TOC
Open TOC
OS EX Concurrency
操作系统概述
理解操作系统:三个根本问题
- 操作系统服务谁?
程序 = 状态机
课程涉及:多线程 Linux 应用程序
- (设计/应用视角) 操作系统为程序提供什么服务?
操作系统 = 对象 + API
课程涉及:POSIX + 部分 Linux 特性
Mini Labs × 6
- (实现/硬件视角) 如何实现操作系统提供的服务?
操作系统 = C 程序
完成初始化后就成为 interrupt/trap/fault handler
课程涉及:xv6, 自制迷你操作系统
OS Labs × 5
操作系统上的程序
什么是程序 (源代码视角)
C 程序的状态机模型 (语义,semantics)
- 状态 = stack frame 的列表 (每个 frame 有 PC) + 全局变量
- 初始状态 = main(argc, argv), 全局变量初始化
- 迁移 = 执行 top stack frame PC 的语句; PC++
- 函数调用 = push frame (frame.PC = 入口)
- 函数返回 = pop frame
应用:非递归汉诺塔
什么是程序 (二进制代码视角)
- 状态 = 内存 M + 寄存器 R
- 初始状态 = gdb
starti - 迁移 = 执行一条指令
如何在程序的两个视角之间切换?
编译器:源代码 S (状态机) → 二进制代码 C (状态机)
编译 (优化) 的正确性 (Soundness) → S 与 C 的可观测行为严格一致
在保证观测一致性 (sound) 的前提下改写代码 (rewriting) 即为编译优化
有些部分是不可优化的,比如 volatile
extern int g;
int foo(int x) { g++; asm volatile("nop" : : "r"(x)); g++;}gcc -c -O2 a.c && objdump -d a.o 的输出为
0000000000000000 <foo>: 0: f3 0f 1e fa endbr64 4: 90 nop 5: 83 05 00 00 00 00 02 addl $0x2,0x0(%rip) # c <foo+0xc> c: c3 ret聪明的编译器会移动指令
但如果加上一个东西
extern int g;
int foo(int x) { g++; asm volatile("nop" : : "r"(x) : "memory"); g++;}gcc -c -O2 a.c && objdump -d a.o 的输出为
0000000000000000 <foo>: 0: f3 0f 1e fa endbr64 4: 83 05 00 00 00 00 01 addl $0x1,0x0(%rip) # b <foo+0xb> b: 90 nop c: 83 05 00 00 00 00 01 addl $0x1,0x0(%rip) # 13 <foo+0x13> 13: c3 retIf the assembler code does modify anything, use the
"memory"clobber to force the optimizers to flush all register values to memory and reload them if necessary after theasmstatement.
这种代码被称为 compile barrier
Further readings
- An executable formal semantics of C with applications (POPL’12)
- CompCert C verified compiler and a paper (POPL’06, Most Influential Paper Award 🏅)
- Copy-and-patch compilation (OOPSLA’21, Distinguished Paper 🏅)
操作系统中的一般程序
程序 = 计算 + syscall
最小的 Hello, OS World
#include <sys/syscall.h>
.globl _start_start: movq $SYS_write, %rax # write( movq $1, %rdi # fd=1, movq $st, %rsi # buf=st, movq $(ed - st), %rdx # count=ed-st syscall # );
movq $SYS_exit, %rax # exit( movq $1, %rdi # status=1 syscall # );
st: .ascii "\033[01;31mHello, OS World\033[0m\n"ed:编译和链接
gcc -c ./minimal.Sld ./minimal.o灵魂发问
main() 之前发生了什么?
/lib64/ld-linux-x86-64.so.2 加载了 libc
readelf
[Requesting program interpreter: /lib64/ld-linux-x86-64.so.2]
之后 libc 完成了自己的初始化
RTFM: libc startup on Hurd
一些彩蛋
- ANSI Escape Code
telnet towel.blinkenlights.nl(电影;Ctrl-] and q 退出)dialog --msgbox 'Hello, OS World!' 8 32ssh sshtron.zachlatta.com(网络游戏)
多处理器编程:从入门到放弃
入门
并发的基本单位——线程
共享内存的多个执行流
- 执行流拥有独立的堆栈/寄存器
- 共享全部的内存,指针可以互相引用
使用 thread.h 封装 pthread 库
注意使用 -pthread 编译
- 多线程 hello
printf 线程安全
- 证明线程确实共享内存
使用 sleep 控制线程顺序
- 证明线程具有独立堆栈,确定它们的范围
单核情形下只显示 T4
多核情形下根据第六列的数字排序
./a.out | sort -nk 6与机器相关,测试为 8MB
尝试修改堆栈的限制
man pthread_create
man 的示例代码似乎有问题
使用 pthread_attr_setstacksize
注意需要 init 和 destroy,否则会触发 segmentation fault
void create(void *fn) { pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setstacksize(&attr, 1024 * 1024); assert(tptr - tpool < NTHREAD); *tptr = (struct thread){ .id = tptr - tpool + 1, .status = T_LIVE, .entry = fn, }; // pthread_create(&(tptr->thread), NULL, wrapper, tptr); pthread_create(&(tptr->thread), &attr, wrapper, tptr); pthread_attr_destroy(&attr); ++tptr;}- 创建线程使用的系统调用
clone(child_stack=0x7f78c9d49ef0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tid=[31985], tls=0x7f78c9d4a640, child_tidptr=0x7f78c9d4a910) = 31985- 使用 gdb 调试
https://sourceware.org/gdb/onlinedocs/gdb/Threads.html
放弃
原子性
一段代码执行独占整个计算机系统
例子:两个线程让一个全局变量自增
- 单处理器多线程
- 线程在运行时可能被中断,切换到另一个线程执行
- ++ 运算符 → wrong
- add 指令 → true
- 多处理器多线程
- 线程根本就是并行执行的
- ++ 运算符 → wrong
- add 指令 → wrong
- lock add 原子指令 → true
另外,自增的内联汇编为
asm volatile("addq $1, %0;" : "+m"(sum));注意后缀 q
对于原子性的实现,目前略
顺序
编译器对内存访问 eventually consistent 的处理导致共享内存作为线程同步工具的失效
例子:还是两个线程让一个全局变量自增
使用 ++ 运算符,而非指令
vgalaxy@vgalaxy-VirtualBox:~/Templates/temp$ gcc -O1 sum.c -pthreadvgalaxy@vgalaxy-VirtualBox:~/Templates/temp$ ./a.outsum = 100000000vgalaxy@vgalaxy-VirtualBox:~/Templates/temp$ gcc -O2 sum.c -pthreadvgalaxy@vgalaxy-VirtualBox:~/Templates/temp$ ./a.outsum = 200000000为了实现源代码的按顺序翻译,可以在代码中插入优化不能穿越的 barrier,如
void Tsum() { for (int i = 0; i < N; i++) { asm volatile("" ::: "memory"); sum++; }}使用 volatile 变量失效
可见性
int x = 0, y = 0;
void T1() { x = 1; asm volatile("" : : "memory"); // compiler barrier printf("y = %d\n", y);}
void T2() { y = 1; asm volatile("" : : "memory"); // compiler barrier printf("x = %d\n", x);}从状态机的视角,我们最终能看到
1 10 11 0但是实际可能会出现如下情形
0 0突然发现虚拟机可以设置处理器数量,流畅度瞬间提升
单核情形下只能看到 0 1
多核情形下甚至没有 1 1
vgalaxy@vgalaxy-VirtualBox:~/Templates/temp$ ./a.out | head -n 100000 | sort | uniq -c 83276 0 0 11513 0 1 5211 1 0示例代码中使用了一些 atomic 的东西进行线程间的同步
这是因为现代的处理器也是动态编译器
单个处理器把汇编代码用电路编译成更小的 μops
每个 μop 都有 Fetch, Issue, Execute, Commit 四个阶段
在任何时刻,处理器都维护一个 μop 的池子
每一周期向池子补充尽可能多的 μop,即多发射
在不违反编译正确性的前提下,每一周期执行尽可能多的 μop,即乱序执行、按序提交
于是,满足单处理器 eventual memory consistency 的执行,在多处理器上可能无法序列化
多处理器间即时可见性的丧失
这便是宽松内存模型,目的是使单处理器的执行更高效
为了避免这种情形,需要使用一些特殊的函数或指令
__sync_synchronize()
https://gcc.gnu.org/onlinedocs/gcc/_005f_005fsync-Builtins.html
- fence 指令
asm volatile("movl $1, %0;" // x = 1 "mfence;" "movl %2, %1;" // y_val = y : "=m"(x), "=r"(y_val) : "m"(y));- 原子指令
如之前的 lock add
理解并发程序执行
画状态机理解并发程序
尝试实现一个互斥算法
假设一个内存的读/写可以保证顺序、原子完成,即非宽松内存模型
有一个失败的尝试
int locked = UNLOCK;
void critical_section() {retry: if (locked != UNLOCK) { goto retry; } locked = LOCK;
// critical section
locked = UNLOCK;}原因很简单,因为处理器默认不保证 load + store 的原子性
下面介绍 Peterson 算法,有一个形象的介绍
A 和 B 争用厕所的包厢 - 想进入包厢之前,A/B 都要先举起自己的旗子 - A 确认旗子举好以后,往厕所门上贴上 `B 正在使用` 的标签 - B 确认旗子举好以后,往厕所门上贴上 `A 正在使用` 的标签 - 然后,如果对方的旗子举起来,且门上的名字不是自己,等待 - 否则可以进入包厢 - 出包厢后,放下自己的旗子进入临界区的情况
- 如果只有一个人举旗,他就可以直接进入
- 如果两个人同时举旗,由厕所门上的标签决定谁进
- 手快就能进,自己的标签被另一个人的标签覆盖,手慢就🈚了
我们可以通过画状态机来理解 Peterson 算法
int x = 0, y = 0, turn = A;void TA() { while (1) {/* PC=1 */ x = 1;/* PC=2 */ turn = B;/* PC=3 */ while (y && turn == B) ; critical_section();/* PC=4 */ x = 0; } }void TB() { while (1) {/* PC=1 */ y = 1;/* PC=2 */ turn = A;/* PC=3 */ while (x && turn == A) ; critical_section();/* PC=4 */ y = 0; } }设计状态为一个五元组
然后开始画状态机
使用 Mermaid 手工画了部分状态,注意到状态机中出现了环,体现一点互斥的效果
只要枚举出所有状态,并且没有出现错误情形,就可以证明 Sequential 内存模型下 Peterson’s Protocol 的 Safety
实际运行
实际运行 Peterson 算法
在 critical section 区添加 nested 原子遍历检测是否有两个线程同时进入临界区
void critical_section() { long cnt = atomic_fetch_add(&count, 1); assert(atomic_fetch_add(&nested, 1) == 0); atomic_fetch_add(&nested, -1);}然而编译运行 peterson-simple.c,仍会出现 assertion failed
要等一段时间
因为之前的假设为非宽松内存模型,所以需要手动添加一些 barrier
如 __sync_synchronize
如何减少 barrier 的数量
自动画状态机理解并发程序
原理
使用 Model Checker
遍历所有可能的调度序列,即状态空间
将并发程序的正确性问题转化为图论问题
Safety → 红色的状态不可到达 → 可达性问题
否则无法实现互斥
(Strong) Liveness → 从任意状态出发,都能到达绿/蓝色状态 → 不存在只有黑色状态的环
否则即为 livelock
实现
当然是 Python 啦
容易 hack 的动态语言
丰富的库函数
重要语言机制 Python Generator
def numbers(init=0, step=1): n = init while True: n += step yield n每个 generator 对象都可以通过 yield 向外界返回自身的状态,即使是死循环
每个 generator 对象的状态都是独立的,并且在一个地址空间中
这恰好模拟了线程
于是只要在并发程序的每一行 yield checkpoint() 返回自身所有的状态即可
遇到 ModuleNotFoundError 需要安装包
pip install astor -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/Model Checker 只负责输出状态图
可以通过其他方法对输出可视化,如 visualize.py
python3 model-checker.py mutex-bad.py | python3 visualize.py > display.htmlopen display.html分析
下面分析一下 model-checker.py,采用自顶向下的方法
调用链为 check_bfs → State → execute → hack
def check_bfs(Class): '''Enumerate all possible thread interleavings of @mc.thread functions''' s0 = State(Class, trace=[])
# breadth-first search to find all possible thread interleavings queue, vertices, edges = [s0], {s0.name: s0}, [] while queue: u, queue = queue[0], queue[1:] for chosen, _ in enumerate(threads): v = State(Class, u.trace + [chosen]) if v.name not in vertices: queue.append(v) vertices[v.name] = v edges.append((u, v, chosen))
serialize(Class, s0, vertices, edges)check_bfs 接受一个类为参数
check_bfs 使用 BFS 的思路
通过构造 State 对象,得到状态所有可能的顶点和边后,最后使用 serialize 输出 hack 后的 CLASS,STATE 和 TRANS
在 State 的 __init__ 函数中构造 obj 和 state 和 name
class State: def __init__(self, Class, trace): self.trace = trace self.obj, self.state = execute(Class, trace) self.name = f's{abs(State.freeze(self.state).__hash__())}'obj 保存了一些变量,如 locked 等
state 则为一个列表,例如初始状态的 state 为
{'t1': (5, {}), 't2': (21, {}), 'locked': ''}name 则通过 hash 的方法以区分不同的 State
obj 和 state 通过 execute 函数得到
execute 函数 hack 掉给定的类后进行初始化
T = [] for t in threads: fn = getattr(obj, t) T.append(fn()) # a generator for a thread S = { t: T[i].__next__() for i, t in enumerate(threads) }T 中是两个 generator 对象,S 为初始状态的 state
然后根据 trace 模拟执行
while trace: chosen, tname, trace = trace[0], threads[trace[0]], trace[1:] try: if T[chosen]: S[tname] = T[chosen].__next__() except StopIteration: S.pop(tname) T[chosen] = None注意这里的 __next__ 的方法
最后解析出 obj
最后是 hack 函数,在第 52 行打上断点 breakpoint(),观察到 hacked_src 如下
class Mutex: locked = ''
def t1(self): yield checkpoint() while True: yield checkpoint() while self.locked == '馃敀': yield checkpoint() pass yield checkpoint() self.locked = '馃敀' yield checkpoint() cs = True yield checkpoint() del cs yield checkpoint() self.locked = ''
def t2(self): yield checkpoint() while True: yield checkpoint() while self.locked == '馃敀': yield checkpoint() pass yield checkpoint() self.locked = '馃敀' yield checkpoint() cs = True yield checkpoint() del cs yield checkpoint() self.locked = ''RTFSC 可知,第 50 行使用了 visit 方法
hacked_ast = Instrument().visit(ast.parse(Class.source))在 generic_visit 中对被 @thread 装饰的函数的每一行添加了 yield checkpoint()
hack 的过程中使用了 inspect, ast, astor
顺便提一下几个辅助函数
def thread(fn): '''Decorate a member function as a thread''' global threads threads.append(fn.__name__) return fn
def marker(fn): '''Decorate a member function as a state marker''' global marker_fn marker_fn.append(fn)
def localvar(s, t, varname): '''Return local variable value of thread t in state s''' return s[t][1].get(varname, None)
def checkpoint(): '''Instrumented `yield checkpoint()` goes here''' f = inspect.stack()[1].frame # stack[1] is the caller of checkpoint() return (f.f_lineno, { k: v for k, v in f.f_locals.items() if k != 'self' })thread 和 marker 中定义了一些全局变量
目标类被 @marker 装饰的函数调用了 localvar
而 checkpoint 则在 hack 的过程中使用
更多的 Model Checker
真实程序的状态空间太大?
- Model checking for programming languages using VeriSoft (POPL’97, 第一个“software model checker”)
- Finding and reproducing Heisenbugs in concurrent programs (OSDI’08, Small Scope Hypothesis 🪳🪳🪳)
- Using model checking to find serious file system errors (OSDI’04, Best Paper 🏅,可以用在不并发的系统上)
不满足于简单的内存模型?
- VSync: Push-button verification and optimization for synchronization primitives on weak memory models (ASPLOS’21, Distinguished Paper 🏅)
Valgrind - Helgrind
之前写 cmu-db 的时候已经安装了
RTFM → https://valgrind.org/docs/manual/manual.html
一些选项
https://valgrind.org/docs/manual/manual-core.html
--error-exitcode=<number> [default: 0]
--trace-children=<yes|no> [default: no]
- Memcheck
To use this tool, you may specify --tool=memcheck on the Valgrind command line.
You don’t have to, though, since Memcheck is the default tool.
检测内存泄露,类似 Address Sanitizer
一些选项
--leak-check=<no|summary|yes|full> [default: summary]
--track-origins=<yes|no> [default: no]
- Cachegrind
To use this tool, you must specify --tool=cachegrind on the Valgrind command line.
模拟缓存,计算命中率
一些选项
--cachegrind-out-file=<file> 用来指定输出的文件名
可以通过 cg_annotate <file> 得到更详细的结果
- Callgrind
To use this tool, you must specify --tool=callgrind on the Valgrind command line.
记录程序中函数之间的调用历史信息,对程序性能分析
包含了一些 Cachegrind 的功能
--callgrind-out-file=<file> 用来指定输出的文件名
可以通过 callgrind_annotate <file> 得到更详细的结果
还可以使用 callgrind_control 交互式地观察和控制当前运行的程序的状态
感觉不太好用
- Helgrind
To use this tool, you must specify --tool=helgrind on the Valgrind command line.
检测使用 POSIX 线程原语的程序中的同步错误
对于代码层面和指令层面的并发问题都能检测出来
ThreadSanitizer
详见 address-sanitizer.md
总结为只能检测出代码层面的并发问题
指令层面的并发问题检测不出来,如使用内联汇编的 sum.c 不会报错
一度误导我认为 gcc 没有这个功能
有没有可能可以增强检测
并发控制:互斥
核心问题:如何在多处理器上实现线程互斥?
共享内存上的互斥
实现互斥的根本困难:不能同时读/写共享内存
- load 的时候不能写,看到的东西马上就过时了
- store 的时候不能读,也不知道把什么改成了什么
自旋锁 (Spin Lock)
假设硬件能为我们提供一条瞬间完成的读 + 写指令
例如之前提及的 lock add,其中 lock 为指令前缀
更多的原子指令见 https://en.cppreference.com/w/cpp/header/stdatomic.h
进一步说,原子指令的模型为
- 保证之前的 store 都写入内存
- 保证 load/store 不与原子指令乱序
实现互斥
下面考虑 Atomic exchange
int xchg(volatile int *addr, int newval) { int result; asm volatile ("lock xchg %0, %1" : "+m"(*addr), "=a"(result) : "1"(newval)); return result;}我们考虑用 xchg 实现互斥
int table = YES;
void lock() {retry: int got = xchg(&table, NOPE); if (got == NOPE) goto retry; assert(got == YES);}
void unlock() { xchg(&table, YES)}简单来说就是 table 上有唯一的 YES,通过原子交换指令可以使唯一的线程拥有这个 YES
若没有得到 YES,则简单的自旋,故被称为自旋锁
可以简化为
int locked = 0;void lock() { while (xchg(&locked, 1)) ; }void unlock() { xchg(&locked, 0); }使用 Model Checker 进行正确性证明
注意 Python 代码的每一行对于 Model Checker 而言都是原子的,所以实现 xchg 非常轻松
甚至可以放在一个函数中,因为调用在一行内完成,仍然是原子的
原子指令的诞生
实际上,80486 就支持 dual-socket 了,相当于有两个 CPU 散片
两个 CPU 访问共享内存,就需要对内存上锁,这便诞生了原子指令
在现代,由于 CPU 有缓存,还需要考虑缓存的一致性
由于常见的原子操作,它们的本质都是
- load
- exec → 处理器本地寄存器的运算
- store
所以 RISC-V 提出了 Load-Reserved/Store-Conditional (LR/SC)
LR → 在内存上标记 reserved,中断、其他处理器写入都会导致标记消除
lr.w rd, (rs1) rd = M[rs1] reserve M[rs1]SC → 如果 reserved 未被解除,则写入
sc.w rd, rs2, (rs1) if still reserved: M[rs1] = rs2 rd = 0 else: rd = nonzero其硬件实现略
互斥锁 (Mutex Lock)
短临界区
显然自旋锁有明显的性能问题
- 缓存:自旋会触发处理器间的缓存同步,延迟增加
- 多核:除了进入临界区的线程,其他处理器上的线程都在空转,争抢锁的处理器越多,利用率越低
- 单核:获得自旋锁的线程,可能被操作系统切换出去,实现 100% 的资源浪费
可以通过 Scalability 这个维度来测试
例如将 sum 加上一亿次的任务平均分配不同的线程来执行,通过改变线程数来分析性能
见 sum-scalability.c
注意 include 头文件的顺序
可以发现随着线程数增加,使用 Spin Lock 进行线程同步的程序运行时间会增加
ThreadSanitizer 甚至警告,虽然没有触发 assertion
于是自旋锁的使用场景为
- 临界区几乎不拥堵
- 持有自旋锁时禁止执行流切换
如操作系统内核的并发数据结构,即短临界区
长临界区
更衣室管理
操作系统 = 更衣室管理员
OS 负责管理锁
用户程序使用如下两个系统调用
syscall(SYSCALL_lock, &lk);
试图获得 lk,但如果失败,就进入等待队列,并切换到其他线程
syscall(SYSCALL_unlock, &lk);
释放 lk,如果有等待锁的线程就唤醒
而在系统调用的实现中,则使用自旋锁以确保原子性
Futex = Spin + Mutex
分析
自旋锁 → 线程直接共享 locked
- 更快的 fast path
- xchg 成功 → 立即进入临界区,开销很小
- 更慢的 slow path
- xchg 失败 → 浪费 CPU 自旋等待
睡眠锁 → 通过系统调用访问 locked
- 更快的 slow path
- 上锁失败线程不再占用 CPU
- 更慢的 fast path
- 即便上锁成功也需要进出内核 (syscall)
于是优势结合便诞生了 Futex
Fast Userspace muTexes
- Fast path
- 一条原子指令,上锁成功立即返回
- Slow path
- 上锁失败,执行系统调用睡眠
- 性能优化的最常见技巧
- 看 average (frequent) case 或 workload 而不是 worst case
- 不同于 DSA
POSIX 线程库中的互斥锁 pthread_mutex 即为 Futex
在之前的 sum-scalability.c 使用 pthread_mutex,可以发现随着线程数增加,程序运行时间并不会明显增加
另外还可以使用 gdb 调试,在运行后键入 set scheduler-locking on,可以保证调试一个线程时,让其它线程暂停执行
https://wizardforcel.gitbooks.io/100-gdb-tips/content/set-scheduler-locking-on.html
于是 sum 会逐渐加一
键入 set scheduler-locking off 后,在一个线程执行 mutex_lock 时,会停顿片刻,然后发现 sum 会增加很多,这相当于上锁失败,执行系统调用睡眠
也可以通过 strace 观察系统调用,需使用 -f 参数
当线程数大于等于一时,才会有 futex 系统调用
实现
简易的实现,不是实际的实现
futex.py
先在用户空间自旋
- 如果获得锁,直接进入
- 未能获得锁,系统调用
- 解锁以后也需要系统调用
RTFM (劝退)
- futex (7), futex (2)
- A futex overview and update (LWN)
- Futexes are tricky (论 model checker 的重要性)
Take-away message
- 软件不够,硬件来凑 (自旋锁)
- 用户不够,内核来凑 (互斥锁)
- 找到你依赖的假设,并大胆地打破它
- Fast/slow paths: 性能优化的重要途径
并发控制:同步
核心问题:如何在多处理器上协同多个线程完成任务?
线程同步
在某个时间点共同达到互相已知的状态
生产者 - 消费者问题
从括号问题引入
在 printf 前后增加代码,使得打印的括号序列满足
- 一定是某个合法括号序列的前缀
- 括号嵌套的深度不超过
同步条件为
- 等到有空位再打印左括号
- 等到能配对时再打印右括号
即为生产者 - 消费者问题
使用 pc-check.py 进行压力测试
pthread_mutex
使用 pthread_mutex,若条件不满足则自旋
条件变量
万能模型
- 需要等待条件满足时
mutex_lock(&mutex);while (!cond) { wait(&cv, &mutex);}assert(cond);// ...// 互斥锁保证了在此期间条件 cond 总是成立// ...mutex_unlock(&mutex);注意这里的 while 语句
- 其他线程条件可能被满足时
broadcast(&cv);注意是广播而非私聊
OSTEP 中提供了使用两个条件变量的策略,这种情形下可以使用私聊
可以使用 model-checker 检验
信号量
复习:互斥锁和更衣室管理
完全没有必要限制手环的数量——让更多同学可以进入更衣室
P(&sem) - prolaag = try + decrease; wait; down; in
- 等待一个手环后返回
- 如果此时管理员手上有空闲的手环,立即返回
V(&sem) - verhoog = increase; post; up; out
- 变出一个手环,送给管理员
再谈条件变量
实现并行计算
明确计算顺序
struct job { void (*run)(void *arg); void *arg;}
while (1) { struct job *job;
mutex_lock(&mutex); while (! (job = get_job()) ) { wait(&cv, &mutex); } mutex_unlock(&mutex);
job->run(job->arg); // 不需要持有锁 // 可以生成新的 job // 注意回收分配的资源}Job queue
面试题
有三种线程,分别打印 <, >, 和 _
对这些线程进行同步,使得打印出的序列总是 <><_ 和 ><>_ 组合
对计算图建模
struct rule { int from, ch, to;};
struct rule rules[] = { { A, '<', B }, { B, '>', C }, { C, '<', D }, { A, '>', E }, { E, '<', F }, { F, '>', D }, { D, '_', A },};然后使用条件变量万能模型同步
哲学家吃饭问题
哲学家有时思考,有时吃饭
吃饭需要同时得到左手和右手的叉子
最基本的思路
P(&locks[rhs]);P(&locks[lhs]);V(&locks[rhs]);V(&locks[lhs]);可能会触发死锁
还是使用条件变量万能模型
mutex_lock(&mutex);while (!(avail[lhs] && avail[rhs])) { wait(&cv, &mutex);}avail[lhs] = avail[rhs] = false;mutex_unlock(&mutex);
mutex_lock(&mutex);avail[lhs] = avail[rhs] = true;broadcast(&cv);mutex_unlock(&mutex);OSTEP 中提供了另一种思路,即修改某个或者某些哲学家取叉子的顺序
另外还可以让一个人集中管理叉子
Leader/follower
分布式系统中非常常见的解决思路
void Tphilosopher(int id) { send_request(id, EAT); P(allowed[id]); // waiter 会把叉子递给哲学家 philosopher_eat(); send_request(id, DONE);}
void Twaiter() { while (1) { (id, status) = receive_request(); if (status == EAT) { ... } if (status == DONE) { ... } }}注意 philosopher.c 中的 Tphilosopher 函数参数源自 thread.h 中的 wrapper 函数,为 thread->id
wrapper 函数使得所有创建的线程都是同一个入口地址,实现了函数调用的 type safety
如何实现传入给定的参数
改变 entry 的签名,入参型别为
void *
真实世界的并发编程
高性能计算
一个例子 → Mandelbrot Set
依赖于命令行工具 viu 和 imagemagick
使用了 ppm 格式生成图像
生产者 - 消费者模式
- 计算部分为生产者,在水平方向分解任务
- 绘制部分为消费者
已有的框架 MPI/OpenMP
编译时 $(CFLAGS) 应该放在 $(FILE) 之后……
数据中心
多副本情况下的高可靠、低延迟数据访问
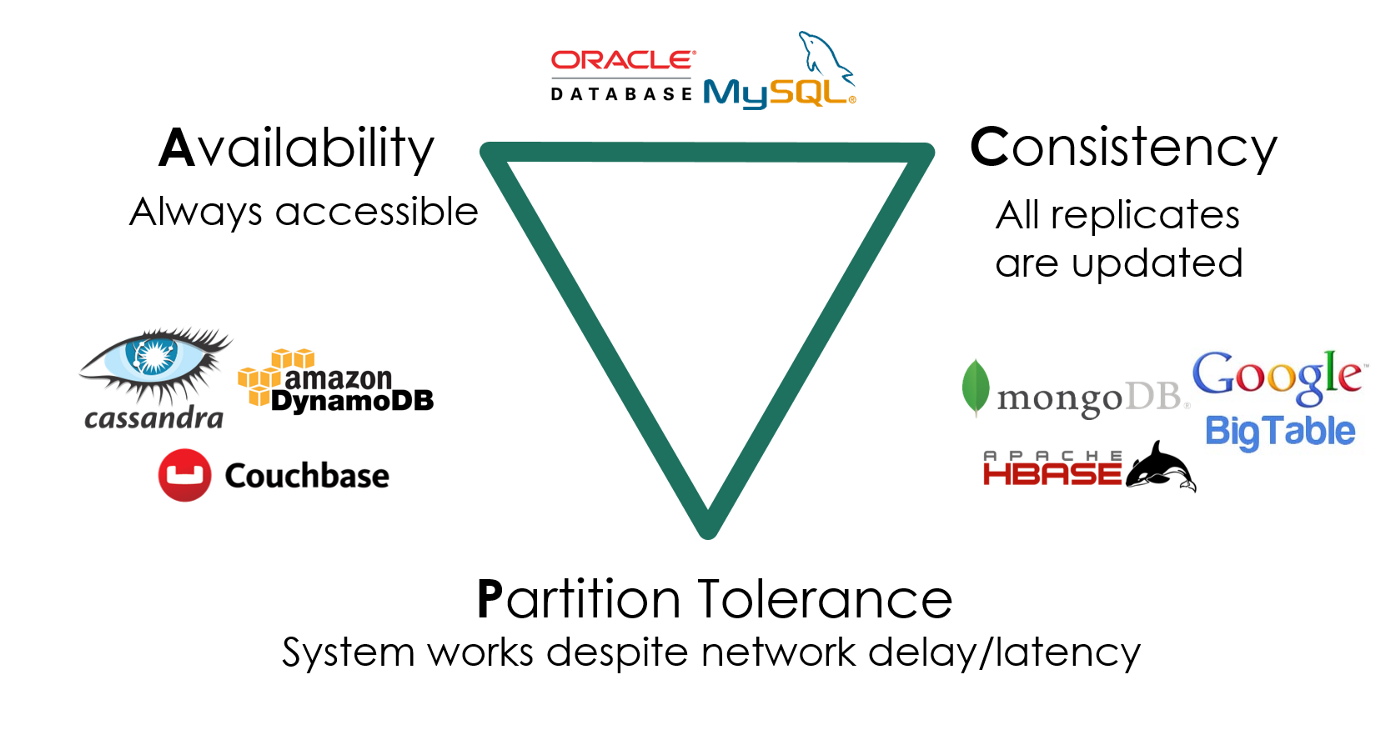
- 数据要保持一致 (Consistency)
- 服务时刻保持可用 (Availability)
- 容忍机器离线 (Partition tolerance)
使用协程和线程
- 计算部分
- 协程更加轻量级
- 不必陷入内核,保存的上下文内容也更少,受益于函数调用的 ABI
- I/O 部分
- 线程在阻塞时会有 OS 调度
于是有了 Goroutine → 概念上是线程,实际是线程和协程的混合体
- 每个 CPU 上有一个 Go Worker,自由调度 goroutines
- 执行到 blocking API 时,例如 sleep, read
- Go Worker 偷偷改成 non-blocking 的版本
- 成功 → 立即继续执行
- 失败 → 立即 yield 到另一个需要 CPU 的 goroutine
- Go Worker 偷偷改成 non-blocking 的版本
https://books.studygolang.com/gopl-zh/ch9/ch9-08.html
另外,Go 语言还为生产者 - 消费者模式提供了 API
人机交互
Web 2.0 时代
使用单线程 + 事件模型
异步事件模型
提供尽可能少但又足够的并发
- 一个线程、全局的事件队列、按序执行 (run-to-complete)
- 耗时的 API (Timer, Ajax, …) 调用会立即返回
为了避免 Callback hell,后来又有了 Promise 和 Async-Await,用流程图描述回调
注意 JavaScript 代码只负责描述 DOM Tree
至于渲染和网络请求是浏览器开发人员的事
并发 Bug 和应对
常见的并发 bug
死锁
死锁产生的四个必要条件
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
避免死锁
- AA-Deadlock
- 防御性编程
- ABBA-Deadlock
- Lock Ordering
lock-ordering.py给了一点信心
数据竞争
不同的线程同时访问同一段内存,且至少有一个是写
用互斥锁保护好共享数据
原子性/顺序违反
回顾我们实现并发控制的工具
- 互斥锁 (lock/unlock) - 原子性
忘记上锁——原子性违反 (Atomicity Violation, AV)
- 条件变量 (wait/signal) - 同步
忘记同步——顺序违反 (Order Violation, OV)
应对:检查、检查、检查
Lockdep: 运行时的死锁检查
为每一个锁确定唯一的 allocation site
如以行号作为依据
printf 输出后,记录所有观察到的上锁顺序,例如
检查是否存在
即一个图中是否有环
梦回 15-445 死锁检测
ThreadSanitizer: 运行时的数据竞争检查
为所有事件建立 happens-before 关系图
对于发生在不同线程且至少有一个是写的 x 事件和 y 事件
检查是否存在
即在时间偏序上,x 事件和 y 事件之间不可比
防御性编程
在程序中手动添加代码
下面有几个例子
1、变量有 typed annotation,然而编程语言并不能很好的记录这些信息
一些宏
#define CHECK_INT(x, cond) \ ({ panic_on(!((x) cond), "int check fail: " #x " " #cond); })#define CHECK_HEAP(ptr) \ ({ panic_on(!IN_RANGE((ptr), heap)); })然后检查
CHECK_INT(waitlist->count, >= 0);CHECK_INT(pid, < MAX_PROCS);CHECK_HEAP(ctx->rip); CHECK_HEAP(ctx->cr3);
2、检测栈溢出
Canary,即金丝雀,对一氧化碳非常敏感
用生命预警矿井下的瓦斯泄露
计算机系统中的 canary
牺牲一些内存单元,来预警 memory error 的发生
#define MAGIC 0x55555555#define BOTTOM (STK_SZ / sizeof(u32) - 1)struct stack { char data[STK_SZ]; };
void canary_init(struct stack *s) { u32 *ptr = (u32 *)s; for (int i = 0; i < CANARY_SZ; i++) ptr[BOTTOM - i] = ptr[i] = MAGIC;}
void canary_check(struct stack *s) { u32 *ptr = (u32 *)s; for (int i = 0; i < CANARY_SZ; i++) { panic_on(ptr[BOTTOM - i] != MAGIC, "underflow"); panic_on(ptr[i] != MAGIC, "overflow"); }}msvc 中 debug mode 的 guard/fence/canary
- 未初始化栈:
0xcccccccc - 未初始化堆:
0xcdcdcdcd - 对象头尾:
0xfdfdfdfd - 已回收内存:
0xdddddddd
验证
(b'\xcc' * 80).decode('gb2312')手持两把锟斤拷,口中疾呼烫烫烫
脚踏千朵屯屯屯,笑看万物锘锘锘
3、低配版 Lockdep
不必大费周章记录什么上锁顺序
统计当前的 spin count
如果超过某个明显不正常的数值就报告
int spin_cnt = 0;while (xchg(&locked, 1)) { if (spin_cnt++ > SPIN_LIMIT) { printf("Too many spin @ %s:%d\n", __FILE__, __LINE__); }}4、低配版 Sanitizer
检测 double-allocation 和 double-free
// allocationfor (int i = 0; (i + 1) * sizeof(u32) <= size; i++) { panic_on(((u32 *)ptr)[i] == MAGIC, "double-allocation"); arr[i] = MAGIC;}
// freefor (int i = 0; (i + 1) * sizeof(u32) <= alloc_size(ptr); i++) { panic_on(((u32 *)ptr)[i] == 0, "double-free"); arr[i] = 0;}于是 L1 大受启发
动态分析工具:Sanitizers
之前已经介绍过了
类似防御性编程,只不过不需要亲自动手把代码改得乱七八糟了……
操作系统的状态机模型
硬件和软件的桥梁
为了让计算机能运行任何我们的程序,一定存在软件/硬件的约定
CPU reset 后,处理器处于某个确定的状态
以 x86 Family 为例,此时寄存器 EIP 为 0x0000fff0
RTFM Volume 3A 9.1.1 Processor State After Reset
ffff0 通常是一条向 firmware 跳转的 jmp 指令
ROM 存储了厂商提供的 firmware,即固件
Firmware: BIOS vs. UEFI
- Legacy BIOS (Basic I/O System)
- UEFI (Unified Extensible Firmware Interface)
下面从 firmware 开始执行
Legacy BIOS 把第一个可引导设备的第一个扇区加载到物理内存的 7c00 位置
此时处理器处于 16-bit 模式
Talk is cheap. Show me the code. ——Linus Torvalds
编写一些脚本
#!/bin/bashqemu-system-x86_64 -S -s -serial none -nographic -machine accel=tcg -smp "" -drive format=raw,file=/home/vgalaxy/os-workbench-2022/kernel/build/kernel-x86_64-qemu &gdb -x kernel.gdbkernel.gdb 如下
target remote localhost:1234...可以这样调试 QEMU 模拟器
- 查看 CPU Reset 后的寄存器
info registers
- 查看
0x7c00内存的加载watch *0x7c00- 查看当前指令
x/i ($cs * 16 + $rip) - 打印内存
x/16xb 0x7c00
- 进入
0x7c00代码的执行b *0x7c00
加载完成 MBR 后,我们就从 0x7c00 处开始执行
也就是 abstract-machine/am/src/x86/qemu/boot/start.S 里面的汇编代码
其中会调用 abstract-machine/am/src/x86/qemu/boot/main.c 中的 load_kernel
void load_kernel(void) { Elf32_Ehdr *elf32 = (void *)0x8000; Elf64_Ehdr *elf64 = (void *)0x8000; int is_ap = boot_record()->is_ap;
if (!is_ap) { // load argument (string) to memory copy_from_disk((void *)MAINARG_ADDR, 1024, -1024); // load elf header to memory copy_from_disk(elf32, 4096, 0); if (elf32->e_machine == EM_X86_64) { load_elf64(elf64); } else { load_elf32(elf32); } } else { // everything should be loaded }
if (elf32->e_machine == EM_X86_64) { ((void(*)())(uint32_t)elf64->e_entry)(); } else { ((void(*)())(uint32_t)elf32->e_entry)(); }}
0x7c3f处为load_kernel
最终成功切换到 elf 文件的 entry 处执行
后面的细节见 http://jyywiki.cn/AbstractMachine/AM_Programs
操作系统的状态机模型
Firmware 和 boot loader 共同完成操作系统的加载
- 初始化全局变量和栈;分配堆区
- 为 main 函数传递参数
进入 C 代码之后
- 完全遵循 C 语言的形式语义
- 但有一些行为补充,即 AbstractMachine API
一个迷你操作系统 thread-os.c
可以通过修改 kernel/Makefile 来加载 thread-os.c
其中主要使用了 AM 中的 MPE 和 CTE
还有经典的进程控制块
typedef union task { struct { const char *name; union task *next; void (*entry)(void *); Context *context; }; uint8_t stack[8192];} Task;RTFSC
L0 已经大概分析了执行 make 后究竟发生了什么
另外,观察 AbstractMachine 程序编译过程的正确方法
make run mainargs=hello \ | grep -ve '^\(\#\|echo\|mkdir\|make\)' \ | sed "s#$AM_HOME#\$AM_HOME#g" \ | sed "s#$PWD#.#g" \ | vim -进入 vim 后
:set nowrap:%s/ /\r /g注意 sed 命令可以变换文本
在 AM 的 Makefile 里也运用了类似的技巧
html: cat Makefile | sed 's/^\([^#]\)/ \1/g' | markdown_py > Makefile.html.PHONY: html大概就是保留 #,然后其余部分缩进成为代码块
markdown_py 则为一个命令行工具
状态机模型的应用
状态机
理解我们的世界
宏观物理世界近似于 deterministic 的状态机
把物理世界建模成基本粒子的运动
让 Cellular automata 支持时间旅行和预测外来
Why philosophers should care about computational complexity, Ch. 10
理解编译器和现代 CPU
超标量/乱序执行处理器,允许在状态机上跳跃
#include <stdio.h>#include <time.h>
#define LOOP 1000000000ul
__attribute__((noinline)) void loop() { for (long i = 0; i < LOOP; i++) { asm volatile( "mov $1, %%rax;" "mov $1, %%rdi;" "mov $1, %%rsi;" "mov $1, %%rdx;" "mov $1, %%rcx;" "mov $1, %%r10;" "mov $1, %%r8;" "mov $1, %%r9;" :::"rax", "rdi", "rsi", "rdx", "rcx", "r10", "r8", "r9"); }}
int main() { clock_t st = clock(); loop(); clock_t ed = clock(); double inst = LOOP * (8 + 2) / 1000000000; double ips = inst / ((ed - st) * 1.0 / CLOCKS_PER_SEC); printf("%.2lfG instructions/s\n", ips);}CPU 如下
Intel(R) Core(TM) i7-10875H CPU @ 2.30GHz似乎有 16 个逻辑处理器
结果如下
temp$ gcc -O2 ./ilp-demo.c && ./a.out19.65G instructions/s查看状态机执行
info localsTime-Travel Debugging
只记录初始状态,和每条指令前后状态的 diff
record fullrecord stoprsirsrnsyscall 无法保证
Record & Replay
记录 deterministic 的指令的数量
记录 non-deterministic 的指令的效果
mmio, in, out, rdrand, rdtsc, interrupt…
一些工具
- QEMU
-icount shift=auto,rr=record,rrfile=replay.bin
- rr
sudo rr record /path/to/my/program --argssudo rr replay报错
[FATAL /home/roc/rr/rr/src/PerfCounters.cc:217:start_counter()] Unable to open performance counter with 'perf_event_open'; are hardware perf events available? See https://github.com/rr-debugger/rr/wiki/Will-rr-work-on-my-system采样状态机执行
隔一段时间暂停程序、观察状态机的执行
一些工具
- Linux Kernel perf
sudo perf stat ./a.outsudo perf record ./a.outsudo perf report只有部分信息
ICS Lab3
- 浏览器
<F12>
Performance
Model Checker/Verifier
任何 non-deterministic 的状态机都可以检查
更高效的 Model Checker 将相似状态合并
期中测验
简答题
现有如下代码:
int volatile sum = 0;
void do_sum() { int t;/* 1 */ t = sum;/* 2 */ t += 1;/* 3 */ sum = t;
/* 4 */ t = sum;/* 5 */ t += 1;/* 6 */ sum = t;
/* 7 */ t = sum;/* 8 */ t += 1;/* 9 */ sum = t;}有两个线程 T1 和 T2 均执行 do_sum 代码,共享 sum 变量
假设线程每次按 1, 2, 3, … 9 顺序执行一条语句,且读/写会立即在共享内存中生效
例如,若两个线程以如下顺序执行语句,即相当于 T1 执行完后再执行 T2
T1.1 T1.2 T1.3 T1.4 T1.5 T1.6 T1.7 T1.8 T1.9T2.1 T2.2 T2.3 T2.4 T2.5 T2.6 T2.7 T2.8 T2.9将得到 sum = 6,但这显然不是最小值
你需要给出使 sum 最小化的一个线程执行顺序
最小值为 ====,非常反直觉
线程执行顺序如下
T1.1T1.2T2.1 -> t = 0T2.2T1.3 -> sum = 1T1.4T1.5T1.6 -> sum = 2T2.3 -> sum = 1!T1.7 -> t = 1T1.8T2.4T2.5T2.6T2.7T2.8T2.9 -> sum = 3T1.9 -> sum = 2!尝试写一个程序
#include "thread-sync.h"#include "thread.h"
int volatile sum = 0;
void do_sum() { int t; /* 1 */ t = sum; /* 2 */ t += 1; /* 3 */ sum = t;
/* 4 */ t = sum; /* 5 */ t += 1; /* 6 */ sum = t;
/* 7 */ t = sum; /* 8 */ t += 1; /* 9 */ sum = t;}
int main() { create(do_sum); create(do_sum); join(); printf("%d\n", sum);}然而几乎不可能有上述执行顺序
concurrency$ while true; do ./a.out; done | head -n 500000 | sort | uniq -c 17 3 1 4 499982 6https://zhuanlan.zhihu.com/p/28023094
考虑使用 model checker
class Midterm: s, s1, s2 = 0, 0, 0
@thread def t1(self): self.s1 = self.s self.s1 += 1 self.s = self.s1
self.s1 = self.s self.s1 += 1 self.s = self.s1
self.s1 = self.s self.s1 += 1 self.s = self.s1
@thread def t2(self): self.s2 = self.s self.s2 += 1 self.s = self.s2
self.s2 = self.s self.s2 += 1 self.s = self.s2
self.s2 = self.s self.s2 += 1 self.s = self.s2
@marker def mark(self, state): if self.s == 2: return 'red'发现似乎一共有两种能够达到最小值的执行序列
考虑对称性
实际上,对于任意数量的线程和任意数量的如下序列
self.si = self.sself.si += 1self.s = self.si最小值都是 ,执行序列具有类似的特征
反直觉的根源 -> Verifying Sequential Consistency (VSC) is NP-Complete
给出若干线程的共享内存 load/store 序列,判定是否存在一个全局的读写顺序,使得线程总是读到最近写入的数值
证明 -> 划归到 3-SAT
TODO
编程题
假设我们需要对很多 x (x>0) 计算 f(x) 的和
每个 f(x) 都可能会计算较长的时间
你需要在 thread.h 和 thread-sync.h 的基础上实现不少于 4 个 worker 线程的并行处理:
- 所有待处理的 x 都是
int类型,从标准输入 (stdin) 读入直到输入结束 - 对每一个整数 x,都调用来自外部的
long f(int x);计算,这个函数是线程安全的 - 你的程序需要输出所有
f(x)的和,保证和不超过long的范围,并正常终止 - 你需要尽快处理来自 stdin 的输入
- 个别的
f(x)可能会消耗较长的时间,请确保此时在有待计算的 x 时其他线程不会被闲置
提交
$ curl http://jyywiki.cn/upload -F course=OS2022 -F module=Midterm -F token=XXX -F file=@XXX测试数据生成
$ for i in {1..10000}; do echo ${i} >> in; done写了两个版本
- 第一个版本套用条件变量万能模型,然后 TLE
一种思路,以线程池为中心,试图为每一个输入都创建一个线程,并且准备好参数信息,效率不高
另一种思路是,创建一些线程来读取输入,另一些线程来进行计算,使用缓冲区来传递参数信息,需要注意 EOF 之后的判断,运行速度可观,但是 OJ 报 TLE,不太合理
- 第二个版本直接
pthread_create如下的 entry 处理即可
利用了 feof 和 scanf 是线程安全的
void *foo(void *arg) { int x;
while (true) { // mutex_lock(&stream_lk); bool flag = (!feof(stdin) && scanf("%d", &x) == 1); // mutex_unlock(&stream_lk);
if (!flag) { break; }
long res = f(x); mutex_lock(&sum_lk); sum += res; mutex_unlock(&sum_lk); }
return NULL;}