TOC
Open TOC
ICS PA 2
框架更新
参阅 GNU diff format:
--- src/cpu/cpu-exec.c+++ src/cpu/cpu-exec.c@@ -19,13 +19,15 @@ const rtlreg_t rzero = 0; rtlreg_t tmp_reg[4];
void device_update();+void fetch_decode(Decode *s, vaddr_t pc);
-#ifdef CONFIG_DEBUG-static void debug_hook(vaddr_t pc, const char *asmbuf) {- log_write("%s\n", asmbuf);- if (g_print_step) { puts(asmbuf); }-}+static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {+#ifdef CONFIG_ITRACE_COND+ if (ITRACE_COND) log_write("%s\n", _this->logbuf); #endif+ if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); }+ IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));+}
#include <isa-exec.h>备份 src/cpu/cpu-exec.c 前 35 行:
#include <cpu/difftest.h>#include <isa-all-instr.h>#include <locale.h>
/* The assembly code of instructions executed is only output to the screen * when the number of instructions executed is less than this value. * This is useful when you use the `si' command. * You can modify this value as you want. */#define MAX_INSTR_TO_PRINT 10
CPU_state cpu = {};uint64_t g_nr_guest_instr = 0;static uint64_t g_timer = 0; // unit: usstatic bool g_print_step = false;const rtlreg_t rzero = 0;rtlreg_t tmp_reg[4];
void device_update();
//bool check_wp();
#ifdef CONFIG_DEBUGstatic void debug_hook(vaddr_t pc, const char *asmbuf) { log_write("%s\n", asmbuf); if (g_print_step) { puts(asmbuf); } if(check_wp()&&nemu_state.state!=NEMU_ABORT&&nemu_state.state!=NEMU_END) nemu_state.state=NEMU_STOP;}#endif
#include <isa-exec.h>修改为:
#include <isa-all-instr.h>#include <locale.h>
/* The assembly code of instructions executed is only output to the screen * when the number of instructions executed is less than this value. * This is useful when you use the `si' command. * You can modify this value as you want. */#define MAX_INSTR_TO_PRINT 10
CPU_state cpu = {};uint64_t g_nr_guest_instr = 0;static uint64_t g_timer = 0; // unit: usstatic bool g_print_step = false;const rtlreg_t rzero = 0;rtlreg_t tmp_reg[4];
void device_update();void fetch_decode(Decode *s, vaddr_t pc);
//bool check_wp();
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {#ifdef CONFIG_ITRACE_COND if (ITRACE_COND) log_write("%s\n", _this->logbuf);#endif if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); } IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
if(check_wp()&&nemu_state.state!=NEMU_ABORT&&nemu_state.state!=NEMU_END) nemu_state.state=NEMU_STOP;}
#include <isa-exec.h>框架更新后才进行了分支整理(有点害怕)。
YEMU
- 取指
- 译码
- 执行
- 更新 PC
RISC vs. CISC
对立统一
https://cs.stanford.edu/people/eroberts/courses/soco/projects/risc/risccisc/
RTFSC - NEMU
取指
int isa_fetch_decode(Decode *s) { s->isa.instr.val = instr_fetch(&s->snpc, 4); int idx = table_main(s); return idx;}isa_fetch_decode 中的 instr_fetch 函数,本质上就是读内存。
调用链:instr_fetch -> vaddr_ifetch -> paddr_read -> pmem_read -> host_read
其中 paddr_read 拦截客户程序访存越界的非法行为:
word_t paddr_read(paddr_t addr, int len) { if (likely(in_pmem(addr))) return pmem_read(addr, len); MUXDEF(CONFIG_DEVICE, return mmio_read(addr, len), panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", " FMT_PADDR ") at pc = " FMT_WORD, addr, CONFIG_MBASE, CONFIG_MBASE + CONFIG_MSIZE, cpu.pc));}译码
这里涉及了很多宏,修改 Makefile 展开后分析。
从 table_main 入口出发(主表):
static inline int table_main(Decode *s) { do { uint32_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 00000 11", (sizeof("??????? ????? ????? ??? ????? 00000 11") - 1), &key, &mask, &shift); if (((get_instr(s) >> shift) & mask) == key) { { decode_I(s, 0); return table_load(s); }; } } while (0); do { uint32_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 01000 11", (sizeof("??????? ????? ????? ??? ????? 01000 11") - 1), &key, &mask, &shift); if (((get_instr(s) >> shift) & mask) == key) { { decode_S(s, 0); return table_store(s); }; } } while (0); do { uint32_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 01101 11", (sizeof("??????? ????? ????? ??? ????? 01101 11") - 1), &key, &mask, &shift); if (((get_instr(s) >> shift) & mask) == key) { { decode_U(s, 0); return table_lui(s); }; } } while (0); do { uint32_t key, mask, shift; pattern_decode("??????? ????? ????? ??? ????? 11010 11", (sizeof("??????? ????? ????? ??? ????? 11010 11") - 1), &key, &mask, &shift); if (((get_instr(s) >> shift) & mask) == key) { { decode_empty(s, 0); return table_nemu_trap(s); }; } } while (0); return table_inv(s);};pattern_decode 解析指令(一个宏,展开后长度十分唬人),即模式字符串。
目前有四种可能:
def_THelper(main) { def_INSTR_IDTAB("??????? ????? ????? ??? ????? 00000 11", I , load); def_INSTR_IDTAB("??????? ????? ????? ??? ????? 01000 11", S , store); def_INSTR_IDTAB("??????? ????? ????? ??? ????? 01101 11", U , lui); def_INSTR_TAB ("??????? ????? ????? ??? ????? 11010 11", nemu_trap); return table_inv(s);};模式字符串中只允许出现 4 种字符:
0表示相应的位只能匹配01表示相应的位只能匹配1?表示相应的位可以匹配0或1- (空格) 是分隔符,只用于提升模式字符串的可读性,不参与匹配
最终得到 key、mask 和 shift。其中 key 抽取了模式字符串中的 0 和 1,mask 表示 key 的掩码,而 shift 则表示 opcode 距离最低位的比特数量,用于帮助编译器进行优化。
若 if 语句满足条件,即符合指令编码。以第一种为例,首先调用 decode_I 函数:
static void decode_I(Decode *s, int width) { decode_op_r(s, (&s->src1), s->isa.instr.i.rs1, 0); decode_op_i(s, (&s->src2), s->isa.instr.i.simm11_0, 0); decode_op_r(s, (&s->dest), s->isa.instr.i.rd, 1);}decode_I 为 译码辅助函数。此处又调用了 译码操作数辅助函数,将指令中操作数信息存入 Decode 类型的指针 s 中。
接着进入 table_load(子表):
static inline int table_load(Decode *s) { do { uint32_t key, mask, shift; pattern_decode("??????? ????? ????? 010 ????? ????? ??", (sizeof("??????? ????? ????? 010 ????? ????? ??") - 1), &key, &mask, &shift); if (((get_instr(s) >> shift) & mask) == key) { { decode_empty(s, 0); return table_lw(s); }; } } while (0); return EXEC_ID_inv;}若匹配 funct3 字段,decode_empty 什么都不做:
static inline void decode_empty(Decode *s, int width) {}然后 table_lw 则返回指令的唯一标识:
static inline int table_lw(Decode *s) { return EXEC_ID_lw; }其余同理分析。
如果所有模式匹配规则都无法成功匹配,代码将会返回一个标识非法指令的 ID,即 EXEC_ID_inv。
碎碎念:
- 变长指令
- 立即数
- 字节序
执行
译码过程结束之后,接下来会返回到 fetch_decode() 中,并通过返回的 ID 来从 g_exec_table 数组中选择相应的 执行辅助函数,然后记录到 s->EHelper 中:
void fetch_decode(Decode *s, vaddr_t pc) { s->pc = pc; s->snpc = pc; int idx = isa_fetch_decode(s); s->dnpc = s->snpc; s->EHelper = g_exec_table[idx]; ...返回到 fetch_decode_exec_updatepc() 后,代码将会调用刚才记录的 执行辅助函数:
static void fetch_decode_exec_updatepc(Decode *s) { fetch_decode(s, cpu.pc); s->EHelper(s); cpu.pc = s->dnpc;}每个 执行辅助函数 都需要有一个标识该指令的 ID(译码中得到)以及一个 表格辅助函数(译码过程)与之相对应,这一点是通过一系列宏定义来实现的。
#define INSTR_LIST(f) f(lui) f(lw) f(sw) f(inv) f(nemu_trap)利用如下信息进行展开:
// `INSTR_LIST` is defined at src/isa/$ISA/include/isa-all-instr.h#define def_EXEC_ID(name) concat(EXEC_ID_, name),#define def_all_EXEC_ID() enum { MAP(INSTR_LIST, def_EXEC_ID) TOTAL_INSTR }得到结果:
enum { EXEC_ID_lui, EXEC_ID_lw, EXEC_ID_sw, EXEC_ID_inv, EXEC_ID_nemu_trap, TOTAL_INSTR }这便是标识 ID。
对于 表格辅助函数,是由宏 def_all_THelper() 来定义的,它会为每条指令定义一个 表格辅助函数,用于返回相应的 ID。
// --- prototype of table helpers ---#define def_THelper(name) static inline int concat(table_, name) (Decode *s)#define def_THelper_body(name) def_THelper(name) { return concat(EXEC_ID_, name); }#define def_all_THelper() MAP(INSTR_LIST, def_THelper_body)对所有的 执行辅助函数,我们定义了 g_exec_table:
#define FILL_EXEC_TABLE(name) [concat(EXEC_ID_, name)] = concat(exec_, name),static const void* g_exec_table[TOTAL_INSTR] = { MAP(INSTR_LIST, FILL_EXEC_TABLE)};宏展开后就像这样:
static inline void exec_lui(Decode *s) { rtl_li(s, ((&s->dest)->preg), (&s->src1)->imm);}
static inline void exec_lw(Decode *s) { rtl_lm(s, ((&s->dest)->preg), ((&s->src1)->preg), (&s->src2)->imm, 4);}
static inline void exec_sw(Decode *s) { rtl_sm(s, ((&s->dest)->preg), ((&s->src1)->preg), (&s->src2)->imm, 4);}
static inline void exec_inv(Decode *s) { rtl_hostcall(s, HOSTCALL_INV, ((void *)0), ((void *)0), ((void *)0), 0);}
static inline void exec_nemu_trap(Decode *s) { rtl_hostcall(s, HOSTCALL_EXIT, ((void *)0), &(cpu.gpr[check_reg_idx(10)]._32), ((void *)0), 0);}
static const void *g_exec_table[TOTAL_INSTR] = { [EXEC_ID_lui] = exec_lui, [EXEC_ID_lw] = exec_lw, [EXEC_ID_sw] = exec_sw, [EXEC_ID_inv] = exec_inv, [EXEC_ID_nemu_trap] = exec_nemu_trap,};执行辅助函数 通过 RTL 指令来描述指令真正的执行功能。
因此,我们只需要维护 nemu/src/isa/$ISA/include/isa-all-instr.h 中的指令列表(INSTR_LIST),就可以正确维护 执行辅助函数 和译码之间的关系了!
更新 PC
即 fetch_decode_exec_updatepc 的最后一行:
static void fetch_decode_exec_updatepc(Decode *s) { fetch_decode(s, cpu.pc); s->EHelper(s); cpu.pc = s->dnpc;}我们来分析 PC 的变化:
void fetch_decode(Decode *s, vaddr_t pc) { s->pc = pc; s->snpc = pc; int idx = isa_fetch_decode(s); s->dnpc = s->snpc; s->EHelper = g_exec_table[idx]; ...首先 snpc 被赋为 pc,instr_fetch 中将 snpc 加 4,isa_fetch_decode 结束后,dnpc 被赋为 snpc,最后在 fetch_decode_exec_updatepc 中将 cpu.pc 赋为 dnpc。
s->pc = pc 有啥用?
要区分 snpc 和 dnpc,例如:
100: jmp 102101: add102: xorjmp 指令的下一条静态指令是 add 指令,而下一条动态指令则是 xor 指令。
可以预见在 执行辅助函数 中维护了 s->dnpc。
RTL
寄存器
RTL 寄存器统一使用 rtlreg_t 来定义。
typedef MUXDEF(CONFIG_ISA64, uint64_t, uint32_t) word_t;
typedef word_t rtlreg_t;在 NEMU 中,RTL 寄存器只有以下这些:
- 不同 ISA 的通用寄存器(isa-def.h)
typedef struct { struct { rtlreg_t _32; } gpr[32];
vaddr_t pc;} riscv32_CPU_state;- 临时寄存器
s0, s1, s2和t0,零寄存器rz(rtl.h)
#define s0 (&tmp_reg[0])#define s1 (&tmp_reg[1])#define s2 (&tmp_reg[2])#define t0 (&tmp_reg[3])#define rz (&rzero)指令
在 NEMU 中,RTL 指令有两种:
- RTL 基本指令(rtl-basic.h)
c_op.h 中:
#define def_rtl(name, ...) void concat(rtl_, name)(Decode *s, __VA_ARGS__)rtl-basic.h 中:
#define def_rtl_compute_reg(name) \ static inline def_rtl(name, rtlreg_t* dest, const rtlreg_t* src1, const rtlreg_t* src2) { \ *dest = concat(c_, name) (*src1, *src2); \ }
#define def_rtl_compute_imm(name) \ static inline def_rtl(name ## i, rtlreg_t* dest, const rtlreg_t* src1, const sword_t imm) { \ *dest = concat(c_, name) (*src1, imm); \ }
#define def_rtl_compute_reg_imm(name) \ def_rtl_compute_reg(name) \ def_rtl_compute_imm(name) \以 add 为例:
def_rtl_compute_reg_imm(add)从而定义了 rtl_add 和 rtl_addi,其中调用了 c_add,定义在 c_op.h 中:
#define c_add(a, b) ((a) + (b))rtl-basic.h 中还有一些 RTL 基本指令调用了 c_op.h 中的 interpret_relop 函数:
static inline def_rtl(setrelop, uint32_t relop, rtlreg_t *dest, const rtlreg_t *src1, const rtlreg_t *src2) { *dest = interpret_relop(relop, *src1, *src2);}
static inline def_rtl(setrelopi, uint32_t relop, rtlreg_t *dest, const rtlreg_t *src1, sword_t imm) { *dest = interpret_relop(relop, *src1, imm);}- RTL 伪指令(pseudo.h):它们是通过 RTL 基本指令或者已经实现的 RTL 伪指令来实现的,riscv32 只有 ISA 无关的 RTL 伪指令
static inline def_rtl(li, rtlreg_t* dest, const rtlreg_t imm) { rtl_addi(s, dest, rz, imm);}
static inline def_rtl(mv, rtlreg_t* dest, const rtlreg_t *src1) { rtl_addi(s, dest, src1, 0);}RTL 基本指令不需要使用 RTL 临时寄存器。但某些 RTL 伪指令需要使用临时寄存器存放中间结果,才能实现其完整功能,所以我们需要小型调用约定。
计算机系统工作的一种基本原则——遵守约定:
- 只要遵守约定,就能保证程序具有遵守约定后的特性
- 如果违反,不按照说好的来,那就不保证行为是正确的,即未定义行为 (UB, Undefined Behavior)
PS:
- RTL 寄存器中值的生存期:根据生存期给 RTL 寄存器分类。
- 为了提高性能,我们在
Operand结构体中定义了一个 RTL 寄存器的指针preg,用于直接指向那些已经存在的 RTL 寄存器。
如此,我们就可以实现 执行辅助函数 了,如在 compute.h 中:
def_EHelper(lui) { rtl_li(s, ddest, id_src1->imm);}isa-exec.h 收集了这些头文件:
#include "../instr/compute.h"#include "../instr/ldst.h"#include "../instr/special.h"实现新指令
- 在
nemu/src/isa/$ISA/instr/decode.c中添加正确的模式匹配规则 - 用 RTL 实现正确的执行辅助函数
- 在
nemu/src/isa/$ISA/include/isa-all-instr.h中把指令添加到INSTR_LIST中 - 必要时在
nemu/src/isa/$ISA/include/isa-exec.h中添加相应的头文件
运行第一个程序
子项目 am-kernels 编译 C 程序 dummy,并启动 NEMU 运行它:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests$ make ARCH=riscv32-nemu ALL=dummy run其反汇编结果位于 am-kernels/tests/cpu-tests/build/dummy-riscv32-nemu.txt 中
我们也可以使用交叉编译工具链 riscv64-linux-gnu-objdump 对生成的.o 文件进行反汇编:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build/riscv32-nemu/tests$ riscv64-linux-gnu-objdump -d dummy.o
dummy.o: file format elf32-littleriscv
Disassembly of section .text.startup.main:
00000000 <main>: 0: 00000513 li a0,0 4: 00008067 ret似乎不太全…
Disassembly of section .text:
80000000 <_start>:80000000: 00000413 li s0,080000004: 00009117 auipc sp,0x980000008: ffc10113 addi sp,sp,-4 # 80009000 <_end>8000000c: 00c000ef jal ra,80000018 <_trm_init>
80000010 <main>:80000010: 00000513 li a0,080000014: 00008067 ret
80000018 <_trm_init>:80000018: 80000537 lui a0,0x800008000001c: ff010113 addi sp,sp,-1680000020: 03850513 addi a0,a0,56 # 80000038 <_end+0xffff7038>80000024: 00112623 sw ra,12(sp)80000028: fe9ff0ef jal ra,80000010 <main>8000002c: 00050513 mv a0,a080000030: 0000006b 0x6b80000034: 0000006f j 80000034 <_trm_init+0x1c>得到镜像文件后,我们可以使用 PA1 中的简易调试器进行调试:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/nemu$ ./build/riscv32-nemu-interpreter --log=/home/vgalaxy/ics2021/nemu/build/nemu-log.txt ../am-kernels/tests/cpu-tests/build/dummy-riscv32-nemu.bin或者使用 gdb 调试:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/nemu$ gdb ./build/riscv32-nemu-interpreter然后在 run 时带上参数:
(gdb) run --log=/home/vgalaxy/ics2021/nemu/build/nemu-log.txt ../am-kernels/tests/cpu-tests/build/dummy-riscv32-nemu.bin记得及时 make 更新可执行文件
li
li rd, immediatex[rd] = immediate在 RV32I 中与 lui 等价,是伪指令。
编码:
def_INSTR_IDTAB("??????? ????? ????? ??? ????? 00100 11", U , li);辅助函数:
def_EHelper(li) { rtl_li(s, ddest, id_src1->imm);}麻了,被编译器骗到了,实际上就是 addi,所以上面的都不需要
auipc
auipc rd, immediatex[rd] = pc + sext(immediate[31:12] << 12)U-type:
static def_DHelper(U) { decode_op_i(s, id_src1, s->isa.instr.u.imm31_12 << 12, true); decode_op_r(s, id_dest, s->isa.instr.u.rd, true);}编码:
def_INSTR_IDTAB("??????? ????? ????? ??? ????? 00101 11", U , auipc);辅助函数:
def_EHelper(auipc) { rtl_addi(s, ddest, &s->pc, id_src1->imm);}调试发现此时 sp 寄存器的值为 0x80009004。
PC 的旧值还是加上 4 之后的值?
addi
addi rd, rs1, immediatex[rd] = x[rs1] + sext(immediate)I-type:
static void decode_I(Decode *s, int width) { decode_op_r(s, (&s->src1), s->isa.instr.i.rs1, 0); decode_op_i(s, (&s->src2), s->isa.instr.i.simm11_0, 0); decode_op_r(s, (&s->dest), s->isa.instr.i.rd, 1);}辅助函数,注意立即数在 src2 中:
def_EHelper(addi) { rtl_addi(s, ddest, dsrc1, id_src2->imm);}编码:
def_THelper(rii) { def_INSTR_TAB("??????? ????? ????? 000 ????? ????? ??", addi); return EXEC_ID_inv;}
def_THelper(main) { ... def_INSTR_IDTAB("??????? ????? ????? ??? ????? 00100 11", I , rii); // register-immediate instructions调试发现此时 sp 寄存器的值为 0x80009000。
j
伪指令,等同于 jal x0, offset。
jal
jal rd, offsetx[rd] = pc+4; pc += sext(offset)以前是 J-type,U-type 衍生,不过现在似乎又变回了 U-type,我们还是使用 J-type 格式吧。
Preface to Version 2.0 ?
编码:
def_INSTR_IDTAB("??????? ????? ????? ??? ????? 11011 11", J , jal);修改 decode.c:
static def_DHelper(J) { word_t simm = (s->isa.instr.j.simm20 << 20) | (s->isa.instr.j.imm10_1 << 1) | (s->isa.instr.j.imm11 << 11) | (s->isa.instr.j.imm19_12 << 12); decode_op_i(s, id_src1, simm, true); decode_op_r(s, id_dest, s->isa.instr.j.rd, true);}注意符号扩展,最高位使用有符号数!
修改 isa-def.h:
struct { uint32_t opcode1_0 : 2; uint32_t opcode6_2 : 5; uint32_t rd : 5; uint32_t imm19_12 : 8; uint32_t imm11 : 1; uint32_t imm10_1 :10; uint32_t simm20 : 1; } j;辅助函数,新建 control.h:
def_EHelper(jal) { rtl_addi(s, ddest, &s->pc, 4); rtl_li(s, &s->dnpc, id_src1->imm + s->pc);}注意这里修改的是 dnpc。
或考虑使用 RTL 基本指令:
调试发现此时 ra 寄存器的值为 0x80000010,即返回地址,而 pc 则变为了 0x80000018。
执行 sw 之后,可以发现返回地址被存入了 0x80008ffc 中:
(nemu) x 1 0x80008ffc0x80008ffc 80000010ret
伪指令,等同于 jalr x0, 0(x1)。寄存器 x1 也就是 ra,存放着返回地址。
jalr
jalr rd, offset(rs1)t=pc+4; pc=(x[rs1]+sext(offset))&~1; x[rd]=tI-type
辅助函数:
def_EHelper(jalr) { sword_t t = s->pc + 4; sword_t pc = (id_src2->imm + *dsrc1) & ~1; rtl_li(s, &s->dnpc, pc); rtl_li(s, ddest, t);}编码:
def_INSTR_IDTAB("??????? ????? ????? 000 ????? 11001 11", I , jalr);程序执行到 0x80000030 处的 nemu_trap 指令后即停止运行。下面是程序运行的结果:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000030[src/cpu/cpu-exec.c:55 statistic] host time spent = 52 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 13[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 250,000 instr/s运行时环境
为了运行最简单的程序,我们需要提供什么呢:
- 只要把程序放在正确的内存位置,然后让 PC 指向第一条指令,计算机就会自动执行这个程序,永不停止。
- 运行时环境需要向程序提供一种结束运行的方法。
不同的架构中结束运行的指令编码很有可能并不相同,若不进行抽象,为了让 n 个程序运行在 m 个架构上,我们需要维护 n*m 份代码。
所以,我们只需要定义一个结束程序的 API,比如 void halt(),然后让不同的架构分别实现自己的 halt(),就能让 n*m 变为 n+m。
这个例子也展示了运行时环境的一种普遍的存在方式:库。通过库,运行程序所需要的公共要素被抽象成 API,不同的架构只需要实现这些 API,也就相当于实现了支撑程序运行的运行时环境。
不同的程序对运行时环境的需求也是不同的。如果我们把这些需求都收集起来,将它们抽象成统一的 API 提供给程序,这样我们就得到了一个可以支撑各种程序运行在各种架构上的库了。
我们把这组 API 称为抽象计算机,即 AM。AM 根据程序的需求把库划分成以下模块:
AM = TRM + IOE + CTE + VME + MPE- TRM (Turing Machine) - 图灵机,最简单的运行时环境,为程序提供基本的计算能力
- IOE (I/O Extension) - 输入输出扩展,为程序提供输出输入的能力
- CTE (Context Extension) - 上下文扩展,为程序提供上下文管理的能力
- VME (Virtual Memory Extension) - 虚存扩展,为程序提供虚存管理的能力
- MPE (Multi-Processor Extension) - 多处理器扩展,为程序提供多处理器通信的能力
AM 项目的诞生,让 NEMU 和程序的界线更加泾渭分明:
(在 NEMU 中) 实现硬件功能 -> (在 AM 中) 提供运行时环境 -> (在 APP 层) 运行程序jyy yyds
思考:操作系统位于 AM 层还是 APP 层?操作系统提供的运行时环境和 AM 提供的运行时环境是一个概念吗?
RTFSC - AM
code
整个 AM 项目分为两大部分:
abstract-machine/am/- 不同架构的 AM API 实现。此外,abstract-machine/am/include/am.h列出了 AM 中的所有 APIabstract-machine/klib/- 一些架构无关的库函数,方便应用程序的开发
阅读 abstract-machine/am/src/platform/nemu/trm.c 中的代码,你会发现只需要实现很少的 API 就可以支撑起程序在 TRM 上运行了:
Area heap结构用于指示堆区的起始和末尾void putch(char ch)用于输出一个字符void halt(int code)用于结束程序的运行void _trm_init()用于进行 TRM 相关的初始化工作
这里主要分析 halt 函数:
void halt(int code) { nemu_trap(code);
// should not reach here while (1);}nemu_trap 是一个宏:
#if defined(__ISA_X86__)# define nemu_trap(code) asm volatile (".byte 0xd6" : :"a"(code))#elif defined(__ISA_MIPS32__)# define nemu_trap(code) asm volatile ("move $v0, %0; .word 0xf0000000" : :"r"(code))#elif defined(__ISA_RISCV32__) || defined(__ISA_RISCV64__)# define nemu_trap(code) asm volatile("mv a0, %0; .word 0x0000006b" : :"r"(code))#elif# error unsupported ISA __ISA__#endif这个宏展开之后是一条内联汇编语句,与 ISA 相关。
注意此处的 volatile 关键字
我们关注 riscv32 的部分:
mv a0, %0; .word 0x0000006b将 a0 寄存器置 %0,即传入的 code 参数,对应之前的执行辅助函数:
def_EHelper(nemu_trap) { rtl_hostcall(s, HOSTCALL_EXIT, NULL, &gpr(10), NULL, 0); // gpr(10) is $a0}定位其宏的原始定义:
def_rtl(hostcall, uint32_t id, rtlreg_t *dest, const rtlreg_t *src1, const rtlreg_t *src2, word_t imm) { switch (id) { case HOSTCALL_EXIT: difftest_skip_ref(); set_nemu_state(NEMU_END, s->pc, *src1); break; case HOSTCALL_INV: invalid_instr(s->pc); break;#ifdef CONFIG_HAS_PORT_IO case HOSTCALL_PIO: { int width = imm & 0xf; bool is_in = ((imm & ~0xf) != 0); if (is_in) *dest = pio_read(*src1, width); else pio_write(*dest, width, *src1); break; }#endif default: panic("Unsupport hostcall ID = %d", id); break; }}src1 即 a0 寄存器,调用 set_nemu_state 函数,置 halt_ret 为 0,即 halt(0) 的 code:
void set_nemu_state(int state, vaddr_t pc, int halt_ret) { nemu_state.state = state; nemu_state.halt_pc = pc; nemu_state.halt_ret = halt_ret;}而 am-kernels 子项目用于收录一些可以在 AM 上运行的测试集和简单程序。
make
另外,我们需要在 GNU/Linux 下根据 AM 的运行时环境编译出能够在 $ISA-nemu 这个新环境中运行的可执行文件,因此我们不能使用 gcc 的默认选项直接编译。
编译生成一个可以在 NEMU 的运行时环境上运行的程序的过程大致如下:
- gcc 将
$ISA-nemu的 AM 实现源文件编译成目标文件,然后通过 ar 将这些目标文件作为一个库,打包成一个归档文件abstract-machine/am/build/am-$ISA-nemu.a - gcc 把应用程序源文件 (如
am-kernels/tests/cpu-tests/tests/dummy.c) 编译成目标文件 - 通过 gcc 和 ar 把程序依赖的运行库 (如
abstract-machine/klib/) 也编译并打包成归档文件 - 根据 Makefile 文件
abstract-machine/scripts/$ISA-nemu.mk中的指示,让 ld 根据链接脚本abstract-machine/scripts/linker.ld,将上述目标文件和归档文件链接成可执行文件
我们对编译得到的可执行文件的行为进行简单的梳理:
对应上面反汇编出的 dummy
- 第一条指令从
abstract-machine/am/src/$ISA/nemu/start.S开始,设置好栈顶之后就跳转到abstract-machine/am/src/platform/nemu/trm.c的_trm_init()函数处执行 - 在
_trm_init()中调用main()函数执行程序的主体功能 - 从
main()函数返回后,调用halt()结束运行
参考如下代码
_start: mv s0, zero la sp, _stack_pointer jal _trm_initvoid _trm_init() { int ret = main(mainargs); halt(ret);}main 在哪里?
运行更多的程序
除了 string 和 hello-str。
下面以 <h3> 加上无序列表列出程序名,<h4> 列出需要实现的指令。
add.c fib.c max.c quick-sort.c sum.cadd-longlong.c goldbach.c min3.c recursion.c switch.cbit.c hello-str.c mov-c.c select-sort.c to-lower-case.cbubble-sort.c if-else.c movsx.c shift.c unalign.cdiv.c leap-year.c mul-longlong.c shuixianhua.c wanshu.cdummy.c load-store.c pascal.c string.cfact.c matrix-mul.c prime.c sub-longlong.c-
add.c
反汇编结果:
Disassembly of section .text:
80000000 <_start>:80000000: 00000413 li s0,080000004: 00009117 auipc sp,0x980000008: ffc10113 addi sp,sp,-4 # 80009000 <_end>8000000c: 0fc000ef jal ra,80000108 <_trm_init>
80000010 <check>:80000010: 00050463 beqz a0,80000018 <check+0x8>80000014: 00008067 ret80000018: ff010113 addi sp,sp,-168000001c: 00100513 li a0,180000020: 00112623 sw ra,12(sp)80000024: 0d8000ef jal ra,800000fc <halt>
80000028 <main>:80000028: fd010113 addi sp,sp,-488000002c: 01312e23 sw s3,28(sp)80000030: 01412c23 sw s4,24(sp)80000034: 01512a23 sw s5,20(sp)80000038: 80000a37 lui s4,0x800008000003c: 80000ab7 lui s5,0x8000080000040: 800009b7 lui s3,0x8000080000044: 01612823 sw s6,16(sp)80000048: 01712623 sw s7,12(sp)8000004c: 01812423 sw s8,8(sp)80000050: 02112623 sw ra,44(sp)80000054: 22ca0c13 addi s8,s4,556 # 8000022c <_end+0xffff722c>80000058: 02812423 sw s0,40(sp)8000005c: 02912223 sw s1,36(sp)80000060: 03212023 sw s2,32(sp)80000064: 12ca8a93 addi s5,s5,300 # 8000012c <_end+0xffff712c>80000068: 22ca0a13 addi s4,s4,5568000006c: 00000b13 li s6,080000070: 24c98993 addi s3,s3,588 # 8000024c <_end+0xffff724c>80000074: 04000b93 li s7,6480000078: 000a2903 lw s2,0(s4)8000007c: 000a8493 mv s1,s580000080: 000c0413 mv s0,s880000084: 00042503 lw a0,0(s0)80000088: 0004a783 lw a5,0(s1)8000008c: 00440413 addi s0,s0,480000090: 00a90533 add a0,s2,a080000094: 40f50533 sub a0,a0,a580000098: 00153513 seqz a0,a08000009c: f75ff0ef jal ra,80000010 <check>800000a0: 00448493 addi s1,s1,4800000a4: fe8990e3 bne s3,s0,80000084 <main+0x5c>800000a8: 00100513 li a0,1800000ac: 008b0b13 addi s6,s6,8800000b0: f61ff0ef jal ra,80000010 <check>800000b4: 004a0a13 addi s4,s4,4800000b8: 020a8a93 addi s5,s5,32800000bc: fb7b1ee3 bne s6,s7,80000078 <main+0x50>800000c0: 00100513 li a0,1800000c4: f4dff0ef jal ra,80000010 <check>800000c8: 02c12083 lw ra,44(sp)800000cc: 02812403 lw s0,40(sp)800000d0: 02412483 lw s1,36(sp)800000d4: 02012903 lw s2,32(sp)800000d8: 01c12983 lw s3,28(sp)800000dc: 01812a03 lw s4,24(sp)800000e0: 01412a83 lw s5,20(sp)800000e4: 01012b03 lw s6,16(sp)800000e8: 00c12b83 lw s7,12(sp)800000ec: 00812c03 lw s8,8(sp)800000f0: 00000513 li a0,0800000f4: 03010113 addi sp,sp,48800000f8: 00008067 ret
800000fc <halt>:800000fc: 00050513 mv a0,a080000100: 0000006b 0x6b80000104: 0000006f j 80000104 <halt+0x8>
80000108 <_trm_init>:80000108: 80000537 lui a0,0x800008000010c: ff010113 addi sp,sp,-1680000110: 12850513 addi a0,a0,296 # 80000128 <_end+0xffff7128>80000114: 00112623 sw ra,12(sp)80000118: f11ff0ef jal ra,80000028 <main>8000011c: 00050513 mv a0,a080000120: 0000006b 0x6b80000124: 0000006f j 80000124 <_trm_init+0x1c>加法的结果若不对则返回 1,未执行掉所有循环也会返回 1:
int main() { int i, j, ans_idx = 0; for(i = 0; i < NR_DATA; i ++) { for(j = 0; j < NR_DATA; j ++) { check(add(test_data[i], test_data[j]) == ans[ans_idx ++]); } check(j == NR_DATA); }
check(i == NR_DATA);
return 0;}check 函数位于 trap.h 中:
__attribute__((noinline))void check(bool cond) { if (!cond) halt(1);}add & sub
add rd, rs1, rs2x[rd] = x[rs1] + x[rs2]R-type
编码:
static def_DHelper(R) { decode_op_r(s, id_src1, s->isa.instr.r.rs1, false); decode_op_r(s, id_src2, s->isa.instr.r.rs2, false); decode_op_r(s, id_dest, s->isa.instr.r.rd, true);}
def_THelper(rri) { def_INSTR_TAB("0000000 ????? ????? 000 ????? ????? ??", add); def_INSTR_TAB("0100000 ????? ????? 000 ????? ????? ??", sub); return EXEC_ID_inv;}
def_THelper(main) { ... def_INSTR_IDTAB("??????? ????? ????? ??? ????? 01100 11", R , rri); // register-register instructions修改 isa-def.h:
struct { uint32_t opcode1_0 : 2; uint32_t opcode6_2 : 5; uint32_t rd : 5; uint32_t funct3 : 3; uint32_t rs1 : 5; uint32_t rs2 : 5; uint32_t funct7 : 7; } r;辅助函数:
def_EHelper(add) { rtl_add(s, ddest, dsrc1, dsrc2);}
def_EHelper(sub) { rtl_sub(s, ddest, dsrc1, dsrc2);}seqz
seqz rd, rs1x[rd]=(x[rs1]==0)伪指令,实际被扩展为 sltiu rd, rs1, 1。
sltiu
sltiu rd, rs1, immediatex[rd]=(x[rs1]<𝑢 sext(immediate))I-type,rii 系
编码:
def_THelper(rii) { def_INSTR_TAB("??????? ????? ????? 000 ????? ????? ??", addi); def_INSTR_TAB("??????? ????? ????? 011 ????? ????? ??", sltiu); return EXEC_ID_inv;}辅助函数:
def_EHelper(sltiu) { rtl_setrelopi(s, RELOP_LTU, ddest, dsrc1, id_src2->imm);}此处利用了:
static inline def_rtl(setrelopi, uint32_t relop, rtlreg_t *dest, const rtlreg_t *src1, sword_t imm) { *dest = interpret_relop(relop, *src1, imm);}id_src2->imm 转换为有符号数,再进行无符号比较,符合指令语义:
static inline bool interpret_relop(uint32_t relop, const rtlreg_t src1, const rtlreg_t src2) { switch (relop) { case RELOP_FALSE: return false; case RELOP_TRUE: return true; case RELOP_EQ: return src1 == src2; case RELOP_NE: return src1 != src2; case RELOP_LT: return (sword_t)src1 < (sword_t)src2; case RELOP_LE: return (sword_t)src1 <= (sword_t)src2; case RELOP_GT: return (sword_t)src1 > (sword_t)src2; case RELOP_GE: return (sword_t)src1 >= (sword_t)src2; case RELOP_LTU: return src1 < src2; case RELOP_LEU: return src1 <= src2; case RELOP_GTU: return src1 > src2; case RELOP_GEU: return src1 >= src2; default: panic("unsupport relop = %d", relop); }}beqz
beqz rs1, offsetif (rs1 == 0) pc += sext(offset)伪指令,可视为 beq rs1, x0, offset。
beq & bne
beq rs1, rs2, offsetif (rs1 == rs2) pc += sext(offset)B-type,S-type 衍生
编码:
static def_DHelper(B) { decode_op_r(s, id_src1, s->isa.instr.b.rs1, false); sword_t simm = (s->isa.instr.b.simm12 << 12) | (s->isa.instr.b.imm4_1 << 1) | (s->isa.instr.b.imm10_5 << 5) | (s->isa.instr.b.imm11 << 11); decode_op_i(s, id_src2, simm, false); decode_op_r(s, id_dest, s->isa.instr.b.rs2, false);}
def_THelper(cbi) { def_INSTR_TAB("??????? ????? ????? 000 ????? ????? ??", beq); return EXEC_ID_inv;}
def_THelper(main) { ... def_INSTR_IDTAB("??????? ????? ????? ??? ????? 11000 11", B , cbi); // conditional-branch instructions修改 isa-def.h:
struct { uint32_t opcode1_0 : 2; uint32_t opcode6_2 : 5; uint32_t imm11 : 1; uint32_t imm4_1 : 4; uint32_t funct3 : 3; uint32_t rs1 : 5; uint32_t rs2 : 5; uint32_t imm10_5 : 6; int32_t simm12 : 1; } b;于是 6 种指令格式齐备
辅助函数:
def_EHelper(beq) { rtl_jrelop(s, RELOP_EQ, dsrc1, ddest, id_src2->imm + s->pc);}此处利用了:
static inline def_rtl(j, vaddr_t target) { s->dnpc = target;}
static inline def_rtl(jr, rtlreg_t *target) { s->dnpc = *target;}
static inline def_rtl(jrelop, uint32_t relop, const rtlreg_t *src1, const rtlreg_t *src2, vaddr_t target) { bool is_jmp = interpret_relop(relop, *src1, *src2); rtl_j(s, (is_jmp ? target : s->snpc));}bne 指令的实现同理。
上述指令实现后运行,可以发现 add.c 共执行了 840 条指令:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000120[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,331 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 840[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 631,104 instr/s-
fib.c
反汇编结果略。
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800000c4[src/cpu/cpu-exec.c:55 statistic] host time spent = 802 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 526[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 655,860 instr/s-
max.c
bge
B-type,cbi 系
实现略。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000124[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,417 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 868[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 612,561 instr/s-
quick-sort.c
slli & srli & srai
shamt 代表 shift amount,也就是立即数的低 5 位。
实现略,顺便实现了 srli 和 srai。
blt
B-type,cbi 系
实现略。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800003d0[src/cpu/cpu-exec.c:55 statistic] host time spent = 4,943 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 3,174[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 642,120 instr/s-
sum.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000009c[src/cpu/cpu-exec.c:55 statistic] host time spent = 935 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 528[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 564,705 instr/s-
add-longlong.c
sltu
R-type,rri 系
实现略。
xor & or & and
R-type,rri 系
实现略。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000138[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,902 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,262[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 663,512 instr/s-
goldbach.c
andi & xori & ori & slti
I-type,rii 系
rem
rem rd, rs1, rs2 x[rd]=x[rs1]% 𝑠 x[rs2]RV32M,整数乘法和除法的扩展。
R-type,rri 系
辅助函数利用了:
#define c_divu_q(a, b) ((a) / (b))#define c_divu_r(a, b) ((a) % (b))#define c_divs_q(a, b) ((sword_t)(a) / (sword_t)(b))#define c_divs_r(a, b) ((sword_t)(a) % (sword_t)(b))运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000118[src/cpu/cpu-exec.c:55 statistic] host time spent = 2,636 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,367[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 518,588 instr/s-
min3.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000170[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,601 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,042[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 650,843 instr/s-
recursion.c
blez
伪指令,等同于 bge x0, rs2, offset。
remu & div & divu
RV32M,R-type,rri 系
实现略。
jr
伪指令,等同于 jalr x0, 0(rs1)。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000026c[src/cpu/cpu-exec.c:55 statistic] host time spent = 6,938 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 4,545[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 655,087 instr/s-
switch.c
bltu & bgeu
B-type,cbi 系
实现略。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800000e4[src/cpu/cpu-exec.c:55 statistic] host time spent = 369 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 228[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 617,886 instr/s-
bit.c
lbu & lhu & lb & lh
lbu rd, offset(rs1)x[rd] = M[x[rs1] + sext(offset)][7:0]I-type,load 系
编码略。
辅助函数实现如下:
def_EHelper(lb) { rtl_lms(s, ddest, dsrc1, id_src2->imm, 1);}
def_EHelper(lh) { rtl_lms(s, ddest, dsrc1, id_src2->imm, 2);}
def_EHelper(lbu) { rtl_lm(s, ddest, dsrc1, id_src2->imm, 1);}
def_EHelper(lhu) { rtl_lm(s, ddest, dsrc1, id_src2->imm, 2);}其中利用了:
static inline def_rtl(lm, rtlreg_t *dest, const rtlreg_t* addr, word_t offset, int len) { *dest = vaddr_read(*addr + offset, len);}
static inline def_rtl(lms, rtlreg_t *dest, const rtlreg_t* addr, word_t offset, int len) { word_t val = vaddr_read(*addr + offset, len); switch (len) { case 4: *dest = (sword_t)(int32_t)val; return; case 1: *dest = (sword_t)( int8_t)val; return; case 2: *dest = (sword_t)(int16_t)val; return; IFDEF(CONFIG_ISA64, case 8: *dest = (sword_t)(int64_t)val; return); IFDEF(CONFIG_RT_CHECK, default: assert(0)); }}slt
R-type,rri 系
实现略。
sll & srl & sra
R-type,rri 系
实现略。
snez
伪指令,等同于 sltu rd, x0, rs2。
not
伪指令,等同于 xori rd, rs1, -1。
sb & sh
S-type,store 系
实现略。
zext.b
手动译码可知为 andi rd, rs1, 0xff。
bnez
伪指令,等同于 bne rs1, x0, offset。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000220[src/cpu/cpu-exec.c:55 statistic] host time spent = 579 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 314[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 542,314 instr/s-
mov-c.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000124[src/cpu/cpu-exec.c:55 statistic] host time spent = 149 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 79[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 530,201 instr/s-
select-sort.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000158[src/cpu/cpu-exec.c:55 statistic] host time spent = 4,600 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 2,854[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 620,434 instr/s-
to-lower-case.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800000d8[src/cpu/cpu-exec.c:55 statistic] host time spent = 3,260 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 2,002[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 614,110 instr/s-
bubble-sort.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000013c[src/cpu/cpu-exec.c:55 statistic] host time spent = 4,322 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 2,796[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 646,922 instr/s-
if-else.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000010c[src/cpu/cpu-exec.c:55 statistic] host time spent = 495 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 291[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 587,878 instr/s-
movsx.c
不需要实现更多的指令即可运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800001c8[src/cpu/cpu-exec.c:55 statistic] host time spent = 238 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 128[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 537,815 instr/s-
shift.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000013c[src/cpu/cpu-exec.c:55 statistic] host time spent = 549 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 322[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 586,520 instr/s-
unalign.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000148[src/cpu/cpu-exec.c:55 statistic] host time spent = 293 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 172[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 587,030 instr/s-
div.c
mul & mulh & mulhu
mul rd, rs1, rs2x[rd]=x[rs1]×x[rs2]RV32M,R-type,rri 系
- mul 忽略算术溢出
- mulh 无符号乘法(视为有符号数)取高 32 位
- mulhu 无符号乘法(视为无符号数)取高 32 位
辅助函数如下:
def_EHelper(mul) { rtl_mulu_lo(s, ddest, dsrc1, dsrc2);}
def_EHelper(mulh) { rtl_muls_hi(s, ddest, dsrc1, dsrc2);}
def_EHelper(mulhu) { rtl_mulu_hi(s, ddest, dsrc1, dsrc2);}其中利用了:
#define c_mulu_lo(a, b) ((a) * (b))#define c_mulu_hi(a, b) (((uint64_t)(a) * (uint64_t)(b)) >> 32)#define c_muls_hi(a, b) (((int64_t)(sword_t)(a) * (int64_t)(sword_t)(b)) >> 32)还有一个指令叫 mulhsu,一个视为有符号数,一个视为无符号数,进行无符号乘法。尚未实现。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000118[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,383 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 865[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 625,451 instr/s-
leap-year.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800000dc[src/cpu/cpu-exec.c:55 statistic] host time spent = 2,571 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,693[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 658,498 instr/s-
mul-longlong.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000160[src/cpu/cpu-exec.c:55 statistic] host time spent = 440 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 261[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 593,181 instr/s-
shuixianhua.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x8000011c[src/cpu/cpu-exec.c:55 statistic] host time spent = 9,092 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 6,064[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 666,959 instr/s-
wanshu.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000104[src/cpu/cpu-exec.c:55 statistic] host time spent = 4,029 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 2,679[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 664,929 instr/s-
load-store.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800001e8[src/cpu/cpu-exec.c:55 statistic] host time spent = 643 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 371[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 576,982 instr/s-
pascal.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000120[src/cpu/cpu-exec.c:55 statistic] host time spent = 5,072 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 3,191[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 629,140 instr/s-
fact.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000110[src/cpu/cpu-exec.c:55 statistic] host time spent = 787 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 476[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 604,828 instr/s-
matrix-mul.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000158[src/cpu/cpu-exec.c:55 statistic] host time spent = 20,039 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 8,960[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 447,128 instr/s-
prime.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800000dc[src/cpu/cpu-exec.c:55 statistic] host time spent = 8,374 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 5,209[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 622,044 instr/s-
sub-longlong.c
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000138[src/cpu/cpu-exec.c:55 statistic] host time spent = 1,866 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,262[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 676,312 instr/s一键回归测试
为了保证加入的新功能没有影响到已有功能的实现,你还需要重新运行这些测试用例。在软件测试中,这个过程称为回归测试。
既然将来还要重复运行这些测试用例,而手动重新运行每一个测试显然是一种效率低下的做法。为了提高效率,我们为 cpu-tests 提供了一键回归测试的功能:
make ARCH=$ISA-nemu run即可自动批量运行 cpu-tests 中的所有测试,并报告每个测试用例的运行结果。
我们可以尝试理解一下这是如何实现的:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests$ make -n ARCH=riscv32-nemu ALL=add run/bin/echo -e "NAME = add\nSRCS = tests/add.c\nLIBS += klib\ninclude ${AM_HOME}/Makefile" > Makefile.addif make -s -f Makefile.add ARCH=riscv32-nemu run; then \ printf "[%14s] \033[1;32mPASS!\033[0m\n" add >> .result; \else \ printf "[%14s] \033[1;31mFAIL!\033[0m\n" add >> .result; \firm -f Makefile.addecho "" addcat .resultrm .result对照 Makefile 文件:
.PHONY: all run clean latest $(ALL)
RESULT = .result$(shell > $(RESULT))
COLOR_RED = \033[1;31mCOLOR_GREEN = \033[1;32mCOLOR_NONE = \033[0m
ALL = $(basename $(notdir $(shell find tests/. -name "*.c")))
all: $(addprefix Makefile., $(ALL)) @echo "" $(ALL)
$(ALL): %: Makefile.%
Makefile.%: tests/%.c latest @/bin/echo -e "NAME = $*\nSRCS = $<\nLIBS += klib\ninclude $${AM_HOME}/Makefile" > $@ @if make -s -f $@ ARCH=$(ARCH) $(MAKECMDGOALS); then \ printf "[%14s] $(COLOR_GREEN)PASS!$(COLOR_NONE)\n" $* >> $(RESULT); \ else \ printf "[%14s] $(COLOR_RED)FAIL!$(COLOR_NONE)\n" $* >> $(RESULT); \ fi -@rm -f Makefile.$*
run: all @cat $(RESULT) @rm $(RESULT)
clean: rm -rf Makefile.* build/
latest:可知依赖关系为:run -> all -> Makefile。若未传入 ALL 参数,ALL 便是所有的测试用例的文件名。
实现常用的库函数
运行时环境分成两部分:
- 一部分是架构相关的运行时环境,也就是 AM
- 另一部分是架构无关的运行时环境,类似
memcpy()这种常用的函数应该归入这部分,abstract-machine/klib/用于收录这些架构无关的库函数
根据需要实现 abstract-machine/klib/src 中列出的库函数,让 cpu-tests 中的测试用例 string 和 hello-str 可以成功运行。
-
string.c
需要实现:
- strcmp
- strcpy
- strcat
- memset
- memcmp
参考 glibc、C 标准库和 cppreference 给出 <string.h> 的部分实现:
void *memset (void *s, int c, size_t n);void *memcpy (void *dst, const void *src, size_t n);void *memmove (void *dst, const void *src, size_t n);int memcmp (const void *s1, const void *s2, size_t n);size_t strlen (const char *s);char *strcat (char *dst, const char *src);char *strcpy (char *dst, const char *src);char *strncpy (char *dst, const char *src, size_t n);int strcmp (const char *s1, const char *s2);int strncmp (const char *s1, const char *s2, size_t n);https://www.gnu.org/software/libc/
https://en.cppreference.com/w/
memset
对于 mem 系,glibc 的实现有点过于重量级,所以采用了 C 标准库中的实现
void *memset( void *dest, int ch, size_t count );行为:
复制值 ch(转换到 unsigned char 后)到 dest 所指向对象的首 count 个字节。若出现 dest 数组结尾后的访问则行为未定义。若 dest 为空指针则行为未定义。
实现:
void *memset(void *s, int c, size_t n) { const unsigned char uc=c; unsigned char *us=(unsigned char *)s; for(;n>0;++us,--n) *us=uc; return s;}memcpy
void* memcpy( void *dest, const void *src, size_t count );行为:
从 src 所指向的对象复制 count 个字符到 dest 所指向的对象。两个对象都被转译成 unsigned char 的数组。若访问发生在 dest 数组结尾后则行为未定义。若对象重叠(这违背 restrict 契约,C99 起),则行为未定义。若 dest 或 src 为非法或空指针则行为未定义。
实现:
void *memcpy(void *s1, const void *s2, size_t n) { unsigned char *us1=(unsigned char *)s1; const unsigned char *us2=(const unsigned char *)s2; for(;n>0;++us1,++us2,--n) *us1=*us2; return s1;}memcmp
int memcmp( const void* lhs, const void* rhs, size_t count );行为:
比较 lhs 和 rhs 所指向对象的首 count 个字节。比较按字典序进行。
结果的符号是在被比较对象中相异的首对字节的值(都转译成 unsigned char)的差。
若在 lhs 和 rhs 所指向的任一对象结尾后出现访问,则行为未定义。若 lhs 或 rhs 为空指针则行为未定义。
int memcmp(const void *s1, const void *s2, size_t n) { const unsigned char* us1=(const unsigned char*)s1; const unsigned char* us2=(const unsigned char*)s2; for(;n>0;++us1,++us2,--n) if(*us1!=*us2) return (*us1<*us2)?-1:1; return 0;}memmove
void* memmove( void* dest, const void* src, size_t count );行为:
从 src 所指向的对象复制 count 个字节到 dest 所指向的对象。两个对象都被转译成 unsigned char 的数组。对象可以重叠:如同复制字符到临时数组,再从该数组到 dest 一般发生复制。
若出现 dest 数组末尾后的访问则行为未定义。若 dest 或 src 为非法或空指针则行为未定义。
实现:
TODO
strlen & strnlen
size_t strlen( const char *str );行为:
返回给定空终止字符串的长度,即首元素为 str 所指,且不包含首个空字符(即末尾的 \0)的字符数组中的字符数。
若 str 不是指向空终止字节字符串的指针则行为未定义。
实现:
C 标准库
size_t strlen(const char *s) { const char *sc; for(sc=s;*sc!='\0';++sc); return (sc-s);}
size_t strnlen(const char *s, size_t n) { const char *sc; for(sc=s;n>0&&*sc!='\0';++sc,--n); return (sc-s);}这里 strnlen 在 cppreference 竟然找不到,只能 man 了。
glibc 的实现优于线性时间:
strcpy
char *strcpy( char *dest, const char *src );行为:
复制 src 所指向的空终止字节字符串,包含空终止符,到首元素为 dest 所指的字符数组。
若 dest 数组长度不足则行为未定义。若字符串覆盖则行为未定义。若 dest 不是指向字符数组的指针或 src 不是指向空终止字节字符串的指针则行为未定义。
实现,利用 memcpy:
glibc
char *strcpy(char *dst, const char *src) { return memcpy (dst, src, strlen (src) + 1);}strncpy
char *strncpy( char *dest, const char *src, size_t count );行为:
复制 src 所指向的字符数组的至多 count 个字符(包含空终止字符,但不包含后随空字符的任何字符)到 dest 所指向的字符数组。
若在完全复制整个 src 数组前抵达 count ,则结果的字符数组不是空终止的。
若在复制来自 src 的空终止字符后未抵达 count ,则写入额外的空字符到 dest ,直至写入总共 count 个字符。
若字符数组重叠,若 dest 或 src 不是指向字符数组的指针(包含若 dest 或 src 为空指针),若 dest 所指向的数组大小小于 count ,或若 src 所指向的数组大小小于 count 且它不含空字符,则行为未定义。
实现,利用 memcpy、memset 和 strnlen:
glibc
char *strncpy(char *dst, const char *src, size_t n) { size_t size = strnlen (src, n); if (size != n) memset (dst + size, '\0', n - size); return memcpy (dst, src, size);}若 size != n,后面写入额外的空字符,否则 src 长度大于等于 n,结果的字符数组就不是空终止的。
strcat
char *strcat( char *dest, const char *src );行为:
后附 src 所指向的空终止字节字符串的副本到 dest 所指向的空终止字节字符串的结尾。字符 src[0] 替换 dest 末尾的空终止符。产生的字节字符串是空终止的。
若目标数组对于 src 和 dest 的内容以及空终止符不够大,则行为未定义。若字符串重叠,则行为未定义。若 dest 或 src 不是指向空终止字节字符串的指针,则行为未定义。
实现:
glibc
char *strcat(char *dst, const char *src) { strcpy (dst + strlen (dst), src); return dst;}strcmp
int strcmp( const char *lhs, const char *rhs );行为:
以字典序比较二个空终止字节字符串。
结果的符号是被比较的字符串中首对不同字符(都转译成 unsigned char)的值间的差的符号。
若 lhs 或 rhs 不是指向空终止字节字符串的指针,则行为未定义。
实现:
glibc
int strcmp(const char *p1, const char *p2) { const unsigned char *s1 = (const unsigned char *) p1; const unsigned char *s2 = (const unsigned char *) p2; unsigned char c1, c2;
do { c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0') return c1 - c2; } while (c1 == c2);
return c1 - c2;}strncmp
int strncmp( const char *lhs, const char *rhs, size_t count );行为:
比较二个可能空终止的数组的至多 count 个字符。按字典序进行比较。不比较后随空字符的字符。
结果的符号是被比较的数组中首对字符(都转译成 unsigned char)的值间的差的符号。
若出现越过 lhs 或 rhs 结尾的访问,则行为未定义。若 lhs 或 rhs 为空指针,则行为未定义。
实现:
glibc
int strncmp(const char *s1, const char *s2, size_t n) { unsigned char c1 = '\0'; unsigned char c2 = '\0';
if (n >= 4) { size_t n4 = n >> 2; do { c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0' || c1 != c2) return c1 - c2; c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0' || c1 != c2) return c1 - c2; c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0' || c1 != c2) return c1 - c2; c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0' || c1 != c2) return c1 - c2; } while (--n4 > 0); n &= 3; }
while (n > 0) { c1 = (unsigned char) *s1++; c2 = (unsigned char) *s2++; if (c1 == '\0' || c1 != c2) return c1 - c2; n--; }
return c1 - c2;}做了优化,看来 strncmp 比 strcmp 更受欢迎
通过 make ARCH=riscv32-nemu ALL=string 让 string.c 使用这里库函数的定义。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000148[src/cpu/cpu-exec.c:55 statistic] host time spent = 2,404 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,510[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 628,119 instr/s-
hello-str.c
需要实现:
- sprintf
参考 glibc、C 标准库和 cppreference 给出 <stdio.h> 的部分实现:
int printf (const char *format, ...);int sprintf (char *str, const char *format, ...);int snprintf (char *str, size_t size, const char *format, ...);int vsprintf (char *str, const char *format, va_list ap);int vsnprintf (char *str, size_t size, const char *format, va_list ap);sprintf
变参数函数,实现依赖于 vsprintf:
int sprintf(char *out, const char *fmt, ...) { va_list ap; int ret;
va_start(ap, fmt); ret = vsprintf(out, fmt, ap); va_end(ap);
if (index >= BUF_SIZE) panic("sprintf buffer overflow!!!");
return ret;}
stdarg.h中包含一些获取函数调用参数的宏,它们可以看做是调用约定中关于参数传递方式的抽象。不同 ISA 的 ABI 规范(Application Binary Interface)会定义不同的函数参数传递方式。
vsprintf
int vsprintf( char *buffer, const char *format, va_list vlist );https://zh.cppreference.com/w/c/variadic
返回值是写入的字符数,目前只考虑 %d, %s, %c,实现的非常丑:
static int index;
int vsprintf(char *out, const char *fmt, va_list ap) { char *cur=(char *)fmt;
memset(out,'\0',BUF_SIZE); index = 0;
while(*cur!='\0'){ if(*cur=='%'){ cur++; switch(*cur){ case 's': sprint_s(out,va_arg(ap,char *)); break; case 'd': sprint_d(out,va_arg(ap,int)); break; case 'c': sprint_c(out,va_arg(ap,int)); break; default: out[index++]='%'; out[index++]=*cur; break; } }else{ out[index++]=*cur; } cur++; }
return index;}sprint_s, sprint_d, sprint_c 是一些辅助函数。
运行程序:
[src/cpu/cpu-exec.c:122 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000108[src/cpu/cpu-exec.c:55 statistic] host time spent = 2,662 us[src/cpu/cpu-exec.c:56 statistic] total guest instructions = 1,762[src/cpu/cpu-exec.c:57 statistic] simulation frequency = 661,908 instr/s重新认识计算机:计算机是个抽象层
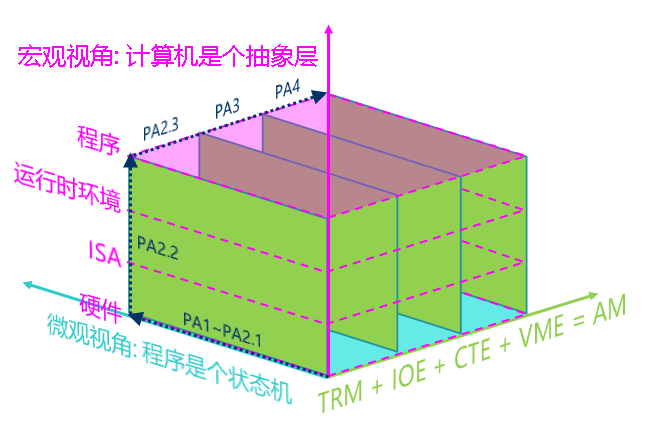
我们先来讨论在 TRM 上运行的程序,我们对这些程序的需求进行分类,来看看我们的计算机系统是如何支撑这些需求的:
| TRM | 计算 | 内存申请 | 结束运行 | 打印信息 |
|---|---|---|---|---|
| 运行环境 | - | malloc() / free() | - | printf() |
| AM API | - | heap | halt() | putch() |
| ISA 接口 | 指令 | 物理内存地址空间 | nemu_trap 指令 | I/O 方式 |
| 硬件模块 | 处理器 | 物理内存 | Monitor | 串口 |
| 电路实现 | cpu_exec() | pmem[] | nemu_state | serial_io_handler() |
每一层抽象都有它存在的理由:
- 概念相同的一个硬件模块有着不同的实现方式,比如处理器既可以通过 NEMU 中简单的解释方式来实现,也可以通过类似 QEMU 中高性能的二进制翻译方式来实现,甚至可以通过 verilog 等硬件描述语言来实现一个真实的处理器
- ISA 是硬件向软件提供的可以操作硬件的接口
- AM 的 API 对不同 ISA (如 x86 / mips32 / riscv32) 的接口进行了抽象,为上层的程序屏蔽 ISA 相关的细节
- 运行时环境可以通过对 AM 的 API 进行进一步的封装,向程序提供更方便的功能
PA 的全局概念图
程序在计算机上运行:
- 微观视角:程序是个状态机
- 宏观视角:计算机是个抽象层
踪迹 - trace
指令执行的踪迹 - itrace
instruction trace,框架代码在 cpu-exec.c 中已经实现了:
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {#ifdef CONFIG_ITRACE_COND if (ITRACE_COND) log_write("%s\n", _this->logbuf);#endif if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); } IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
...}这里有两个相关的宏,默认都是打开的:
config ITRACE depends on TRACE && TARGET_NATIVE_ELF && ENGINE_INTERPRETER bool "Enable instruction tracer" default y
config ITRACE_COND depends on ITRACE string "Only trace instructions when the condition is true" default "true"而输出的内容 logbuf 源自 fetch_decode 函数:
#ifdef CONFIG_ITRACE char *p = s->logbuf; p += snprintf(p, sizeof(s->logbuf), FMT_WORD ":", s->pc); int ilen = s->snpc - s->pc; int i; uint8_t *instr = (uint8_t *)&s->isa.instr.val; for (i = 0; i < ilen; i ++) { p += snprintf(p, 4, " %02x", instr[i]); } int ilen_max = MUXDEF(CONFIG_ISA_x86, 8, 4); int space_len = ilen_max - ilen; if (space_len < 0) space_len = 0; space_len = space_len * 3 + 1; memset(p, ' ', space_len); p += space_len;
void disassemble(char *str, int size, uint64_t pc, uint8_t *code, int nbyte); disassemble(p, s->logbuf + sizeof(s->logbuf) - p, MUXDEF(CONFIG_ISA_x86, s->snpc, s->pc), (uint8_t *)&s->isa.instr.val, ilen);#endifdisassemble 的定义位于 nemu/src/utils/disasm.cc,其中调用了 llvm 项目提供的反汇编功能。
这里的输出的内容有两个去处,一个是 nemu/build/nemu-log.txt 中(无限制),一个是打印在屏幕上,其中 MAX_INSTR_TO_PRINT 定义了一次最多能够打印的指令数,默认为 10,于是只有 cpu_exec(n) 的 n<10 才能打印在屏幕上(自然 cpu_exec(-1) 是不会打印在屏幕上的)。
对于一些输出规整的 trace,我们还可以通过 grep, awk, sed 等文本处理工具来对它们进行筛选和处理。
指令环形缓冲区 - iringbuf
具体地,在每执行一条指令的时候,就把这条指令的信息写入到环形缓冲区 (ring buffer) 中;如果缓冲区满了,就会覆盖旧的内容。客户程序出错的时候,就把环形缓冲区中的指令打印出来,供调试进行参考。
添加二维字符数组和索引:
// ring buffer#define MAX_INSTR_RING_BUFFER 20static char ring_buffer[MAX_INSTR_RING_BUFFER][128];static int ring_buffer_index = -1;此处 128 对应 logbuf 的大小:
typedef struct Decode { vaddr_t pc; vaddr_t snpc; // static next pc vaddr_t dnpc; // dynamic next pc void (*EHelper)(struct Decode *); Operand dest, src1, src2; ISADecodeInfo isa; IFDEF(CONFIG_ITRACE, char logbuf[128]);} Decode;修改 trace_and_difftest:
static void trace_and_difftest(Decode *_this, vaddr_t dnpc) {#ifdef CONFIG_ITRACE_COND if (ITRACE_COND) log_write("%s\n", _this->logbuf);#endif if (g_print_step) { IFDEF(CONFIG_ITRACE, puts(_this->logbuf)); } IFDEF(CONFIG_DIFFTEST, difftest_step(_this->pc, dnpc));
if (check_wp() && nemu_state.state != NEMU_ABORT && nemu_state.state != NEMU_END) nemu_state.state = NEMU_STOP;
if (ring_buffer_index >= MAX_INSTR_RING_BUFFER) ring_buffer_index = -1; strcpy(ring_buffer[++ring_buffer_index], _this->logbuf);}在 assert_fail_msg 中添加 ring_buffer_display 函数,定义如下:
static void ring_buffer_display() { printf("----------------------------iringbuf----------------------------\n"); for(int i = 0; i < MAX_INSTR_RING_BUFFER; ++i) { if (i == ring_buffer_index) printf(" --> %s\n", ring_buffer[i]); else printf(" %s\n", ring_buffer[i]); } printf("----------------------------iringbuf----------------------------\n");}我们破坏 jal 指令来测试一下:
----------------------------iringbuf---------------------------- 0x80000000: 13 04 00 00 mv s0, zero 0x80000004: 17 91 00 00 auipc sp, 9 0x80000008: 13 01 c1 ff addi sp, sp, -4 --> 0x8000000c: ef 00 c0 00 jal 12
----------------------------iringbuf----------------------------内存访问的踪迹 - mtrace
追踪程序访存的具体行为,然后从其中找出不正确的访存。
只需要在 paddr_read() 和 paddr_write() 中进行记录即可。
不过和最后只输出一次的 iringbuf 不同,程序一般会执行很多访存指令,这意味着开启 mtrace 将会产生大量的输出,因此最好可以在不需要的时候关闭 mtrace。
通过 menuconfig 来打开或者关闭 mtrace。
config MTRACE depends on TRACE && TARGET_NATIVE_ELF && ENGINE_INTERPRETER bool "Enable memory tracer" default y另外也可以实现 mtrace 输出的条件,例如你可能只会关心某一段内存区间的访问。
框架代码已经实现了错误的访存记录,宏 CONFIG_DEVICE 默认为 n,我们只要记录正确的访存记录即可:
word_t paddr_read(paddr_t addr, int len) { if (likely(in_pmem(addr))) { word_t res = pmem_read(addr, len); IFDEF(CONFIG_MTRACE, Log("address = " FMT_PADDR " read " FMT_PADDR " at pc = " FMT_WORD, addr, res, cpu.pc)); return res; } MUXDEF(CONFIG_DEVICE, return mmio_read(addr, len), panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", " FMT_PADDR ") at pc = " FMT_WORD, addr, CONFIG_MBASE, CONFIG_MBASE + CONFIG_MSIZE, cpu.pc));}
void paddr_write(paddr_t addr, int len, word_t data) { if (likely(in_pmem(addr))) { pmem_write(addr, len, data); IFDEF(CONFIG_MTRACE, Log("address = " FMT_PADDR " write " FMT_PADDR " at pc = " FMT_WORD, addr, data, cpu.pc)); return; } MUXDEF(CONFIG_DEVICE, mmio_write(addr, len, data), panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", " FMT_PADDR ") at pc = " FMT_WORD, addr, CONFIG_MBASE, CONFIG_MBASE + CONFIG_MSIZE, cpu.pc));}函数调用的踪迹 - ftrace
分析
追踪程序执行过程中的函数调用和返回。
在相关指令的执行辅助函数中添加代码来实现这些功能。
目标地址和 PC 值仍然缺少程序语义,我们需要把它们翻译成函数名。这就需要解析 ELF 文件。
使用命令 riscv64-linux-gnu-readelf -a add-riscv32-nemu.elf,筛选得到节头表:
Section Headers: [Nr] Name Type Addr Off Size ES Flg Lk Inf Al [ 0] NULL 00000000 000000 000000 00 0 0 0 [ 1] .text PROGBITS 80000000 001000 000128 00 AX 0 0 4 [ 2] .srodata.mainargs PROGBITS 80000128 001128 000001 00 A 0 0 4 [ 3] .data.ans PROGBITS 8000012c 00112c 000100 00 WA 0 0 4 [ 4] .data.test_data PROGBITS 8000022c 00122c 000020 00 WA 0 0 4 [ 5] .comment PROGBITS 00000000 00124c 000025 01 MS 0 0 1 [ 6] .symtab SYMTAB 00000000 001274 0001c0 10 7 9 4 [ 7] .strtab STRTAB 00000000 001434 00009b 00 0 0 1 [ 8] .shstrtab STRTAB 00000000 0014cf 000056 00 0 0 1和符号表信息:
Symbol table '.symtab' contains 28 entries: Num: Value Size Type Bind Vis Ndx Name 0: 00000000 0 NOTYPE LOCAL DEFAULT UND 1: 80000000 0 SECTION LOCAL DEFAULT 1 2: 80000128 0 SECTION LOCAL DEFAULT 2 3: 8000012c 0 SECTION LOCAL DEFAULT 3 4: 8000022c 0 SECTION LOCAL DEFAULT 4 5: 00000000 0 SECTION LOCAL DEFAULT 5 6: 00000000 0 FILE LOCAL DEFAULT ABS add.c 7: 00000000 0 FILE LOCAL DEFAULT ABS trm.c 8: 80000128 1 OBJECT LOCAL DEFAULT 2 mainargs 9: 80000108 32 FUNC GLOBAL DEFAULT 1 _trm_init 10: 80009000 0 NOTYPE GLOBAL DEFAULT 4 _stack_pointer 11: 80000128 0 NOTYPE GLOBAL DEFAULT 1 _etext 12: 80000000 0 NOTYPE GLOBAL DEFAULT ABS _pmem_start 13: 8000024c 0 NOTYPE GLOBAL DEFAULT 4 _bss_start 14: 80000129 0 NOTYPE GLOBAL DEFAULT 2 edata 15: 80009000 0 NOTYPE GLOBAL DEFAULT 4 _heap_start 16: 80001000 0 NOTYPE GLOBAL DEFAULT 4 _stack_top 17: 80009000 0 NOTYPE GLOBAL DEFAULT 4 end 18: 80000010 24 FUNC GLOBAL DEFAULT 1 check 19: 80000128 0 NOTYPE GLOBAL DEFAULT 1 etext 20: 80000000 0 FUNC GLOBAL DEFAULT 1 _start 21: 00000000 0 NOTYPE GLOBAL DEFAULT ABS _entry_offset 22: 80000028 212 FUNC GLOBAL DEFAULT 1 main 23: 80000129 0 NOTYPE GLOBAL DEFAULT 2 _data 24: 8000012c 256 OBJECT GLOBAL DEFAULT 3 ans 25: 80009000 0 NOTYPE GLOBAL DEFAULT 4 _end 26: 800000fc 12 FUNC GLOBAL DEFAULT 1 halt 27: 8000022c 32 OBJECT GLOBAL DEFAULT 4 test_data我们输出 ELF 文件符号表的十六进制形式:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ riscv64-linux-gnu-readelf -x6 add-riscv32-nemu.elf
Hex dump of section '.symtab': 0x00000000 00000000 00000000 00000000 00000000 ................ 0x00000010 00000000 00000080 00000000 03000100 ................ 0x00000020 00000000 28010080 00000000 03000200 ....(........... 0x00000030 00000000 2c010080 00000000 03000300 ....,........... 0x00000040 00000000 2c020080 00000000 03000400 ....,........... 0x00000050 00000000 00000000 00000000 03000500 ................ 0x00000060 01000000 00000000 00000000 0400f1ff ................ 0x00000070 07000000 00000000 00000000 0400f1ff ................ 0x00000080 0d000000 28010080 01000000 01000200 ....(........... 0x00000090 16000000 08010080 20000000 12000100 ........ ....... 0x000000a0 20000000 00900080 00000000 10000400 ............... 0x000000b0 2f000000 28010080 00000000 10000100 /...(........... 0x000000c0 36000000 00000080 00000000 1000f1ff 6............... 0x000000d0 42000000 4c020080 00000000 10000400 B...L........... 0x000000e0 4d000000 29010080 00000000 10000200 M...)........... 0x000000f0 53000000 00900080 00000000 10000400 S............... 0x00000100 5f000000 00100080 00000000 10000400 _............... 0x00000110 88000000 00900080 00000000 10000400 ................ 0x00000120 6a000000 10000080 18000000 12000100 j............... 0x00000130 30000000 28010080 00000000 10000100 0...(........... 0x00000140 3b000000 00000080 00000000 12000100 ;............... 0x00000150 70000000 00000000 00000000 1000f1ff p............... 0x00000160 7e000000 28000080 d4000000 12000100 ~...(........... 0x00000170 95000000 29010080 00000000 10000200 ....)........... 0x00000180 83000000 2c010080 00010000 11000300 ....,........... 0x00000190 87000000 00900080 00000000 10000400 ................ 0x000001a0 8c000000 fc000080 0c000000 12000100 ................ 0x000001b0 91000000 2c020080 20000000 11000400 ....,... .......符号表的每一项占 16 个字节,下标为 0 的元素为空。
分析下标为 9 和 12 的项:
0x00000090 16000000 08010080 20000000 12000100 0x000000c0 36000000 00000080 00000000 1000f1ff注意字节序,可得:
- 第 9~12 字节为 Size
- 第 5~8 字节为 Value
- 第 13 字节为 Bind 和 Type
- 第 15~16 字节为 Ndx
- 第 1~4 字节为 Name(在字符串表中的起始下标)
参阅程序员的自我修养
可以对应解析后的结果:
Num: Value Size Type Bind Vis Ndx Name 9: 80000108 32 FUNC GLOBAL DEFAULT 1 _trm_init 12: 80000000 0 NOTYPE GLOBAL DEFAULT ABS _pmem_start_trm_init -> 0x16 -> 5f74726d5f696e6974
_pmem_start -> 0x36 -> 5f706d656d5f7374617274
对照 ELF 文件字符串表的十六进制形式,以 0x00 分隔:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ riscv64-linux-gnu-readelf -x7 add-riscv32-nemu.elf
Hex dump of section '.strtab': 0x00000000 00616464 2e630074 726d2e63 006d6169 .add.c.trm.c.mai 0x00000010 6e617267 73005f74 726d5f69 6e697400 nargs._trm_init. 0x00000020 5f737461 636b5f70 6f696e74 6572005f _stack_pointer._ 0x00000030 65746578 74005f70 6d656d5f 73746172 etext._pmem_star 0x00000040 74005f62 73735f73 74617274 00656461 t._bss_start.eda 0x00000050 7461005f 68656170 5f737461 7274005f ta._heap_start._ 0x00000060 73746163 6b5f746f 70006368 65636b00 stack_top.check. 0x00000070 5f656e74 72795f6f 66667365 74006d61 _entry_offset.ma 0x00000080 696e0061 6e73005f 656e6400 68616c74 in.ans._end.halt 0x00000090 00746573 745f6461 746100 .test_data.注意符号表不会记录非静态局部变量。
在 Linux 下编写一个 Hello World 程序,编译后通过上述方法找到 ELF 文件的字符串表,似乎找不到”Hello World!”字符串。
进一步的,使用
strip命令丢弃可执行文件中的符号表:Terminal window 程序仍然可以正常运行。
另一方面,如果我们丢弃目标文件中的符号表,在链接阶段会报错:
现在的目标是定位符号表和字符串表,首先观察 ELF 头,试图得到节头表的偏移:
ELF Header: Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00 Class: ELF32 Data: 2's complement, little endian Version: 1 (current) OS/ABI: UNIX - System V ABI Version: 0 Type: EXEC (Executable file) Machine: RISC-V Version: 0x1 Entry point address: 0x80000000 Start of program headers: 52 (bytes into file) Start of section headers: 5416 (bytes into file) Flags: 0x0 Size of this header: 52 (bytes) Size of program headers: 32 (bytes) Number of program headers: 2 Size of section headers: 40 (bytes) Number of section headers: 9 Section header string table index: 8可知 ELF 头的大小为 52 字节,我们获取这 52 个字节的二进制信息:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -n 520000000 457f 464c 0101 0001 0000 0000 0000 00000000010 0002 00f3 0001 0000 0000 8000 0034 00000000020 1528 0000 0000 0000 0034 0020 0002 00280000030 0009 00080000034注意 0x0000020 处为 0x00001528,十进制即为 5416,这便是节头表的偏移。另外 0x000002e 处给出了节头表每一节的长度 0x28,十进制即为 40。
进而查看节头表处的二进制信息,这里以每 40 字节展示:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5416 -n 400001528 0000 0000 0000 0000 0000 0000 0000 0000*0001548 0000 0000 0000 00000001550vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5456 -n 400001550 001b 0000 0001 0000 0006 0000 0000 80000001560 1000 0000 0128 0000 0000 0000 0000 00000001570 0004 0000 0000 00000001578vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5496 -n 400001578 0021 0000 0001 0000 0002 0000 0128 80000001588 1128 0000 0001 0000 0000 0000 0000 00000001598 0004 0000 0000 000000015a0vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5536 -n 4000015a0 0033 0000 0001 0000 0003 0000 012c 800000015b0 112c 0000 0100 0000 0000 0000 0000 000000015c0 0004 0000 0000 000000015c8vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5576 -n 4000015c8 003d 0000 0001 0000 0003 0000 022c 800000015d8 122c 0000 0020 0000 0000 0000 0000 000000015e8 0004 0000 0000 000000015f0vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5616 -n 4000015f0 004d 0000 0001 0000 0030 0000 0000 00000001600 124c 0000 0025 0000 0000 0000 0000 00000001610 0001 0000 0001 00000001618vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5656 -n 400001618 0001 0000 0002 0000 0000 0000 0000 00000001628 1274 0000 01c0 0000 0007 0000 0009 00000001638 0004 0000 0010 00000001640vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5696 -n 400001640 0009 0000 0003 0000 0000 0000 0000 00000001650 1434 0000 009b 0000 0000 0000 0000 00000001660 0001 0000 0000 00000001668vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5736 -n 400001668 0011 0000 0003 0000 0000 0000 0000 00000001678 14cf 0000 0056 0000 0000 0000 0000 00000001688 0001 0000 0000 00000001690我们从中找到符号表和字符串表:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5656 -n 400001618 0001 0000 0002 0000 0000 0000 0000 00000001628 1274 0000 01c0 0000 0007 0000 0009 00000001638 0004 0000 0010 00000001640vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 5696 -n 400001640 0009 0000 0003 0000 0000 0000 0000 00000001650 1434 0000 009b 0000 0000 0000 0000 00000001660 0001 0000 0000 00000001668可以定位对应的偏移分别为 0x1274 和 0x1434,大小分别为 0x01c0 和 0x009b。
我们以符号表作为测试,可以发现输出和上面的一致:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests/build$ hexdump add-riscv32-nemu.elf -s 0x1274 -n 0x1c00001274 0000 0000 0000 0000 0000 0000 0000 00000001284 0000 0000 0000 8000 0000 0000 0003 00010001294 0000 0000 0128 8000 0000 0000 0003 000200012a4 0000 0000 012c 8000 0000 0000 0003 000300012b4 0000 0000 022c 8000 0000 0000 0003 000400012c4 0000 0000 0000 0000 0000 0000 0003 000500012d4 0001 0000 0000 0000 0000 0000 0004 fff100012e4 0007 0000 0000 0000 0000 0000 0004 fff100012f4 000d 0000 0128 8000 0001 0000 0001 00020001304 0016 0000 0108 8000 0020 0000 0012 00010001314 0020 0000 9000 8000 0000 0000 0010 00040001324 002f 0000 0128 8000 0000 0000 0010 00010001334 0036 0000 0000 8000 0000 0000 0010 fff10001344 0042 0000 024c 8000 0000 0000 0010 00040001354 004d 0000 0129 8000 0000 0000 0010 00020001364 0053 0000 9000 8000 0000 0000 0010 00040001374 005f 0000 1000 8000 0000 0000 0010 00040001384 0088 0000 9000 8000 0000 0000 0010 00040001394 006a 0000 0010 8000 0018 0000 0012 000100013a4 0030 0000 0128 8000 0000 0000 0010 000100013b4 003b 0000 0000 8000 0000 0000 0012 000100013c4 0070 0000 0000 0000 0000 0000 0010 fff100013d4 007e 0000 0028 8000 00d4 0000 0012 000100013e4 0095 0000 0129 8000 0000 0000 0010 000200013f4 0083 0000 012c 8000 0100 0000 0011 00030001404 0087 0000 9000 8000 0000 0000 0010 00040001414 008c 0000 00fc 8000 000c 0000 0012 00010001424 0091 0000 022c 8000 0020 0000 0011 00040001434现在我们就可以把一个给定的地址翻译成函数名了:由于函数的范围是互不相交的,我们可以逐项扫描符号表中中 Type 属性为 FUNC 的每一个表项,检查给出的地址是否落在区间 [Value, Value + Size) 内,若是,则根据表项中的 Name 属性在字符串表中找到相应的字符串,作为函数名返回。如果没有找到符合要求的符号表表项,可以返回字符串 ???。
实现
增改四个地方:
-
在 Kconfig 中添加宏 CONFIG_FTRACE
-
在 include 文件夹下添加头文件 elf.h:
#ifndef __ELF_H__#define __ELF_H__
typedef struct { vaddr_t value; uint32_t size; uint32_t string_index; char name[256];} elf_func_symbol;
extern elf_func_symbol func_symbol[128];extern uint32_t func_symbol_number;
#endif注意此处的 extern 关键词,func_symbol 和 func_symbol_number 定义在 monitor.c 中,其他地方引用该变量需要包含该头文件。
外部变量!
- 修改 monitor.c 中的 parse_args,添加变量和函数 load_elf_and_parse,并在 init_monitor 中调用 load_elf_and_parse 函数:
elf_func_symbol func_symbol[128];uint32_t func_symbol_number;
static void load_elf_and_parse() { if (elf_file == NULL) { Log("No ELF file is given."); return; }
FILE *fp = fopen(elf_file, "rb"); Assert(fp, "Can not open '%s'", elf_file);
fseek(fp, 0, SEEK_END); long size = ftell(fp);
Log("The ELF file is %s, size = %ld", elf_file, size);
uint8_t *elf = malloc(size * sizeof(uint8_t)); fseek(fp, 0, SEEK_SET); int ret = fread(elf, size, 1, fp); assert(ret == 1); fclose(fp);
// for (long i = 0; i < size; ) { // printf("%2x ", elf[i]); // if (++i % 16 == 0) printf("\n"); // } // printf("\n");
uint32_t sector_header_index = 0; uint32_t sector_header_length = 0; // the size of one section uint32_t sector_header_number = 0;
for (uint32_t i = 35; i >= 32; --i) sector_header_index = sector_header_index * 256 + elf[i]; // printf("%2d\n", sector_header_index);
for (uint32_t i = 47; i >= 46; --i) sector_header_length = sector_header_length * 256 + elf[i];
for (uint32_t i = 49; i >= 48; --i) sector_header_number = sector_header_number * 256 + elf[i];
uint32_t symbol_table_index = 0; uint32_t symbol_table_size = 0; uint32_t string_table_index = 0; uint32_t string_table_size = 0;
for (uint32_t i = 0; i < sector_header_number; ++i) { uint32_t type = 0; type = type * 256 + elf[sector_header_index + i * sector_header_length + 5]; type = type * 256 + elf[sector_header_index + i * sector_header_length + 4];
if (type == 2) { symbol_table_index = symbol_table_index * 256 + elf[sector_header_index + i * sector_header_length + 19]; symbol_table_index = symbol_table_index * 256 + elf[sector_header_index + i * sector_header_length + 18]; symbol_table_index = symbol_table_index * 256 + elf[sector_header_index + i * sector_header_length + 17]; symbol_table_index = symbol_table_index * 256 + elf[sector_header_index + i * sector_header_length + 16];
symbol_table_size = symbol_table_size * 256 + elf[sector_header_index + i * sector_header_length + 23]; symbol_table_size = symbol_table_size * 256 + elf[sector_header_index + i * sector_header_length + 22]; symbol_table_size = symbol_table_size * 256 + elf[sector_header_index + i * sector_header_length + 21]; symbol_table_size = symbol_table_size * 256 + elf[sector_header_index + i * sector_header_length + 20]; } else if (type == 3) { string_table_index = string_table_index * 256 + elf[sector_header_index + i * sector_header_length + 19]; string_table_index = string_table_index * 256 + elf[sector_header_index + i * sector_header_length + 18]; string_table_index = string_table_index * 256 + elf[sector_header_index + i * sector_header_length + 17]; string_table_index = string_table_index * 256 + elf[sector_header_index + i * sector_header_length + 16];
string_table_size = string_table_size * 256 + elf[sector_header_index + i * sector_header_length + 23]; string_table_size = string_table_size * 256 + elf[sector_header_index + i * sector_header_length + 22]; string_table_size = string_table_size * 256 + elf[sector_header_index + i * sector_header_length + 21]; string_table_size = string_table_size * 256 + elf[sector_header_index + i * sector_header_length + 20]; }
if (symbol_table_index && string_table_index) // assume break; }
// printf("%d %d %d %d\n", symbol_table_index, symbol_table_size, string_table_index, string_table_size);
func_symbol_number = 0; for (uint32_t i = 0; i < symbol_table_size / 16; ++i) { if ((elf[symbol_table_index + i * 16 + 12] & 0x0f) == 2) { vaddr_t value = 0; uint32_t size = 0; uint32_t string_index = 0;
string_index = string_index * 256 + elf[symbol_table_index + i * 16 + 3]; string_index = string_index * 256 + elf[symbol_table_index + i * 16 + 2]; string_index = string_index * 256 + elf[symbol_table_index + i * 16 + 1]; string_index = string_index * 256 + elf[symbol_table_index + i * 16 + 0];
value = value * 256 + elf[symbol_table_index + i * 16 + 7]; value = value * 256 + elf[symbol_table_index + i * 16 + 6]; value = value * 256 + elf[symbol_table_index + i * 16 + 5]; value = value * 256 + elf[symbol_table_index + i * 16 + 4];
size = size * 256 + elf[symbol_table_index + i * 16 + 11]; size = size * 256 + elf[symbol_table_index + i * 16 + 10]; size = size * 256 + elf[symbol_table_index + i * 16 + 9]; size = size * 256 + elf[symbol_table_index + i * 16 + 8];
func_symbol[func_symbol_number].value = value; func_symbol[func_symbol_number].size = size; func_symbol[func_symbol_number].string_index = string_index;
func_symbol_number++; if (func_symbol_number >= 128) { Log("Function symbol storage limit exceeded."); break; }
// printf("%x %x %x\n", value, size, string_index); } }
for (uint32_t i = 0; i < func_symbol_number; ++i) { uint32_t string_index_st = func_symbol[i].string_index; uint32_t string_index_ed = string_index_st; while(elf[string_table_index + string_index_ed]) string_index_ed++; if (string_index_ed - string_index_st + 1 > 256) panic("Function name is too long"); strncpy(func_symbol[i].name, (const char *)&elf[string_table_index + string_index_st], string_index_ed - string_index_st + 1); Assert(func_symbol[i].name[string_index_ed - string_index_st + 1] == '\0', "The string does not terminate with a zero character.");
// printf("%d %s\n", string_index_ed - string_index_st + 1, func_symbol[i].name); }
free(elf); return;}解析中硬编码的数值可以参考上面的分析,尤其需要注意字节序。
所有相关的修改都用预编译包含起来
- 修改 jal 和 jalr 指令的执行辅助函数:
#ifdef CONFIG_FTRACE #include <elf.h>
// unsigned int depth = 0;
const char *get_func_name(vaddr_t addr) { for (uint32_t i = 0; i < func_symbol_number; ++i) { if (func_symbol[i].value <= addr && addr < func_symbol[i].value + func_symbol[i].size) return func_symbol[i].name; } return NULL; }#endif
def_EHelper(jal) {#ifdef CONFIG_FTRACE vaddr_t now_pc = s->pc; rtlreg_t next_pc = id_src1->imm + s->pc; const char *name = get_func_name(next_pc); if (name != NULL) printf(FMT_PADDR ": call [%s@" FMT_PADDR "]\n", now_pc, name, next_pc); else printf(FMT_PADDR ": call [???@" FMT_PADDR "]\n", now_pc, next_pc);#endif
rtl_addi(s, ddest, &s->pc, 4); rtl_li(s, &s->dnpc, id_src1->imm + s->pc);}
def_EHelper(jalr) { vaddr_t t = s->pc + 4; vaddr_t next_pc = (id_src2->imm + *dsrc1) & ~1;
#ifdef CONFIG_FTRACE vaddr_t now_pc = s->pc; if(s->isa.instr.i.rs1 == 1 && s->isa.instr.i.rd == 0) { const char *name = get_func_name(now_pc); if (name != NULL) printf(FMT_PADDR ": ret [%s]\n", now_pc, name); else printf(FMT_PADDR ": ret [???]\n", now_pc); } else { const char *name = get_func_name(next_pc); if (name != NULL) printf(FMT_PADDR ": call [%s@" FMT_PADDR "]\n", now_pc, name, next_pc); else printf(FMT_PADDR ": call [???@" FMT_PADDR "]\n", now_pc, next_pc); }#endif
rtl_li(s, &s->dnpc, next_pc); rtl_li(s, ddest, t);}注意对 ret 做特判。
注意返回时函数名为当前 pc 所在的函数。
cbi 系指令只改变了 pc,并没有保存返回地址,所以不需要修改对应的执行辅助函数
简易调试器测试:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/nemu$ ./build/riscv32-nemu-interpreter --log=/home/vgalaxy/ics2021/nemu/build/nemu-log.txt --elf=../am-kernels/tests/cpu-tests/build/add-riscv32-nemu.elf ../am-kernels/tests/cpu-tests/build/add-riscv32-nemu.bingdb 测试:
run --log=/home/vgalaxy/ics2021/nemu/build/nemu-log.txt --elf=../am-kernels/tests/cpu-tests/build/add-riscv32-nemu.elf ../am-kernels/tests/cpu-tests/build/add-riscv32-nemu.bin调试中发现一个 bug,func_symbol 在程序运行过程中会被莫名其妙的修改,于是函数名和地址有时会出现不对应的情况:
Watchpoint 2: func_symbol
Old value = {{value = 2147484244, size = 32, string_index = 28, name = "_trm_init", '\000' <repeats 246 times>}, {value = 2147483912, size = 168, string_index = 116, name = "f3", '\000' <repeats 253 times>}, {value = 2147484080, size = 24, string_index = 119, name = "check", '\000' <repeats 250 times>}, {value = 2147483812, size = 100, string_index = 125, name = "f2", '\000' <repeats 253 times>}, {value = 2147483648, size = 0, string_index = 65, name = "_start", '\000' <repeats 249 times>}, {value = 2147484104, size = 128, string_index = 142, name = "main", '\000' <repeats 251 times>}, {value = 2147483664, size = 76, string_index = 147, name = "f0", '\000' <repeats 253 times>}, {value = 2147483740, size = 72, string_index = 165, name = "f1", '\000' <repeats 253 times>}, {value = 2147484232, size = 12, string_index = 173, name = "halt", '\000' <repeats 251 times>}, {value = 0, size = 0, string_index = 0, name = '\000' <repeats 255 times>} <repeats 119 times>}New value = {{value = 741695776, size = 808859168, string_index = 28, name = "_trm_init", '\000' <repeats 246 times>}, {value = 2147483912, size = 168, string_index = 116, name = "f3", '\000' <repeats 253 times>}, {value = 2147484080, size = 24, string_index = 119, name = "check", '\000' <repeats 250 times>}, {value = 2147483812, size = 100, string_index = 125, name = "f2", '\000' <repeats 253 times>}, {value = 2147483648, size = 0, string_index = 65, name = "_start", '\000' <repeats 249 times>}, {value = 2147484104, size = 128, string_index = 142, name = "main", '\000' <repeats 251 times>}, {value = 2147483664, size = 76, string_index = 147, name = "f0", '\000' <repeats 253 times>}, {value = 2147483740, size = 72, string_index = 165, name = "f1", '\000' <repeats 253 times>}, {value = 2147484232, size = 12, string_index = 173, name = "halt", '\000' <repeats 251 times>}, {value = 0, size = 0, string_index = 0, name = '\000' <repeats 255 times>} <repeats 119 times>}__strcpy_avx2 () at ../sysdeps/x86_64/multiarch/strcpy-avx2.S:613613 ../sysdeps/x86_64/multiarch/strcpy-avx2.S: No such file or directory.调用轨迹如下:
(gdb) bt#0 __strcpy_avx2 () at ../sysdeps/x86_64/multiarch/strcpy-avx2.S:50#1 0x00007ffff2b4efbb in _nc_first_db () from /lib/x86_64-linux-gnu/libtinfo.so.6#2 0x00007ffff2b57e37 in _nc_read_entry2 () from /lib/x86_64-linux-gnu/libtinfo.so.6#3 0x00007ffff2b51cb6 in ?? () from /lib/x86_64-linux-gnu/libtinfo.so.6#4 0x00007ffff2b52067 in _nc_setupterm () from /lib/x86_64-linux-gnu/libtinfo.so.6#5 0x00007ffff2b525ea in tgetent_sp () from /lib/x86_64-linux-gnu/libtinfo.so.6#6 0x00007ffff7f92485 in _rl_init_terminal_io () from /lib/x86_64-linux-gnu/libreadline.so.8#7 0x00007ffff7f74410 in rl_initialize () from /lib/x86_64-linux-gnu/libreadline.so.8#8 0x00007ffff7f746d5 in readline () from /lib/x86_64-linux-gnu/libreadline.so.8#9 0x000055555555c354 in rl_gets () at src/monitor/sdb/sdb.c:29#10 sdb_mainloop () at src/monitor/sdb/sdb.c:189#11 0x000055555555d3bb in engine_start () at src/engine/interpreter/init.c:10#12 0x0000555555558f14 in main (argc=<optimized out>, argv=<optimized out>) at src/nemu-main.c:21似乎是 readline 库在捣乱。于是在 control.h 中拷贝一个文件全局变量:
bool is_init = false; static elf_func_symbol local_func_symbol[128];
void init_func_symbol() { for (uint32_t i = 0; i < func_symbol_number; ++i) { local_func_symbol[i] = func_symbol[i]; }
is_init = true; }问题便解决了。
另外,函数调用和返回也可能出现不匹配的情况,如 recursion.c:
int f0(int, int);int f1(int, int);int f2(int, int);int f3(int, int);
int (*func[])(int, int) = { f0, f1, f2, f3,};
int rec = 0, lvl = 0;
int f0(int n, int l) { if (l > lvl) lvl = l; rec ++; return n <= 0 ? 1 : func[3](n / 3, l + 1);};
int f1(int n, int l) { if (l > lvl) lvl = l; rec ++; return n <= 0 ? 1 : func[0](n - 1, l + 1);};
int f2(int n, int l) { if (l > lvl) lvl = l; rec ++; return n <= 0 ? 1 : func[1](n, l + 1) + 9;};
int f3(int n, int l) { if (l > lvl) lvl = l; rec ++; return n <= 0 ? 1 : func[2](n / 2, l + 1) * 3 + func[2](n / 2, l + 1) * 2;};部分调用轨迹如下:
0x8000000c: call [_trm_init@0x80000254]0x80000264: call [main@0x800001c8]0x800001ec: call [f0@0x80000010]0x80000050: call [f3@0x80000108]0x8000016c: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000050: call [f3@0x80000108]0x8000016c: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000050: call [f3@0x80000108]0x8000016c: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000050: call [f3@0x80000108]0x8000016c: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000050: call [f3@0x80000108]0x8000016c: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000058: ret [f0]0x80000100: ret [f2]0x80000180: call [f2@0x800000a4]0x800000f0: call [f1@0x8000005c]0x80000098: call [f0@0x80000010]0x80000058: ret [f0]0x80000100: ret [f2]0x800001a8: ret [f3]0x80000100: ret [f2]TODO
显式传参太过麻烦,也容易出问题,考虑修改 Makefile 文件:
TODO
AM - native - klibtest
AM 的思想保证了运行在 AM 之上的代码 (包括 klib) 都是架构无关的,这恰恰增加了代码的可移植性。
abstract-machine 中有一个特殊的架构叫 native,是用 GNU/Linux 默认的运行时环境来实现的 AM API。
因此,与其在 $ISA-nemu 中直接调试软件,还不如在 native 上把软件调对,然后再换到 $ISA-nemu 中运行,来对 NEMU 进行测试。
这里的软件便是我们的 klib 实现
框架代码编译到 native 的时候默认链接到 glibc,我们需要把这些库函数的调用链接到我们编写的 klib 来进行测试,我们可以通过在 abstract-machine/klib/include/klib.h 中通过定义宏 __NATIVE_USE_KLIB__ 来把库函数链接到 klib。
#define __NATIVE_USE_KLIB__在 klib 中,需要大家实现的函数主要分成三类:
- 内存和字符串的写入函数,例如
memset(),strcpy()等 - 内存和字符串的只读函数,例如
memcmp(),strlen()等 - 格式化输出函数,例如
sprintf()等
framework
我们在 am-kernels/tests/ 目录下新增一个针对 klib 的测试集 klib-tests,测试集的文件结构参考了 am-kernels/tests/am-tests:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/klib-tests$ tree.├── build│ ├── klibtest-native│ └── native│ └── src│ ├── main.d│ ├── main.o│ └── tests│ ├── test_memset.d│ └── test_memset.o├── include│ └── klibtest.h├── Makefile└── src ├── main.c └── tests └── test_memset.c
7 directories, 9 files其中 klibtest.h 如下:
#ifndef __KLIBUNIT_H__#define __KLIBUNIT_H__
#include <am.h>#include <klib.h>#include <klib-macros.h>
extern void (*entry)();
#define CASE(id, entry_, ...) \ case id: { \ void entry_(); \ entry = entry_; \ __VA_ARGS__; \ entry_(); \ break; \ }
#endif为什么叫
__KLIBUNIT_H__,因为 amtest.h 就像这样…
Makefile 如下:
NAME = klibtestSRCS = $(shell find src/ -name "*.[cS]")include $(AM_HOME)/Makefilemain.c 如下:
#include <klibtest.h>
void (*entry)() = NULL; // mp entry
static const char *tests[256] = { ['H'] = "display this help message", ['a'] = "test_memset",};
int main(const char *args) { switch (args[0]) { CASE('a', test_memset); case 'H': default: printf("Usage: make run mainargs=*\n"); for (int ch = 0; ch < 256; ch++) { if (tests[ch]) { printf(" %c: %s\n", ch, tests[ch]); } } } return 0;}这样我们就能通过如下方式进行测试了:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/klib-tests$ make ARCH=native run mainargs=a这里的 mainargs 代表传入给 main 函数的参数。
注意当使用 native + klib 的组合时,由于 native 的初始化代码也会调用 klib,所以若未实现 stdio.h 和 stdlib.h,就会报段错误,panic("Not implemented"),然而输出未实现,根本打印不出来,然后继续 panic 递归,笑死…
- malloc,参考 microbench 中的 bench_alloc 函数:
其中 ROUNDUP 定义在 klib-macros.h 中
- printf,一看是 IOE,麻了…
所以若是测试 klib 中 string.h 的实现,可以使用 native + klib 的组合,并将 stdio.h 和 stdlib.h 的预编译改为:
#if !defined(__ISA_NATIVE__) || !defined(__NATIVE_USE_KLIB__)这样 stdio.h 和 stdlib.h 也许就会链接到默认的 glibc。
测试可以正常工作,但是使用 gdb 调试的时候会有问题:
这个信号出现在 abstract-machine/am/src/native/platform.c 中,是 Linux 内核的自定义信号:
User defined signals means that these signals have no definite meaning unlike
SIGSEGV,SIGCONT,SIGSTOP, etc. The kernel will never send SIGUSR1 or SIGUSR2 to a process, so the meaning of the signal can be set by you as per the needs of your application.
另外我们也可以得出,若 ISA 不是 native,那么库函数一定是 klib。
然而,riscv32-nemu + klib 会出现 __strcpy_avx2 修改了监视点中 head 指针的值,导致 -> 触发段错误。
调试如下:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/klib-tests$ gdb ../../../nemu/build/riscv32-nemu-interpreter(gdb) watch headHardware watchpoint 1: head(gdb) run --log=/home/vgalaxy/ics2021/nemu/build/nemu-log.txt ./build/klibtest-riscv32-nemu.bin为此我们忍气吞声的将监视点相关的代码注释掉,就可以运行了…
然而调试时,为 memset 打断点会遇到:
Breakpoint 1, __memset_avx2_unaligned () at ../sysdeps/x86_64/multiarch/memset-vec-unaligned-erms.S:98调试时如何传入 mainargs 参数?
注:调试不应使用 gdb,而应使用 nemu 的简易调试器,mainargs 为上一次 run 时传入的参数
测试框架搭好之后,我们来看看如何设计测试用例。
test_memset
#include <klibtest.h>
#define N 32uint8_t data[N];
void reset() { int i; for (i = 0; i < N; i ++) { data[i] = i + 1; }}
// 检查 [l,r) 区间中的值是否依次为 val, val + 1, val + 2...void check_seq(int l, int r, int val) { int i; for (i = l; i < r; i ++) { assert(data[i] == val + i - l); }}
// 检查 [l,r) 区间中的值是否均为 valvoid check_eq(int l, int r, int val) { int i; for (i = l; i < r; i ++) { assert(data[i] == val); }}
void test_memset() { int l, r; for (l = 0; l < N; l ++) { for (r = l + 1; r <= N; r ++) { reset(); uint8_t val = (l + r) / 2; memset(data + l, val, r - l); check_seq(0, l, 1); check_eq(l, r, val); check_seq(r, N, r + 1); } }}大概思想就是让一个数组每个元素的值各不相同,然后对所有可能的连续序列进行 memset,并对序列前、序列中和序列后进行检查。
其中的 assert 定义在 klib.h 中。
test_memcpy
似乎写的挺弱的,注意同名函数使用 static 修饰:
void test_memcpy() { int l, r; for (l = 0; l < N; l ++) { for (r = l + 1; r < N; r ++) { reset(); int seq = (r - l) / 2; if (r + seq >= N) continue; memcpy(data + r, data + l, seq); check_seq(l, l + seq, l + 1); check_seq(r, r + seq, l + 1); } }}test_memmove
TODO
mem 系测试完后,strcpy、strncpy 和 strcat 应该就没什么问题了。
test_strlen
static void reset() { int i; for (i = 0; i < N; i ++) { data[i] = 0; }}
void test_strlen() { reset(); for (int i = 0; i < N - 1; ++i) { size_t before = strlen(data); strcat(data, "a"); size_t after = strlen(data); assert(after - before == 1); }}test_memcmp
static void reset() { int i; for (i = 0; i < N; i ++) { data[i] = 0; }}
void test_memcmp() { reset(); for (int i = 0; i < N - 1; ++i) { assert(memcmp(data, strcat(data, "a"), i + 1) == 0); }}test_sprintf
#include <klibtest.h>
__attribute__((noinline))static void check(bool cond) { if (!cond) halt(1);}
static char buf[1024];
void test_sprintf() { int res = sprintf(buf, "%s", "Hello world!\n"); check(res == 13); check(strcmp(buf, "Hello world!\n") == 0);
res = sprintf(buf, "%d + %d = %d\n", 1, 1, 2); check(res == 10); check(strcmp(buf, "1 + 1 = 2\n") == 0);
res = sprintf(buf, "%d + %d = %d\n", 2, 10, 12); check(res == 12); check(strcmp(buf, "2 + 10 = 12\n") == 0);}make run 设置 mainargs 后,可以打开 ftrace 进行调试:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/klib-tests$ /home/vgalaxy/ics2021/nemu/build/riscv32-nemu-interpreter -l /home/vgalaxy/ics2021/am-kernels/tests/klib-tests/build/nemu-log.txt -e /home/vgalaxy/ics2021/am-kernels/tests/klib-tests/build/klibtest-riscv32-nemu.elf /home/vgalaxy/ics2021/am-kernels/tests/klib-tests/build/klibtest-riscv32-nemu.binDifferential Testing
通常来说,进行 DiffTest 需要提供一个和 DUT (Design Under Test,测试对象) 功能相同但实现方式不同的 REF (Reference,参考实现),然后让它们接受相同的有定义的输入,观测它们的行为是否相同。
在这里,我们需要观测的行为是每一条指令的执行。
粒度更细致了——我们不仅仅是对比程序运行的结果,而是对比每条指令的行为
要检查指令的实现是否正确,只要检查执行指令之后 DUT 和 REF 的状态是否一致就可以了。这里的状态可以编码为一个二元组 S = <R, M>,其中 R 是寄存器的值,M 是内存的值。
为了方便实现 DiffTest,我们在 DUT 和 REF 之间定义了如下的一组 API:
// 在 DUT host memory 的 `buf` 和 REF guest memory 的 `dest` 之间拷贝 `n` 字节,// `direction` 指定拷贝的方向,`DIFFTEST_TO_DUT` 表示往 DUT 拷贝,`DIFFTEST_TO_REF` 表示往 REF 拷贝void difftest_memcpy(paddr_t addr, void *buf, size_t n, bool direction);// `direction` 为 `DIFFTEST_TO_DUT` 时,获取 REF 的寄存器状态到 `dut`;// `direction` 为 `DIFFTEST_TO_REF` 时,设置 REF 的寄存器状态为 `dut`;void difftest_regcpy(void *dut, bool direction);// 让 REF 执行 `n` 条指令void difftest_exec(uint64_t n);// 初始化 REF 的 DiffTest 功能void difftest_init();REF 需要实现这些 API,DUT 会使用这些 API 来进行 DiffTest。在这里,DUT 和 REF 分别是 NEMU 和其它模拟器。对于 riscv32 而言,框架代码的 REF 为 Spike。
我们还需要在 menuconfig 中打开相应的选项。
另外,寄存器状态 dut 要求寄存器的成员按照某种顺序排列,若未按要求顺序排列,difftest_regcpy() 的行为是未定义的。
REF 实现的顺序为,首先是 32 个整数寄存器组,然后是 pc 寄存器:
struct diff_context_t { word_t gpr[32]; word_t pc;};对应的 NEMU 实现中也是这个顺序:
typedef struct { struct { rtlreg_t _32; } gpr[32];
vaddr_t pc;} riscv32_CPU_state;nemu/tools/difftest.mk 中已经设置了相应的规则和参数,会自动进入 nemu/tools/ 下的相应子目录 (kvm-diff, qemu-diff 或 spike-diff) 编译动态库,并把其作为 NEMU 的 --diff 选项的参数传入。
打开 DiffTest 后,nemu/src/cpu/difftest/dut.c 中的 init_difftest() 会额外进行一些初始化工作。
进行了初始化工作之后,DUT 和 REF 就处于相同的状态了。接下来就可以进行逐条指令执行后的状态对比了,实现这一功能的是 nemu/src/cpu/difftest/dut.c 中的 difftest_step() 函数,其中调用了 checkregs->isa_difftest_checkregs 函数检查寄存器的状态,这是一个 ISA 相关的函数,在 nemu/src/isa/$ISA/difftest/dut.c 中定义。
其实现非常简单,记得多提供一些信息:
bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc) { for (int i = 0; i < 32; ++i) { if (ref_r->gpr[i]._32 != cpu.gpr[i]._32) { Log("At %s -> REF: " FMT_WORD ", DUT: " FMT_WORD, reg_name(i, 0), ref_r->gpr[i]._32, cpu.gpr[i]._32); return false; } } if (ref_r->pc != cpu.pc) { Log("At pc -> REF: " FMT_WORD ", DUT: " FMT_WORD, ref_r->pc, cpu.pc); return false; } return true;}传入的参数 pc 有啥用?
reg_name 的第二个参数有啥用?
make run 时会奇怪的依赖循环:
Makefile:349: warning: overriding recipe for target 'disasm.o'Makefile:349: warning: ignoring old recipe for target 'disasm.o'make[4]: Circular libcustomext.so <- libcustomext.so dependency dropped.make[4]: Circular libsoftfloat.so <- libsoftfloat.so dependency dropped.可以观察到传入的参数
--diff=/home/vgalaxy/ics2021/nemu/tools/spike-diff/build/riscv32-spike-so我们破坏 addi 指令来测试一下:
vgalaxy@vgalaxy-VirtualBox:~/ics2021/am-kernels/tests/cpu-tests$ make ARCH=riscv32-nemu ALL=add run...[src/cpu/cpu-exec.c:145 cpu_exec] nemu: ABORT at pc = 0x80000000结果开局就自爆了,因为第一条指令 li 的实现依赖 addi。
另外有几点要说明:
- Spike 不支持不对齐的访存
- 由于 DiffTest 需要与 REF 进行通信并让 REF 执行指令,会降低 NEMU 的运行速度
- 我们实现的 DiffTest 并不是完整地对比 REF 和 NEMU 的状态(例如对比内存),也就是说,我们牺牲了一些比较的精度,来换取性能的提升
- NEMU 的简化会导致某些指令的行为与 REF 有所差异,因而无法进行对比(如
nemu_trap指令)。为了解决这个问题,框架中准备了difftest_skip_ref()和difftest_skip_dut()这两个函数
NEMU 的本质
通用程序 (Universal Program):一个用来执行其它程序的程序
- 通用程序的存在性为计算机的出现奠定了理论基础——机器永远是对的
- 计算机就是一个通用程序的实体化
- NEMU 和各种模拟器只不过是通用程序的实例化
计算的极限这一系列科普文章叙述了可计算理论的发展过程
捕捉死循环
TODO
至此,AM 的 TRM 部分圆满结束。