TOC
Open TOC
Malloc Lab
how to work
mm.c
只允许修改这个文件
- mm_init
- mm_malloc
- mm_free
- mm_realloc
其中 mm_realloc 原型如下
void *mm_realloc(void *ptr, size_t size);- if ptr is NULL, the call is equivalent to
mm_malloc(size); - if size is equal to zero, the call is equivalent to
mm_free(ptr); - if ptr is not NULL, it must have been returned by an earlier call to mm_malloc or mm_realloc. The contents of the new block are the same as those of the old ptr block, up to the minimum of the old and new sizes. Everything else is uninitialized.
heap consistency checker
方便调试
memory system
memlib.c 模拟了一个内存系统
trace-driven driver program
mdriver.c 包含了如下头文件
#include "config.h"#include "fsecs.h"#include "memlib.h"#include "mm.h"其中 fsecs.c 包含了一些计时相关的函数
#include "fsecs.h"#include "fcyc.h"#include "clock.h"#include "ftimer.h"#include "config.h"fsecs.c 相当于一个汇总包装
preparation
首先编译出 mdriver
会报错 asm/errno.h: No such file or directory
STFW 可知需要 sudo apt-get install linux-libc-dev:i386
链接过程会警告
/usr/bin/ld: fcyc.o: warning: relocation in read-only section `.text'/usr/bin/ld: warning: creating DT_TEXTREL in a PIEPIE 为位置无关可执行文件
参考 https://docs.oracle.com/cd/E26926_01/html/E25910/chapter6-42444.html,DT_TEXTREL 表示一个或多个重定位项可能会要求修改非可写段,并且运行时链接程序可以相应地进行准备
然后了解一下 mdriver 的命令行参数
-t <tracedir>: Look for the default trace files in directory tracedir instead of the default directory defined in config.h.-f <tracefile>: Use one particular tracefile for testing instead of the default set of trace-files.-h: Print a summary of the command line arguments.-l: Run and measure libc malloc in addition to the student’s malloc package.-v: Verbose output. Print a performance breakdown for each tracefile in a compact table.-V: More verbose output. Prints additional diagnostic information as each trace file is processed. Useful during debugging for determining which trace file is causing your malloc package to fail.默认情况下,mdriver 会使用 config.h 定义的 trace 的路径和文件
#define TRACEDIR "./traces/"#define DEFAULT_TRACEFILES \ "amptjp-bal.rep", "cccp-bal.rep", "cp-decl-bal.rep", "expr-bal.rep", \ "coalescing-bal.rep", "random-bal.rep", "random2-bal.rep", \ "binary-bal.rep", "binary2-bal.rep", "realloc-bal.rep", \ "realloc2-bal.rep"从网上找到了 short-bal.rep 之外的 trace 文件,并置入 traces 文件夹中
然后我们运行 mdriver,naive 的实现会出现内存不足
于是需要重新实现 mm.c
note
不能定义复合数据结构,如数组、结构体、链表……
有些网上的实现似乎没有注意到这一点……
对齐要求为 8 字节
evaluation
- correctness
- performance
- Space utilization
- 为此需要减少内部碎片和外部碎片
- Throughput
- 在单位时间内完成尽可能多的请求
- Space utilization
公式如下:
其中:
textbook impl.
mm-implicit.c
format
隐式空闲链表
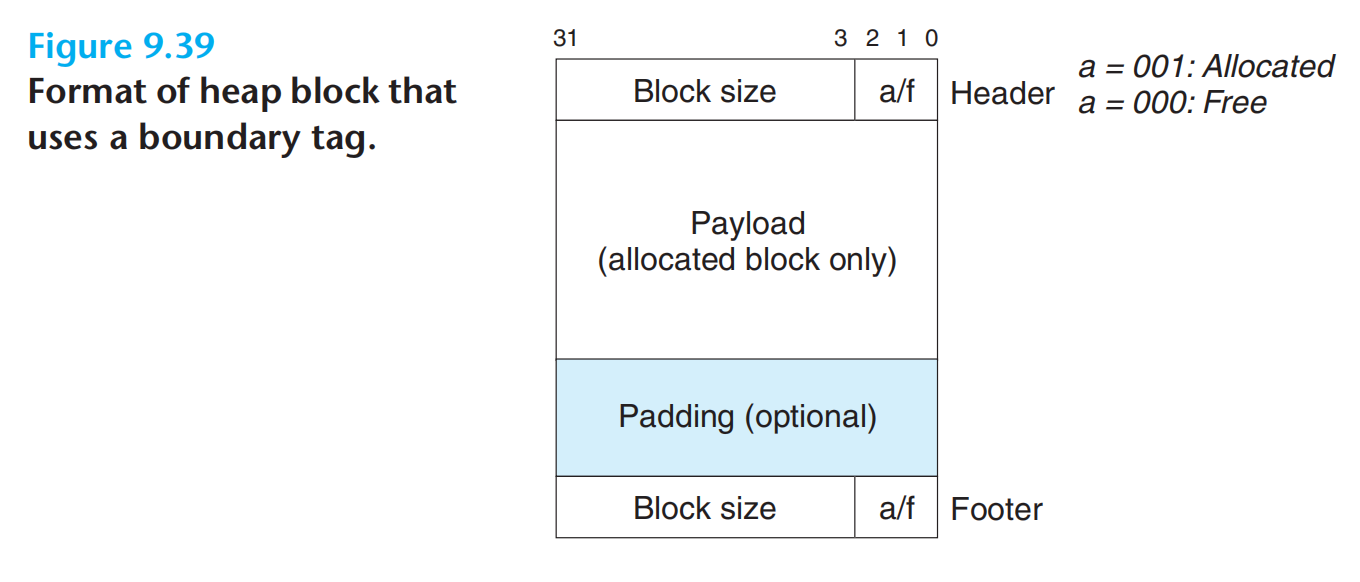
- 放置:首次适配
- 分割:在放置后
- 合并:立即合并、使用边界标记优化

note
注意 heap block 中存储的是块大小,而非有效载荷大小,而 malloc 和 realloc 的参数传递的是有效载荷大小,mm_realloc 中需要考虑这点不一致
目前 mm_realloc 完全基于 mm_malloc 和 mm_free 实现
checker
设计了 heap consistency checker 框架
- 在 mm_malloc 和 mm_free 的返回处检测 heap 的状态,并及时记录或报错
- 需要开启
DEBUG宏 - 若想输出更多信息,定义 verbose 为 1
score
trace valid util ops secs Kops 0 yes 99% 5694 0.008536 667 1 yes 99% 5848 0.007278 804 2 yes 99% 6648 0.011221 592 3 yes 100% 5380 0.010260 524 4 yes 99% 14400 0.000071203390 5 yes 92% 4800 0.011385 422 6 yes 92% 4800 0.010412 461 7 yes 55% 12000 0.127388 94 8 yes 51% 24000 0.227408 106 9 yes 27% 14401 0.033569 42910 yes 45% 14401 0.002385 6039Total 78% 112372 0.449912 250
Perf index = 47 (util) + 17 (thru) = 63/100next_fit
定义 NEXT_FIT 宏代表放置策略为下一次适配,否则为首次适配
我们定义 prev_fit_block 表示上一次适配的块
在 next_fit 的实现中,为简化判断,当遇到两次 epilogue block 时则退出循环,由于测试的结果 thru 已经是满分,所以不必继续优化
可能是 lab 久远的缘故,CPU 性能的提升使得 libc 参考得出的 thru 数值相对偏低
同时,为了防止合并块导致 prev_fit_block 失效,我们在 coalesce 中对合并 prev_fit_block 的情形进行特判,不进行合并
最终结果如下
trace valid util ops secs Kops 0 yes 90% 5694 0.002882 1975 1 yes 91% 5848 0.001544 3789 2 yes 94% 6648 0.006076 1094 3 yes 97% 5380 0.005285 1018 4 yes 40% 14400 0.000065220183 5 yes 91% 4800 0.007309 657 6 yes 89% 4800 0.006607 726 7 yes 55% 12000 0.019197 625 8 yes 51% 24000 0.010161 2362 9 yes 27% 14401 0.035116 41010 yes 45% 14401 0.002452 5874Total 70% 112372 0.096695 1162
Perf index = 42 (util) + 40 (thru) = 82/100buddy system
参考:
- https://coolshell.cn/articles/10427.html
- https://blog.codingnow.com/2011/12/buddy_memory_allocation.html
- https://github.com/wuwenbin/buddy2
但似乎无法动态调整管理内存的大小
故放弃
segregated fits
mm-segregated.c
参考了两篇文章,主要是第一篇:
format
- 对于分配块,format 不变
- 对于空闲块,在 payload 处依次添加 succ 和 pred 指针,形成显式空闲链表
- 在堆的起始位置添加 9 个显式空闲链表的头结点,只有 succ 指针,初始为 0
- 对应的大小类如下
- 放置:首次适配
- 合并:立即合并、使用边界标记优化
note
- 仍然是连续的扩展堆,只是当更改块的分配状态或扩展堆时,需要对指针进行修改
- 更改块的分配状态 → place / split / coalesce / free
- 扩展堆 → extend_heap
- 修改指针 → add_block / delete_block
- add_block 将空闲块加入显式空闲链表
- delete_block 将分配块移出显式空闲链表
- 分析一下指针操作
#define PRED(bp) ((char *)(bp) + WSIZE)#define SUCC(bp) ((char *)(bp))
#define PRED_BLKP(bp) (GET(PRED(bp)))#define SUCC_BLKP(bp) (GET(SUCC(bp)))
static void delete_block(void *bp) { PUT(SUCC(PRED_BLKP(bp)), SUCC_BLKP(bp)); if (SUCC_BLKP(bp) != 0) PUT(PRED(SUCC_BLKP(bp)), PRED_BLKP(bp));}这里的显式空闲链表为带头结点的双向链表,考虑删除操作
注意 PUT 修改对指针所指向的值,分析第一行:
- 第一个参数是地址,所以我们要用 SUCC 获得 bp 前驱块放置后继块的地址
- 第二个参数是值,所以我们要用 SUCC_BLKP 获得 bp 后继块的地址,实际上要解引用 bp 放置后继块的地址
由于指针和指针所指向的地址在语义上都是地址,所以极易混淆
optimization
- 通过分离适配,减少适配时间,同时改善内存利用率
- 尝试优化 mm_realloc
- 先尝试与周围的空闲块合并,由于自身目前并非是空闲块,所以在合并后需要设置分配位
- 并在 realloc 的大小较小时直接复用,并进一步考虑分割
- 显式空闲链表的排序策略
- LIFO 顺序 → 在 realloc 的用例中表现良好
- 地址顺序 → 在无 realloc 的用例中表现良好
- 于是引入 has_realloc,不过只优化了 1 分
- 进一步的优化需要分析用例制定策略,可以参考第二篇文章,我就鸽了吧
实在不想再调试了……
score
trace valid util ops secs Kops 0 yes 99% 5694 0.000112 50885 1 yes 99% 5848 0.000106 55326 2 yes 99% 6648 0.000138 48035 3 yes 100% 5380 0.000114 47318 4 yes 99% 14400 0.000119121008 5 yes 93% 4800 0.001643 2921 6 yes 91% 4800 0.001236 3882 7 yes 55% 12000 0.012089 993 8 yes 51% 24000 0.038126 629 9 yes 47% 14401 0.009066 158810 yes 45% 14401 0.002261 6369Total 80% 112372 0.065010 1729
Perf index = 48 (util) + 40 (thru) = 88/100summary
pointer
关键,重中之重
考虑到指针的左值和右值,所以我们常常使用一个局部变量拷贝参数中的指针,防止通过左值改写指针参数所指向的内容
使用 char * 对指针进行字节级别的移动,但 void * 指针本身移动就是字节级别,不太理解这一步强制类型转换
portability
由于是 32 位程序,在 64 位系统上操作指针就可能会有 warning
例程中使用 unsigned int * 进行 GET 和 PUT,可移植性似乎不太行
design
mm-implicit.c
虽然分数不高,但是简洁优雅,时序清晰
mm-segregated.c
由于对块的 visit 有两种方式,即顺序和链式,而通过一种方式修改块的数据结构,又可能会影响另一种方式下的数据结构,从而产生了耦合
另外,由于优化引入的复杂性,在某些时刻,链式下的块可能并不满足大小类的要求,这给两方面带来了挑战:
- 程序的语义不再清晰
- 调试会更加困难
另外是对 checker 的粒度的思考,考虑如下的层次结构
- heap level
- block level
- list level
通过 verbose 和宏进行控制 checker
- 一种方式是在代码中使用
#ifdef ... #endif的语法,包裹住 checker - 另一种方式则直接使用 checker 提供的函数,在开头根据宏统一分派语义,参考 segregated fits 的第二篇文章
#define DEBUG
#ifdef DEBUG# define DBG_PRINTF(...) printf(__VA_ARGS__)# define CHECKHEAP(verbose) mm_checkheap(verbose)#else# define DBG_PRINTF(...)# define CHECKHEAP(verbose)#endif