TOC
Open TOC
info
https://sp21.datastructur.es/materials/proj/proj2/proj2
https://github.blog/2022-08-29-gits-database-internals-i-packed-object-store/
https://benhoyt.com/writings/pygit/
setup
- Spring 2021 Project 2
- entry code: BP25V6
- 无需使用 library-sp21
- Autograder 的 Java 版本介于 Java 11 和 Java 17 之间
intro
下面的内容主要参考了 https://git-scm.com/book/en/v2/Git-Internals-Plumbing-and-Porcelain
我们平时使用的一般是 Git 的上层 (porcelain) 命令,如 add / commit / checkout 等
实际上,这些上层命令是通过调用一系列的底层 (plumbing) 命令实现的
下面简单写一下 Git 底层存储原理
Git 仓库对应的目录下会存在一个 .git 文件夹,其中的目录结构如下
.├── branches├── config├── description├── HEAD├── hooks├── index├── info├── objects└── refs ├── heads └── tags我们主要关注如下内容
HEAD 文件
其内容为
ref: refs/heads/master其中 master 代表当前分支名
本质上,HEAD 文件通常是一个符号引用 (symbolic reference),指向目前所在的分支
所谓符号引用,表示它是一个指向其他引用的指针
可以通过如下命令来查看 HEAD 引用对应的值
index 文件
以某种文件格式存储了暂存区 (staging area) 的信息
objects 文件夹
以某种文件格式了存储下述三种 Git 对象
数据对象 (blob object)
我们使用 hash-object 底层命令创建一个新的数据对象
> echo 'test content' | git hash-object -w --stdind670460b4b4aece5915caf5c68d12f560a9fe3e4此命令输出一个长度为 40 个字符的校验和,一个将待存储的数据外加一个头部信息 (header) 一起做 SHA-1 校验运算而得的校验和
实际数据的存储位置如下,校验和的前两位会作为文件夹名,用于加速搜索
> find .git/objects -type f.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4而实际存储的内容使用了 zlib 压缩
可以使用 cat-file 底层命令读取对应的数据
> git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4test content> git cat-file -t d670460b4b4aece5915caf5c68d12f560a9fe3e4blob树对象 (tree object)
树对象和暂存区关系密切
我们使用 update-index 命令将上述数据对象加入到暂存区,并命名为 hello
> git update-index --add --cacheinfo 100644 d670460b4b4aece5915caf5c68d12f560a9fe3e4 hello然后使用 write-tree 命令将暂存区内容写入一个树对象
> git write-tree5c37b5e44991f39108f42f4b1437ce17bc64d305使用 cat-file 底层命令读取对应的数据
> git cat-file -p 5c37b5e44991f39108f42f4b1437ce17bc64d305100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 hello> git cat-file -t 5c37b5e44991f39108f42f4b1437ce17bc64d305tree注意到树对象中不仅可以包含数据对象,也可以包含树对象,这种递归抽象出了文件夹的结构
例如,我们可以将上述树对象读入暂存区,并命名为 bak
> git read-tree --prefix=bak 5c37b5e44991f39108f42f4b1437ce17bc64d305> git write-tree45e6bd06efe617fea53b305cf881c4f37f5ed9f0使用 cat-file 底层命令读取对应的数据
> git cat-file -p 45e6bd06efe617fea53b305cf881c4f37f5ed9f0040000 tree 5c37b5e44991f39108f42f4b1437ce17bc64d305 bak100644 blob d670460b4b4aece5915caf5c68d12f560a9fe3e4 hello> git cat-file -t 45e6bd06efe617fea53b305cf881c4f37f5ed9f0tree实际上当前的暂存区目录结构如下
.├── bak│ └── hello└── hello提交对象 (commit object)
可以使用 commit-tree 底层命令创建一个提交对象
在第一次提交中,只需要指定一个树对象
> echo 'first commit' | git commit-tree 45e6bd06efe617fea53b305cf881c4f37f5ed9f0071952dacf30d046be522bf40cdde3ed707ecc9e使用 cat-file 底层命令读取对应的数据
> git cat-file -p 071952dacf30d046be522bf40cdde3ed707ecc9etree 45e6bd06efe617fea53b305cf881c4f37f5ed9f0author V_Galaxy <1904821183@qq.com> 1673506799 +0800committer V_Galaxy <1904821183@qq.com> 1673506799 +0800
first commit> git cat-file -t 071952dacf30d046be522bf40cdde3ed707ecc9ecommit我们可以用 log 上层命令查看该提交对象的信息
> git log --stat 071952dacf30d046be522bf40cdde3ed707ecc9ecommit 071952dacf30d046be522bf40cdde3ed707ecc9eAuthor: V_Galaxy <1904821183@qq.com>Date: Thu Jan 12 14:59:59 2023 +0800
first commit
bak/hello | 1 + hello | 1 + 2 files changed, 2 insertions(+)refs 文件夹
目前只关注其中的 heads 文件夹,里面的文件以分支命名,其内容为某个提交对象的 SHA-1 校验和
例如,可以通过如下方式更新 master 分支对应的提交对象
> git update-ref refs/heads/master 071952dacf30d046be522bf40cdde3ed707ecc9e若当前分支为 master 分支,可以直接使用 git log 查看对应的信息
Summary
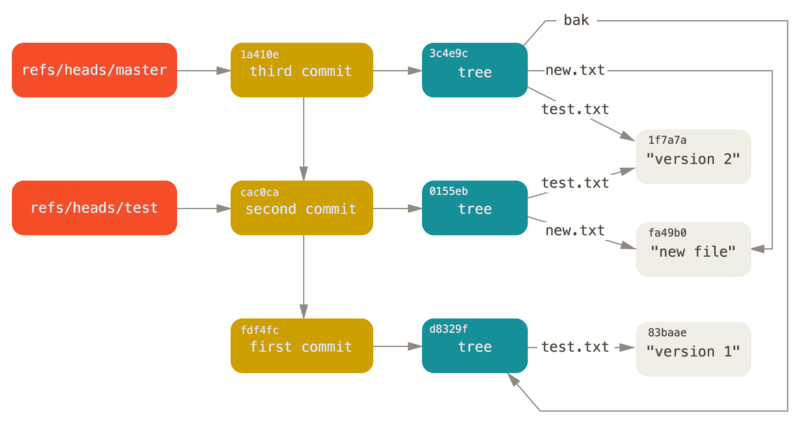
design
由于 Gitlet 支持的特性和 Git 不完全相同,所以对于文件存储的设计如下
- 由于无需考虑文件夹,所以不必存储树对象
- 为了更好的区分数据对象和提交对象,将数据对象存储在
.gitlet/objects/blobs中,将提交对象存储在.gitlet/objects/commits中 - 为了简化解析,HEAD 文件的内容为
refs/heads/master,即不包含ref: - 不考虑 Git 对应的文件格式
- 数据对象的存储不使用 zlib 压缩,直接存储纯文本
- 提交对象和
index文件的存储利用 Java 对象序列化
使用 TreeMap<String, String> 模拟树对象这一层抽象,即维护下述映射关系,抽象为 Mapping 类
filename -> sha1每一个提交对象,即 Commit 类,都包含一个Mapping 类对象的实例
暂存区对象,即 Stage 类,也包含一个 Mapping 类对象的实例
我们以 Gitlet 支持的 rm 上层命令为例,描述上述框架运行的流程
- 检测当前工作目录中是否存在
.gitlet文件夹 - 反序列化当前 HEAD 文件所指向分支对应的提交对象和
index文件,获得对应的Mapping对象,分别记为stageMapping和headMapping - 在
stageMapping和headMapping中寻找需要 remove 的 filename,分为下述四种情形stageFind == null && headFind == null报错stageFind != null && headFind == null在stageMapping中删除 filename 对应的条目,同时删除对应的数据文件 (相当于将该文件移出暂存区,但是不影响源文件)stageFind == null && headFind != null在stageMapping中插入条目(filename, EMPTY),同时删除对应的源文件 (可能已经被 UNIX rm 命令删除了)stageFind != null && headFind != null报错
- 序列化
stageMapping到index文件中
在 commit 的时候,会利用 Mapping 类提供的 merge 方法,合并当前 HEAD 文件所指向分支对应的提交对象和 index 文件中的 Mapping 对象,形成一个新的 Mapping 对象,从而构造新的提交对象,上述 (filename, EMPTY) 条目即提示在合并的时候删除该文件
更具体的,当 stageMapping 中出现条目 (filename, sha1) 时
- 可能是当前分支中不存在文件名为 filename 的文件
- 也可能是文件名为 filename 的文件内容发生了变化
这种版本的比较,在 status 上层命令中表现的更加明显
merge
下面主要分析一下 merge 上层命令的实现,先做如下记号
- 当前分支为 master
- 被合并的分支为 other
- master 分支和 other 分支的最近公共祖先 (LCA) 为 split
对于 LCA 的求解,可以参考 https://zhuanlan.zhihu.com/p/113042043
首先,merge 要求当前暂存区为空,即
- 不存在 Untracked Files
- 不存在 Uncommitted Changes,包括
- Staged Files
- Removed Files
- Modifications Not Staged For Commit
然后,需要判断 split 和 master 分支和 other 分支的关系
- 若 split 等同于 master 分支,则直接 checkout 到 other 分支即可
- 若 split 等同于 other 分支,则 merge 已经完成
若并非上述两种平凡的情形,则根据这个视频的描述处理即可
这一部分有比较困难的用例,包括
test36-merge-parent2.intest43-criss-cross-merge.intest43-criss-cross-merge-b.in
以 test36-merge-parent2.in 为例

两次 merge 分别是
- 在 B1 分支合并 C1 分支
- 在 B1 分支合并 B2 分支
需要注意第二次 merge 的结果,B1 分支和 B2 分支的最近公共祖先为 init,如果不考虑历史信息,那么合并的结果为
h (wug)f (wug)g (notwug)然而注意到从 C1 分支 checkout 到 B2 分支,所需要进行的操作是 rm f (wug) 和 add g (notwug),所以相当于对
h (wug)f (wug)执行相同的操作,所以应该为
h (wug)g (notwug)另一个例子是 test43-criss-cross-merge.in

可以发现 given 分支的 parent commit 会影响 merge 的结果
所以在 merge 过程,仅使用 master / other / split 这些 Commit 对象的信息是不够的
TODO
test
在项目根目录下使用 make 构建项目,使用 make check 进行测试
测试框架定义了一种 domain-specific language (DSL),在此基础上编写测试脚本
本质上是包含上下文信息的正则表达式
- 源文件,在
src文件夹内 - 测试脚本,在
samples文件夹内 - 测试驱动器,为
tester.py,实现了对上述 domain-specific language 的解析