f: int3$9 = (void *) 0xc0101000what is the value of expression init_page_dir[pd_no(ptov(0))] in hexadecimal format?
(gdb) p init_page_dir[pd_no(ptov(0))]=> 0xc000ef7f: int3=> 0xc000ef7f: int3$10 = 0- When
palloc_get_page()is called for the third time,
what does the call stack look like?
(gdb) bt#0 palloc_get_page (flags=PAL_ZERO) at ../../threads/palloc.c:113#1 0xc0020a81 in thread_create (name=0xc002e895 "idle", priority=0, function=0xc0020eb0 <idle>, aux=0xc000efbc) at ../../threads/thread.c:178#2 0xc0020976 in thread_start () at ../../threads/thread.c:111#3 0xc0020334 in pintos_init () at ../../threads/init.c:119#4 0xc002013d in start () at ../../threads/start.S:180what is the return value in hexadecimal format?
(gdb) p palloc_get_multiple (flags, 1)=> 0xc000ef3f: int3$11 = (void *) 0xc0104000what is the value of expression init_page_dir[pd_no(ptov(0))] in hexadecimal format?
(gdb) p/x init_page_dir[pd_no(ptov(0))]=> 0xc000ef3f: int3=> 0xc000ef3f: int3$13 = 0x103027参考 https://cgdb.github.io/docs/CGDB-Mode.html#CGDB-Mode 学习 cgdb 的使用
- ESC -> 进入 CGDB 模式
- page up / page down
- space -> Sets a breakpoint at the current line number.
- t -> Sets a temporary breakpoint at the current line number.
- F5 -> Send a run command to GDB.
- F6 -> Send a continue command to GDB.
- F7 -> Send a finish command to GDB.
- F8 -> Send a next command to GDB.
- F10 -> Send a step command to GDB.
- i -> 进入 GDB 模式
- page up / page down
Task 3: Kernel Monitor
Exercise 3.1
Enhance threads/init.c to implement a tiny kernel monitor in Pintos.
Requirments:
- It starts with a prompt
PKUOS>and waits for user input. - As the user types in a printable character, display the character.
- When a newline is entered, it parses the input and checks if it is
whoami. If it iswhoami, print your student id. Afterward, the monitor will print the command promptPKUOS>again in the next line and repeat. - If the user input is
exit, the monitor will quit to allow the kernel to finish. For the other input, printinvalid command. Handling special input such as backspace is not required. - If you implement such an enhancement, mention this in your design document.
简单实现一下即可
static void run_monitor (void) { char input[64]; size_t count; while (1) { printf("PKUOS> "); count = 0; memset(input, 0, sizeof(input)); while (1) { uint8_t key = input_getc(); putchar(key); input[count++] = key; if (count == 64) { // overflow printf("\n"); break; } if (key == '\r') { // not \n printf("\n"); break; } } if (!strcmp(input, "whoami\r")) { printf("201250012\n"); } else if (!strcmp(input, "exit\r")) { break; } else { printf("invalid command\n"); } }}似乎只能在 qemu 中愉快的运行,各模拟器对输入解读为 \r 还是 \n 似乎并不一致
Lab1: Threads
Threads
Run a Thread for the First Time
4 kB +---------------------------------+ | aux | | function | | eip (NULL) | kernel_thread_frame +---------------------------------+ | eip (to kernel_thread) | switch_entry_frame +---------------------------------+ | next | | cur | | eip (to switch_entry) | | ebx | | ebp | | esi | | edi | switch_threads_frame +---------------------------------+ | kernel stack | | | | | | | | V | | grows downward |sizeof (struct thread) +---------------------------------+ | magic | | : | | : | | name | | status | 0 kB +---------------------------------+以 idle 线程为例
static voidschedule (void){ struct thread *cur = running_thread (); struct thread *next = next_thread_to_run (); struct thread *prev = NULL;
ASSERT (intr_get_level () == INTR_OFF); ASSERT (cur->status != THREAD_RUNNING); ASSERT (is_thread (next));
if (cur != next) prev = switch_threads (cur, next); thread_schedule_tail (prev);}打印 cur 和 next
(gdb) p *cur$1 = {tid = 1, status = THREAD_BLOCKED, name = "main", '\000' <repeats 11 times>, stack = 0xc000f000 "'", priority = 31, allelem = {prev = 0xc0038218 <all_list>, next = 0xc0103020}, elem = {prev = 0xc000efc0, next = 0xc000efc8}, magic = 3446325067}(gdb) p *next$2 = {tid = 2, status = THREAD_READY, name = "idle", '\000' <repeats 11 times>, stack = 0xc0103fd4 "", priority = 0, allelem = {prev = 0xc000e020, next = 0xc0038220 <all_list+8>}, elem = {prev = 0xc0038208 <ready_list>, next = 0xc0038210 <ready_list+8>}, magic = 3446325067}观察 thread_create 构造的 fake stack frames
(gdb) x/11wx 0xc0103fd40xc0103fd4: 0x00000000 0x00000000 0x00000000 0x000000000xc0103fe4: 0xc00213d2 0x00000000 0x00000000 0xc0020fc70xc0103ff4: 0x00000000 0xc0020f95 0xc000efb进入 switch_threads,push 保存寄存器
switch_threads: # Save caller's register state. # # Note that the SVR4 ABI allows us to destroy %eax, %ecx, %edx, # but requires us to preserve %ebx, %ebp, %esi, %edi. See # [SysV-ABI-386] pages 3-11 and 3-12 for details. # # This stack frame must match the one set up by thread_create() # in size. pushl %ebx pushl %ebp pushl %esi pushl %edi此时 esp 为 0xc000ef2c
(gdb) p $esp$8 = (void *) 0xc000ef2c然后切换 stack pointer
# Get offsetof (struct thread, stack)..globl thread_stack_ofs mov thread_stack_ofs, %edx
# Save current stack pointer to old thread's stack, if any. movl SWITCH_CUR(%esp), %eax movl %esp, (%eax,%edx,1)
# Restore stack pointer from new thread's stack. movl SWITCH_NEXT(%esp), %ecx movl (%ecx,%edx,1), %espthread_stack_ofs 为 24
SWITCH_CUR 为 20
0xc000ef2c + 20 = 0xc000ef40
(gdb) x/wx 0xc000ef400xc000ef40: 0xc000e0000xc000e000 即为 cur 的栈底
将 esp 寄存器的值存入 0xc000e000 + 24
自然语言描述为,从 switch_threads_frame 中读取 cur,并将 esp 寄存器的值存入 cur 的 stack
同理,接下来从 switch_threads_frame 中读取 next,并将 esp 寄存器的值设置为 next 的 stack,即 0xc0103fd4
然后恢复寄存器
popl %edi popl %esi popl %ebp popl %ebx retpop 恢复寄存器后 ret,返回到 switch_entry
switch_entry: # Discard switch_threads() arguments. addl $8, %esp
# Call thread_schedule_tail(prev). pushl %eax.globl thread_schedule_tail call thread_schedule_tail addl $4, %esp
# Start thread proper. retaddl 后 esp 为 0xc0103ff0,eax 为 0xc000e000,即 prev (之前的 cur) 的栈底
然后调用 thread_schedule_tail,设置线程状态,并开始新的时间片
addl 后 esp 仍为 0xc0103ff0
然后 ret,返回到 kernel_thread,此处第一个参数和第二个参数正好为 function 和 aux
IA-32 通过栈传递函数参数
比较 tricky 的地方在于,之后的栈切换 pop 恢复寄存器后,ret 会回到 schedule 而非 switch_entry,然后调用 thread_schedule_tail
如第二次栈切换
(gdb) p *cur$20 = {tid = 2, status = THREAD_BLOCKED, name = "idle", '\000' <repeats 11 times>, stack = 0xc0103fd4 "\004\020\002\300\274\357", priority = 0, allelem = {prev = 0xc000e020, next = 0xc0038220 <all_list+8>}, elem = {prev = 0xc0038208 <ready_list>, next = 0xc0038210 <ready_list+8>}, magic = 3446325067}(gdb) p *next$21 = {tid = 1, status = THREAD_READY, name = "main", '\000' <repeats 11 times>, stack = 0xc000ef2c "", priority = 31, allelem = {prev = 0xc0038218 <all_list>, next = 0xc0103020}, elem = {prev = 0xc0038208 <ready_list>, next = 0xc0038210 <ready_list+8>}, magic = 3446325067}切换回 main 线程,代表 idle 线程创建完毕,thread_start 结束,pintos_init 会继续执行
Synchronization
- Disabling Interrupts
- Semaphores
- Locks
- Monitors (cv)
- Optimization Barrier
Interrupt Handling
- Internal interrupts
- process context
intr_disable()does not disable internal interrupts
- External interrupts
- interrupt context
- an external interrupt’s handler must run with interrupts disabled
- an external interrupt’s handler must not sleep or yield
所以即使关了中断,在外部中断处理程序中仍然可能出现内部中断,如访存错误,然后触发嵌套中断
List
使用内核链表时,其内部需要有 list_elem 成员
struct foo{ struct list_elem elem; int bar; // ...other members...};
struct list foo_list;list_init (&foo_list);struct list_elem *e;
for (e = list_begin (&foo_list); e != list_end (&foo_list); e = list_next (e)){ struct foo *f = list_entry (e, struct foo, elem); // ...do something with f...}关键在于 list_entry 宏
#define list_entry(LIST_ELEM, STRUCT, MEMBER) \ ((STRUCT *) ((uint8_t *) &(LIST_ELEM)->next \ - offsetof (STRUCT, MEMBER.next)))&(LIST_ELEM)->next 得到 list_elem->next 的地址,然后减去其偏移即可
大概的示例图如下

无需动态分配内存,内存在结构体内部分配好了
可以有多个 list_elem 成员,可以想象 list_elem 成员就像结构体平面上的一些针孔,通过不同的针孔,list 就可以通过不同的方式将多个结构体串起来,这就是内核链表的原理
Alarm Clock
DATA STRUCTURES
A1: Copy here the declaration of each new or changed struct or struct member, global or static variable, typedef, or enumeration. Identify the purpose of each in 25 words or less.
在 thread 结构体中添加成员
int64_t ticks;struct semaphore tick_sema;ticks 初始化为 -1,在 timer_sleep 中设置为 now + ticks
tick_sema 用于唤醒线程
ALGORITHMS
A2: Briefly describe what happens in a call to timer_sleep(), including the effects of the timer interrupt handler.
若 ticks >= 1,则设置 ticks,并 P(&tick_sema)
timer interrupt handler 调用 thread_tick,其中会获取当前 ticks,并通过 thread_foreach 试图唤醒满足条件的 THREAD_BLOCKED 的线程
注意到只有 timer interrupt handler 会修改当前 ticks
A3: What steps are taken to minimize the amount of time spent in the timer interrupt handler?
由于需要遍历 all_list,当线程数量较多时可能会寄
SYNCHRONIZATION
A4: How are race conditions avoided when multiple threads call timer_sleep() simultaneously?
由于 timer_sleep 中不存在对共享变量的访问,所以不会出现数据竞争
A5: How are race conditions avoided when a timer interrupt occurs during a call to timer_sleep()?
理由同上,另外 timer_sleep 调用了 sema_down,其中会关闭中断,所以不会出现线程状态不一致的情形
RATIONALE
A6: Why did you choose this design? In what ways is it superior to another design you considered?
实现相当简单,但会影响 timer interrupt handler 的性能
由于 timer interrupt 为外部中断,handler 运行时中断是关闭的,并且似乎 pintos 没有支持多处理器,所以在同一时刻只会有一份 timer interrupt handler 的代码运行,于是就可以安全的遍历 all_list 啦
Priority Scheduling
thread_unblock / thread_yield / next_thread_to_run (schedule) 会修改 ready_list
使用 list_insert_ordered 按照 priority 大小插入
注意 less 函数中应使用 > 而非 >=,否则对于相同 priority 的线程会出现饥饿,然后 alarm-simultaneous 就无法通过
下面考虑 immediately yield 的问题,分为两种情形
- 主动 yield
例如显式设置 priority 或 create thread,这时只要检查 ready_list 的 head 是否拥有更高的 priority,若是则 thread_yield 即可
- 被动 yield
如某些高优先级线程在 thread_tick 中被唤醒,仍然是相同的检查,然后 intr_yield_on_return 即可
然后是 lock, semaphore 和 condition variable 唤醒的优先级问题
- semaphore
按照 priority 大小插入 sema->waiters 即可
然后唤醒时仍然是相同的检查,注意在 process context 和 interrupt context 中均可能调用 V,所以需要分情况 yield
- lock
由于 lock 是由 semaphore 实现的,所以不必修改什么
- condition variable
条件变量的实现有点反常,其内部是一个 waiters 的 list
然后 cond_wait 的内部有一个 semaphore_elem 类型的局部变量,其中包含 list_elem 和 semaphore 成员
实际插入 list 的是 semaphore_elem 的 list_elem,而非 thread 的 list_elem,所以需要在 semaphore_elem 中添加 priority 成员,并修改 less 函数
调用 cond_wait 时线程需要持有相应的 lock,插入后释放锁,并 P 那个 semaphore 成员
而 cond_signal 就是取出 waiters list 的 head,然后 V 那个 semaphore 成员
在 priority-condvar 的测试中,优先级最低的主线程首次 cond_signal,会唤醒优先级最高的线程,此时该线程会重新试图获取锁,然而主线程并未释放锁,所以该线程会主动 thread_block 让其余线程优先运行,此时若存在中间优先级的线程,就会产生优先级翻转的问题
由于 list_entry 宏在编译中没了,调试信息中没有这个符号,打印 ready_list 的第一个线程需要
p *((struct thread *) ((uint8_t *) ready_list->head->next - offset))此时可以通过如下测试
pass tests/threads/alarm-singlepass tests/threads/alarm-multiplepass tests/threads/alarm-simultaneouspass tests/threads/alarm-prioritypass tests/threads/alarm-zeropass tests/threads/alarm-negativepass tests/threads/priority-changepass tests/threads/priority-fifopass tests/threads/priority-preemptpass tests/threads/priority-semapass tests/threads/priority-condvar下面考虑实现优先级捐赠,从而解决优先级翻转的问题
研究一下测试用例,可以发现优先级捐赠的核心在于,某个高优先级线程因为某个 lock 而向某个低优先级线程捐赠优先级
对于低优先级线程而言,可能存在多个高优先级线程因为同一个 lock 而捐赠优先级 (priority-donate-one),也可能存在多个高优先级线程因为不同的 lock 而捐赠优先级 (priority-donate-multiple)
因而,需要在线程结构体中添加如下成员
struct donated_priority { struct lock* lock; int priority; struct thread* donator;};
struct donated_priority priority_chains[8];int priority_depth;初始时 priority_depth 为 0,称为 base priority,此时无视 donated_priority 结构中的 lock 和 donator 成员
这样做是为了统一为对
priority_chains的操作
通过 thread_set_priority 设置优先级时只需设置 base priority 即可
而对于下标 >= 1 的情形,最初的实现是只有 priority 成员,但这样低优先级线程就只能获得高优先级线程在捐赠时的优先级,若高优先级线程在捐赠后因为嵌套的优先级捐赠而提升了优先级,是无法通知低优先级线程的,所以引入了 donator 成员,弃用 priority 成员
实际上可以实现为 enum
priority_chains 数组大小代表该线程最多可以从 8 个 lock 中获得捐赠的优先级
实际上该实现存在一些问题,例如当多个高优先级线程因为同一个 lock 而捐赠优先级时,
donator成员只会记录在捐赠时优先级最高的线程,若其余高优先级线程在捐赠后优先级提升,同样无法通知低优先级线程,所以应该将donator字段设置为一个数组,不过测试用例中没有测,而且会增加实现复杂性,就算了吧
此时,对线程优先级的获取应通过递归实现
intget_priority_helper (struct thread *t){ int res = t->priority_chains[0].priority; if (t->priority_depth == 0) return res; for (int i = 1; i <= t->priority_depth; ++i) { int curr = get_priority_helper (t->priority_chains[i].donator); if (res < curr) res = curr; } return res;}受限于栈空间的大小,理论上可以实现任意次数的嵌套优先级捐赠
然后只需在 lock_acquire 和 lock_release 中维护上述数据结构即可
暂未考虑
lock_try_acquire
另外,由于此时线程的优先级并不固定,所以不必按照 priority 大小插入,而是在 pop 时选择优先级最高的线程即可
注意应使用 list_min 获取优先级最高的线程
此时可以通过如下测试
pass tests/threads/priority-donate-onepass tests/threads/priority-donate-multiplepass tests/threads/priority-donate-multiple2pass tests/threads/priority-donate-nestpass tests/threads/priority-donate-semapass tests/threads/priority-donate-lowerpass tests/threads/priority-donate-chainDATA STRUCTURES
B1: Copy here the declaration of each new or changed struct or struct member, global or static variable, typedef, or enumeration. Identify the purpose of each in 25 words or less.
上面解释过了
B2: Explain the data structure used to track priority donation. Use ASCII art to diagram a nested donation. (Alternately, submit a .png file.)
下面是嵌套优先级捐赠的示意图

ALGORITHMS
B3: How do you ensure that the highest priority thread waiting for a lock, semaphore, or condition variable wakes up first?
在 pop 时选择优先级最高的线程即可
B4: Describe the sequence of events when a call to lock_acquire() causes a priority donation. How is nested donation handled?
描述一下流程
low (base) priority thread -> lock_acquirehigh (base) priority thread -> lock_acquire note that the lock acquired by low priority thread if the priority of low priority thread < the priority of high priority thread if other high priority thread donate priority due to the lock update priority donation and donator (imprecise) else open up new space for priority chainsB5: Describe the sequence of events when lock_release() is called on a lock that a higher-priority thread is waiting for.
描述一下流程
low (base) priority thread -> lock_acquirehigh (base) priority thread -> lock_acquirelow (base) priority thread -> lock_release scan priority chains to find the corresponding lock if success delete the donation info and resize the priority chains else do nothingSYNCHRONIZATION
B6: Describe a potential race in thread_set_priority() and explain how your implementation avoids it. Can you use a lock to avoid this race?
首先框架代码中并未直接调用 thread_set_priority,只有测试代码会调用
可能出现的数据竞争,某个线程在 get priority 的过程中,另一个线程调用了 thread_set_priority,使得 get 的 priority 不准确
实现中并未考虑这一点,因为只要不发生交错,在未来的某一时候总能 get 到准确的 priority
不能使用 lock 避免该数据竞争,因为 lock 需要获取 priority 信息,带来了复杂性
RATIONALE
B7: Why did you choose this design? In what ways is it superior to another design you considered?
理由仍然是实现简单,潜在的效率问题
- push 和 pop 最坏情形是 ,可考虑使用类似堆的数据结构
- 对线程优先级的获取需要多次递归
Advanced Scheduler
DATA STRUCTURES
C1: Copy here the declaration of each new or changed struct or struct member, global or static variable, typedef, or enumeration. Identify the purpose of each in 25 words or less.
在线程结构体中添加如下成员
int recent_cpu;int niceness;其中 recent_cpu 为定点浮点数
添加全局变量 load_avg,为定点浮点数
ALGORITHMS
C2: How is the way you divided the cost of scheduling between code inside and outside interrupt context likely to affect performance?
当开启 thread_mlfqs 时,视线程的优先级为 t->priority_chains[0].priority
同时修改 priority donation 相应的逻辑,如获取线程优先级和 lock 的部分
初始化的部分,注意调用 thread_create 的线程,即 thread_current,就是新线程的 parent,同时需要特判 main 线程
对于数值的更新,全部在 thread_tick 中进行,时序如下
- 在
wakeup遍历中统计ready_threads - 若为
sec_edge,则更新 load_avg - 若为
four_ticks_edge,则通过recalculation遍历- 其中判断是否为
sec_edge从而更新 recent_cpu - 更新 priority
- 其中判断是否为
RATIONALE
C3: Briefly critique your design, pointing out advantages and disadvantages in your design choices. If you were to have extra time to work on this part of the project, how might you choose to refine or improve your design?
如何将数值的更新在 timer interrupt handler 之外完成
C4: The assignment explains arithmetic for fixed-point math in detail, but it leaves it open to you to implement it. Why did you decide to implement it the way you did? If you created an abstraction layer for fixed-point math, that is, an abstract data type and/or a set of functions or macros to manipulate fixed-point numbers, why did you do so? If not, why not?
以宏的方式实现,只使用头文件无需修改 Makefile
可以参考 https://nju-projectn.github.io/ics-pa-gitbook/ics2021/3.5.html#%E5%AE%9A%E7%82%B9%E7%AE%97%E6%9C%AF
Test
一键回归测试
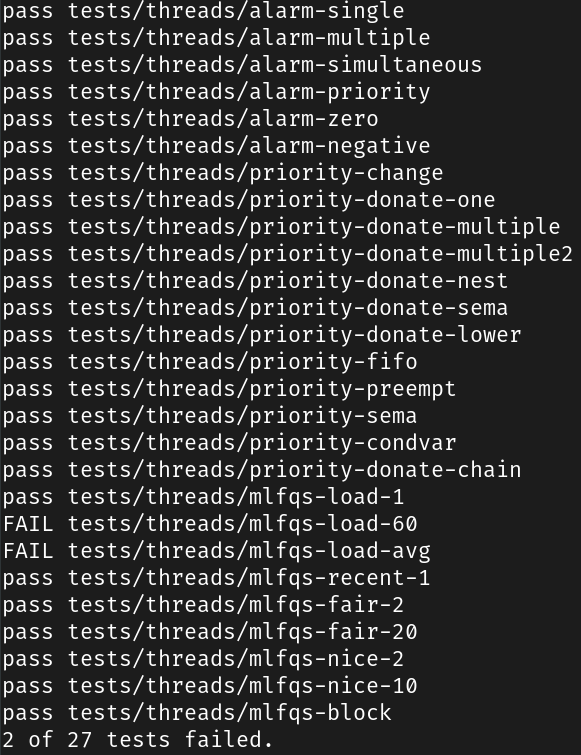
失败的测试用例如下

超时,调试发现在线程创建的过程中出现了活锁
使用 qemu 则可以通过

就这样吧