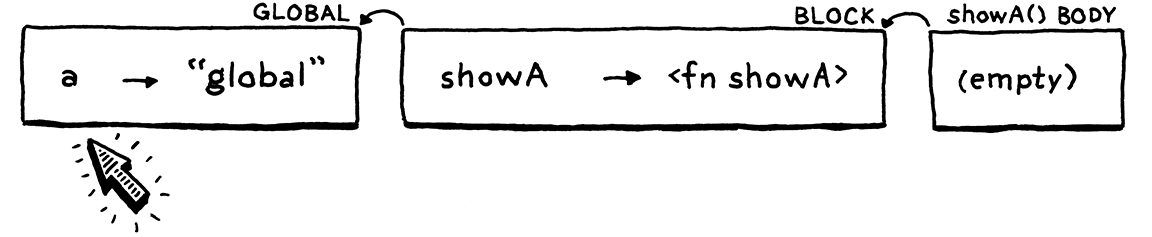
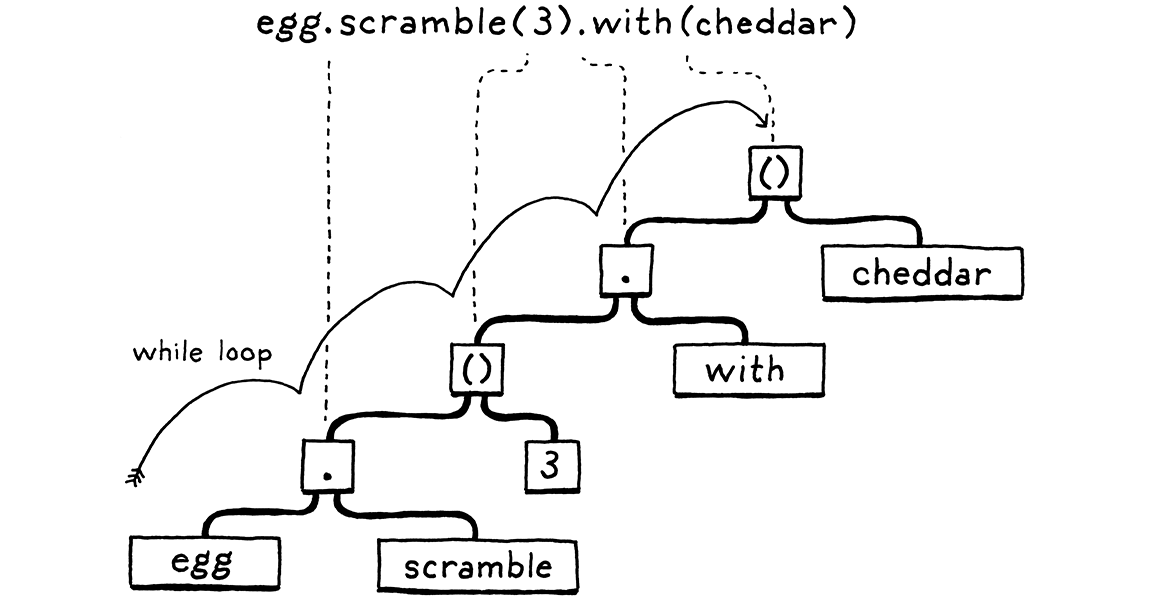
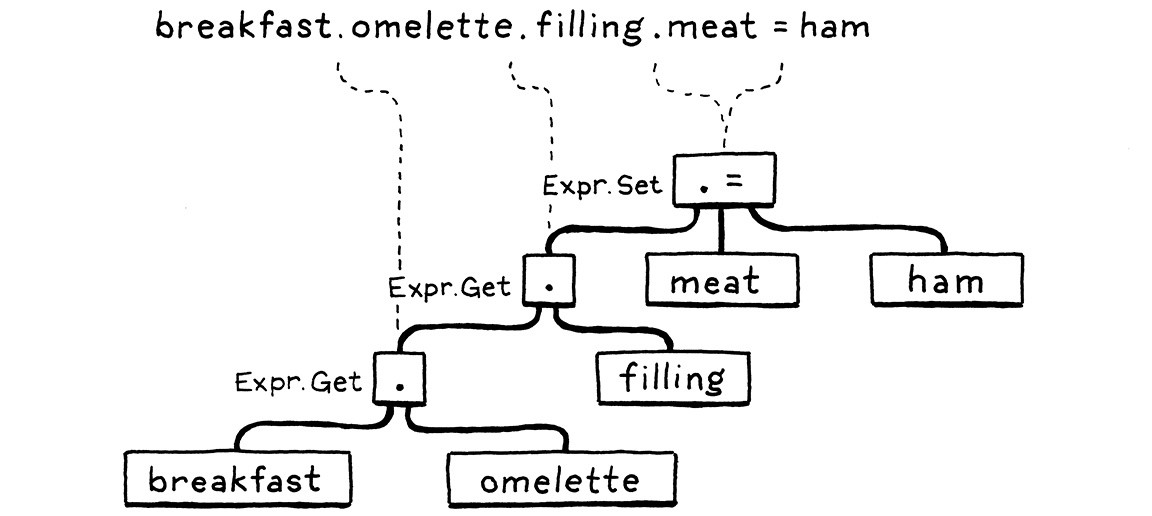
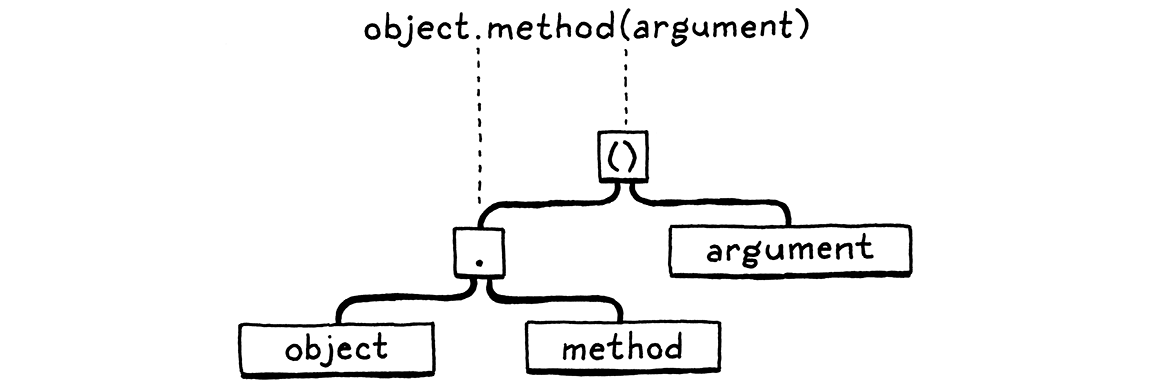
An expression statement lets you place an expression where a statement is expected.
A print statement evaluates an expression and displays the result to the user.
Pascal is an outlier. It distinguishes between procedures and functions. Functions return values, but procedures cannot. There is a statement form for calling a procedure, but functions can only be called where an expression is expected. There are no expression statements in Pascal.
You could make a language that treats variable declarations as expressions that both create a binding and produce a value. The only language I know that does that is Tcl. Scheme seems like a contender, but note that after a let expression is evaluated, the variable it bound is forgotten. The define syntax is not an expression.
简单起见,我们这里的变量指的是全局变量。引入全局变量需要三个东西:
变量声明语句
变量表达式
环境
由于变量声明语句并不是能出现在所有语句可以出现的地方,例如在 if 语句的分句中不能出现变量声明语句(我们这样规定),于是某种程度上语句也有所谓优先级之分。
Some places where a statement is allowed - like inside a block or at the top level - allow any kind of statement, including declarations. Others allow only the “higher” precedence statements that don’t declare names.
In this analogy, block statements work sort of like parentheses do for expressions. A block is itself in the “higher” precedence level and can be used anywhere, like in the clauses of an if statement. But the statements it contains can be lower precedence. You’re allowed to declare variables and other names inside the block. The curlies let you escape back into the full statement grammar from a place where only some statements are allowed.
My rule about variables and scoping is, “When in doubt, do what Scheme does”. The Scheme folks have probably spent more time thinking about variable scope than we ever will - one of the main goals of Scheme was to introduce lexical scoping to the world - so it’s hard to go wrong if you follow in their footsteps.
Scheme allows redefining variables at the top level.
We could accommodate single recursion - a function that calls itself - by declaring the function’s own name before we examine its body. But that doesn’t help with mutually recursive procedures that call each other. Consider:
fun isOdd(n) {
if (n == 0) return false;
return isEven(n - 1);
}
fun isEven(n) {
if (n == 0) return true;
return isOdd(n - 1);
}
The isEven() function isn’t defined by the time we are looking at the body of isOdd() where it’s called. If we swap the order of the two functions, then isOdd() isn’t defined when we’re looking at isEven()’s body.
Some statically typed languages like Java and C# solve this by specifying that the top level of a program isn’t a sequence of imperative statements. Instead, a program is a set of declarations which all come into being simultaneously. The implementation declares all of the names before looking at the bodies of any of the functions.
Older languages like C and Pascal don’t work like this. Instead, they force you to add explicit forward declarations to declare a name before it’s fully defined. That was a concession to the limited computing power at the time. They wanted to be able to compile a source file in one single pass through the text, so those compilers couldn’t gather up all of the declarations first before processing function bodies.
The trick is that right before we create the assignment expression node, we look at the left-hand side expression and figure out what kind of assignment target it is. We convert the r-value expression node into an l-value representation.
This conversion works because it turns out that every valid assignment target happens to also be valid syntax as a normal expression.
You can still use this trick even if there are assignment targets that are not valid expressions. Define a cover grammar, a looser grammar that accepts all of the valid expression and assignment target syntaxes. When you hit an =, report an error if the left-hand side isn’t within the valid assignment target grammar. Conversely, if you don’t hit an =, report an error if the left-hand side isn’t a valid expression.
这里的解释有点怪,下面的旁注也看不懂 🤣。
Way back in the parsing chapter, I said we represent parenthesized expressions in the syntax tree because we’ll need them later. This is why. We need to be able to distinguish these cases:
Manually changing and restoring a mutable environment field feels inelegant. Another classic approach is to explicitly pass the environment as a parameter to each visit method. To “change” the environment, you pass a different one as you recurse down the tree. You don’t have to restore the old one, since the new one lives on the Java stack and is implicitly discarded when the interpreter returns from the block’s visit method.
I considered that for jlox, but it’s kind of tedious and verbose adding an environment parameter to every single visit method. To keep the book a little simpler, I went with the mutable field.
The REPL no longer supports entering a single expression and automatically printing its result value. That’s a drag. Add support to the REPL to let users type in both statements and expressions. If they enter a statement, execute it. If they enter an expression, evaluate it and display the result value.
我们只需要保留对表达式的 parse 方法和 interpret 方法:
Expr parse() {
try {
return expression();
} catch (ParseError error) {
return null;
}
}
void interpret(Expr expression) {
try {
Object value = evaluate(expression);
System.out.println(stringify(value));
} catch (RuntimeError error) {
Lox.runtimeError(error);
}
}
然后在 Lox 类的 runPrompt 中添加分支判断输入的是语句还是表达式。
2
Maybe you want Lox to be a little more explicit about variable initialization. Instead of implicitly initializing variables to nil, make it a runtime error to access a variable that has not been initialized or assigned to, as in:
// No initializers.
var a;
var b;
a = "assigned";
print a; // OK, was assigned first.
print b; // Error!
简单修改getter方法即可:
Object get(Token name) {
if (values.containsKey(name.lexeme)) {
Object res = values.get(name.lexeme);
if (res == null) {
throw new RuntimeError(name, "Uninitialized variable '" + name.lexeme + "'.");
}
return res;
}
if (enclosing != null) return enclosing.get(name);
throw new RuntimeError(name, "Undefined variable '" + name.lexeme + "'.");
}
3
What does the following program do?
var a = 1;
{
var a = a + 2;
print a;
}
What did you expect it to do? Is it what you think it should do? What does analogous code in other languages you are familiar with do? What do you think users will expect this to do?
与下面的 while 语句几乎等价(加上了 continue 语句就不一定了),注意最外层的括号,因为循环变量的作用域问题:
{
var i = 0;
while (i < 10) {
print i;
i = i + 1;
}
}
于是,我们先定义 for 语句的语法规则:
statement → exprStmt
| forStmt
| ifStmt
| printStmt
| whileStmt
| block ;
forStmt → "for" "(" ( varDecl | exprStmt | ";" )
expression? ";"
expression? ")" statement ;
Inside the parentheses, you have three clauses separated by semicolons:
The first clause is the initializer. It is executed exactly once, before anything else. It’s usually an expression (stmt), but for convenience, we also allow a variable declaration. In that case, the variable is scoped to the rest of the for loop - the other two clauses and the body.
Next is the condition. As in a while loop, this expression controls when to exit the loop. It’s evaluated once at the beginning of each iteration, including the first. If the result is truthy, it executes the loop body. Otherwise, it bails.
The last clause is the increment. It’s an arbitrary expression that does some work at the end of each loop iteration. The result of the expression is discarded, so it must have a side effect to be useful. In practice, it usually increments a variable.
In a previous chapter, I said we can split expression and statement syntax trees into two separate class hierarchies because there’s no single place in the grammar that allows both an expression and a statement. That wasn’t entirely true, I guess.
consume(SEMICOLON,"Expect ';' after loop condition.");
Expr increment =null;
if (!check(RIGHT_PAREN)) {
increment =expression();
}
consume(RIGHT_PAREN,"Expect ')' after for clauses.");
Stmt body =statement();
if (increment !=null) {
body =new Stmt.Block(Arrays.asList(body, new Stmt.Expression(increment)));
}
if (condition ==null) condition =new Expr.Literal(true);
body =new Stmt.While(condition, body);
if (initializer !=null) {
body =new Stmt.Block(Arrays.asList(initializer, body));
}
return body;
}
总结来说,先正向匹配,再反向组合。
Most modern languages have a higher-level looping statement for iterating over arbitrary user-defined sequences. C# has foreach, Java has “enhanced for” , even C++ has range-based for statements now. Those offer cleaner syntax than C’s for statement by implicitly calling into an iteration protocol that the object being looped over supports.
I love those. For Lox, though, we’re limited by building up the interpreter a chapter at a time. We don’t have objects and methods yet, so we have no way of defining an iteration protocol that the for loop could use. So we’ll stick with the old school C for loop. Think of it as “vintage”. The fixie of control flow statements.
习题
A few chapters from now, when Lox supports first-class functions and dynamic dispatch, we technically won’t need branching statements built into the language. Show how conditional execution can be implemented in terms of those. Name a language that uses this technique for its control flow.
Likewise, looping can be implemented using those same tools, provided our interpreter supports an important optimization. What is it, and why is it necessary? Name a language that uses this technique for iteration.
Unlike Lox, most other C-style languages also support break and continue statements inside loops. Add support for break statements.
The syntax is a break keyword followed by a semicolon. It should be a syntax error to have a break statement appear outside of any enclosing loop. At runtime, a break statement causes execution to jump to the end of the nearest enclosing loop and proceeds from there. Note that the break may be nested inside other blocks and if statements that also need to be exited.
These are functions that the interpreter exposes to user code but that are implemented in the host language (in our case Java), not the language being implemented (Lox).
In Java, “native” methods are ones implemented in C or C++ and compiled to native machine code.
本地方法的意义是提供了程序对基本服务的访问,如文件操作、输入和输出等。
Many languages also allow users to provide their own native functions. The mechanism for doing so is called a foreign function interface (FFI), native extension, native interface, or something along those lines. These are nice because they free the language implementer from providing access to every single capability the underlying platform supports.
public String toString() { return "<native fn>"; }
});
}
注意这里对应环境字段的变化,从:
private Environment environment = new Environment();
变成了:
final Environment globals = new Environment();
private Environment environment = globals;
这样确保了这个函数是在全局范围内定义的。
The environment field in the interpreter changes as we enter and exit local scopes. It tracks the current environment. This new globals field holds a fixed reference to the outermost global environment.
另外注意到函数和变量的环境在一个地方:
In Lox, functions and variables occupy the same namespace. In Common Lisp, the two live in their own worlds. A function and variable with the same name don’t collide. If you call the name, it looks up the function. If you refer to it, it looks up the variable. This does require jumping through some hoops when you do want to refer to a function as a first-class value.
Richard P. Gabriel and Kent Pitman coined the terms “Lisp-1” to refer to languages like Scheme that put functions and variables in the same namespace, and “Lisp-2” for languages like Common Lisp that partition them. Despite being totally opaque, those names have since stuck. Lox is a Lisp-1.
函数声明语句
A named function declaration isn’t really a single primitive operation. It’s syntactic sugar for two distinct steps: (1) creating a new function object, and (2) binding a new variable to it. If Lox had syntax for anonymous functions, we wouldn’t need function declaration statements. You could just do:
var add = fun (a, b) {
print a + b;
};
However, since named functions are the common case, I went ahead and gave Lox nice syntax for them.
Alas, in our rush to cram closures in, we have let a tiny bit of dynamic scoping leak into the interpreter. In the next chapter, we will explore deeper into lexical scope and close that hole.
习题
Our interpreter carefully checks that the number of arguments passed to a function matches the number of parameters it expects. Since this check is done at runtime on every call, it has a performance cost. Smalltalk implementations don’t have that problem. Why not?
Lox’s function declaration syntax performs two independent operations. It creates a function and also binds it to a name. This improves usability for the common case where you do want to associate a name with the function. But in functional-styled code, you often want to create a function to immediately pass it to some other function or return it. In that case, it doesn’t need a name.
Languages that encourage a functional style usually support anonymous functions or lambdas - an expression syntax that creates a function without binding it to a name. Add anonymous function syntax to Lox so that this works:
fun thrice(fn) {
for (var i = 1; i <= 3; i = i + 1) {
fn(i);
}
}
thrice(fun (a) {
print a;
});
// "1".
// "2".
// "3".
How do you handle the tricky case of an anonymous function expression occurring in an expression statement:
fun () {};
Is this program valid?
fun scope(a) {
var a = "local";
}
In other words, are a function’s parameters in the same scope as its local variables, or in an outer scope? What does Lox do? What about other languages you are familiar with? What do you think a language should do?
1
对 Smalltalk 不太了解 🤣,这里是参考答案:
Smalltalk has different call syntax for different arities. To define a method that takes multiple arguments, you use keyword selectors. Each argument has a piece of the method name preceding instead of using commas as a separator. For example, a method like:
list.insert("element", 2)
To insert “element” as index 2 would look like this in Smalltalk:
list insert:"element"at:2
Smalltalk doesn’t use a dot to separate method name from receiver. More interestingly, the “insert:” and “at:” parts both form a single method call whose full name is “insert:at:“. Since the selectors and the colons that separate them form part of the method’s name, there’s no way to call it with the wrong number of arguments. You can’t pass too many or two few arguments to “insert:at:” because there would be no way to write that call while still actually naming that method.
A variable usage refers to the preceding declaration with the same name in the innermost scope that encloses the expression where the variable is used.
I say “variable usage” instead of “variable expression” to cover both variable expressions and assignments. Likewise with “expression where the variable is used”.
”Preceding” means appearing before in the program text.
”Innermost” is there because of our good friend shadowing.
In JavaScript, variables declared using var are implicitly “hoisted” to the beginning of the block. Any use of that name in the block will refer to that variable, even if the use appears before the declaration. When you write this in JavaScript:
{
console.log(a);
var a = "value";
}
It behaves like:
{
var a; // Hoist.
console.log(a);
a = "value";
}
That means that in some cases you can read a variable before its initializer has run - an annoying source of bugs. The alternate let syntax for declaring variables was added later to address this problem.
Since this rule makes no mention of any runtime behavior, it implies that a variable expression always refers to the same declaration through the entire execution of the program.
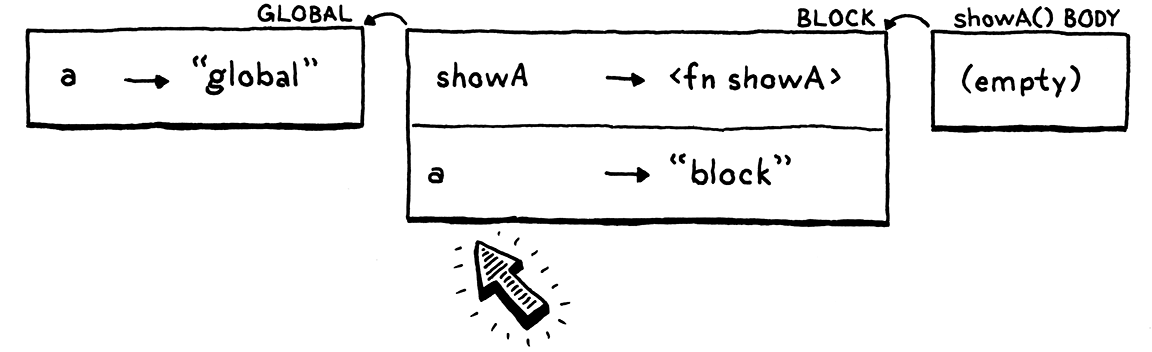
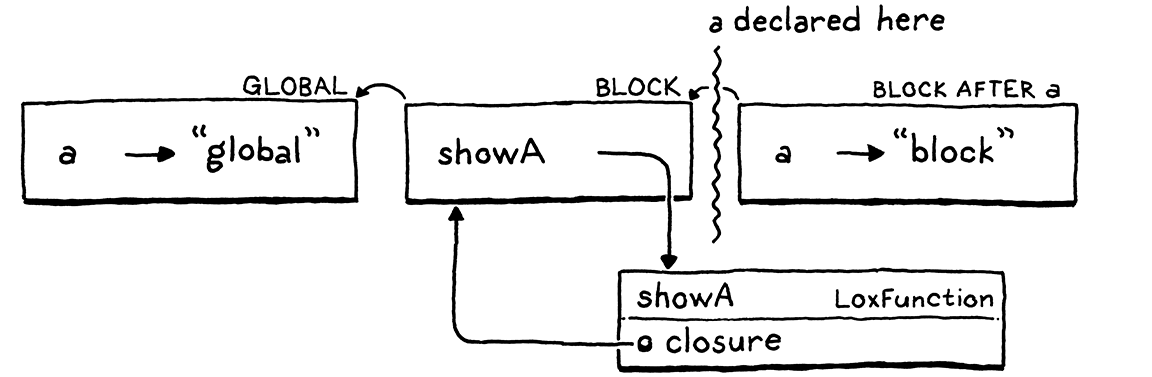
关键问题是词法作用域要求打印语句 print a; 中所引用的对象 a 在整个运行期内保持不变。我们再来反思之前出现的问题,罪魁祸首是赋值语句 var a = "block";,在执行完这条语句后,块作用域对应的环境发生了动态变化,然而我们的实现是以块作用域为最小环境单元为前提的,这就导致了上面的问题。
Some languages make this split explicit. In Scheme and ML, when you declare a local variable using let, you also delineate the subsequent code where the new variable is in scope. There is no implicit “rest of the block”.
我们有两种解决方法:
使用可持久化数据结构,每次修改环境都会隐式的生成新的环境对象,就像下图所示:
It’s the classic way to implement environments in Scheme interpreters.
在执行代码前对变量进行静态解析与绑定,这是语义分析的一个例子
为了最大程度复用已经实现的代码,我们选择第二种做法。这里的关键是:
If we could ensure a variable lookup always walked the same number of links in the environment chain, that would ensure that it found the same variable in the same scope every time.
It would work here too, but I want an excuse to show you another technique. We’ll write our resolver as a separate pass.
也就是说,在得到语法树后,我们并不是立刻执行代码,而是遍历一次语法树并对变量进行静态解析与绑定:
Additional passes between parsing and execution are common. If Lox had static types, we could slide a type checker in there. Optimizations are often implemented in separate passes like this too. Basically, any work that doesn’t rely on state that’s only available at runtime can be done in this way.
这类似于执行代码,区别在于:
There are no side effects. When the static analysis visits a print statement, it doesn’t actually print anything. Calls to native functions or other operations that reach out to the outside world are stubbed out and have no effect.
There is no control flow. Loops are visited only once. Both branches are visited in if statements. Logic operators are not short-circuited.
private final Map<Expr, Integer> locals = new HashMap<>();
You might think we’d need some sort of nested tree structure to avoid getting confused when there are multiple expressions that reference the same variable, but each expression node is its own Java object with its own unique identity.
The way the interpreter assumes the variable is in that map feels like flying blind. The interpreter code trusts that the resolver did its job and resolved the variable correctly. This implies a deep coupling between these two classes. In the resolver, each line of code that touches a scope must have its exact match in the interpreter for modifying an environment.
I felt that coupling firsthand because as I wrote the code for the book, I ran into a couple of subtle bugs where the resolver and interpreter code were slightly out of sync. Tracking those down was difficult. One tool to make that easier is to have the interpreter explicitly assert - using Java’s assert statements or some other validation tool - the contract it expects the resolver to have already upheld.
这样我们就能优化变量表达式和赋值表达式了(只有这两个对应的方法对环境进行了 get 或 assign)。首先是变量表达式:
@Override
public Object visitVariableExpr(Expr.Variable expr) {
Why is it safe to eagerly define the variable bound to a function’s name when other variables must wait until after they are initialized before they can be used?
How do other languages you know handle local variables that refer to the same name in their initializer, like:
var a = "outer";
{
var a = a;
}
Is it a runtime error? Compile error? Allowed? Do they treat global variables differently? Do you agree with their choices? Justify your answer.
Extend the resolver to report an error if a local variable is never used.
Our resolver calculates which environment the variable is found in, but it’s still looked up by name in that map. A more efficient environment representation would store local variables in an array and look them up by index.
Extend the resolver to associate a unique index for each local variable declared in a scope. When resolving a variable access, look up both the scope the variable is in and its index and store that. In the interpreter, use that to quickly access a variable by its index instead of using a map.
1
首先观察 visitFunctionStmt 方法:
@Override
public Void visitFunctionStmt(Stmt.Function stmt) {
Multimethods are the approach you’re least likely to be familiar with. I’d love to talk more about them - I designed a hobby language around them once and they are super rad- but there are only so many pages I can fit in. If you’d like to learn more, take a look at CLOS (the object system in Common Lisp), Dylan, Julia, or Raku.
That two-stage variable binding process allows references to the class inside its own methods.
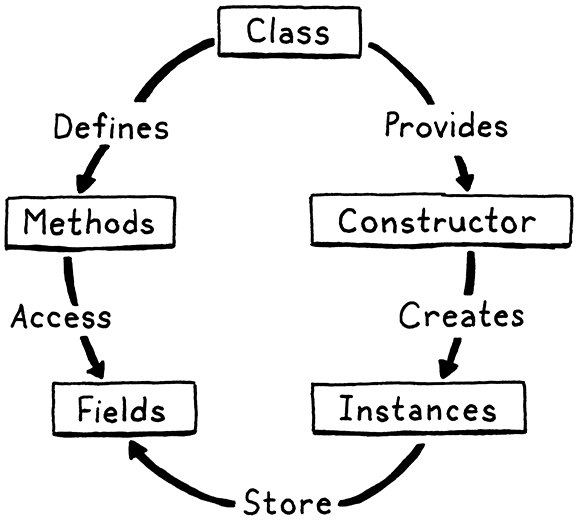
类实例
While some syntax and semantics are fairly standard across OOP languages, the way you create new instances isn’t. Ruby, following Smalltalk, creates instances by calling a method on the class object itself, a recursively graceful approach. Some, like C++ and Java, have a new keyword dedicated to birthing a new object. Python has you “call” the class itself like a function. (JavaScript, ever weird, sort of does both.)
In Smalltalk, even classes are created by calling methods on an existing object, usually the desired superclass. It’s sort of a turtles-all-the-way-down thing. It ultimately bottoms out on a few magical classes like Object and Metaclass that the runtime conjures into being ex nihilo.
It’s as if a class is a factory function that generates instances of itself.
为此,我们需要新建一个类 LoxInstance,其中含有一个 LoxClass 类型的字段。
@Override
public Object call(Interpreter interpreter, List<Object> arguments) {
LoxInstance instance = new LoxInstance(this);
return instance;
}
@Override
public int arity() {
return 0;
}
实例属性
属性(property):字段(field)和方法(method)
对属性的访问是通过句号运算符进行的,句号运算符和调用运算符具有相同的优先级。
Allowing code outside of the class to directly modify an object’s fields goes against the object-oriented credo that a class encapsulates state. Some languages take a more principled stance. In Smalltalk, fields are accessed using simple identifiers - essentially, variables that are only in scope inside a class’s methods. Ruby uses @ followed by a name to access a field in an object. That syntax is only meaningful inside a method and always accesses state on the current object.
Lox, for better or worse, isn’t quite so pious about its OOP faith.
throw new RuntimeError(expr.name, "Only instances have properties.");
}
为此,我们在 LoxInstance 类中添加一个字段,一个从属性(字段)名到引用对象的映射表,并对应添加 get 方法。
Doing a hash table lookup for every field access is fast enough for many language implementations, but not ideal. High performance VMs for languages like JavaScript use sophisticated optimizations like “hidden classes” to avoid that overhead.
Paradoxically, many of the optimizations invented to make dynamic languages fast rest on the observation that - even in those languages - most code is fairly static in terms of the types of objects it works with and their fields.
Unlike getters, setters don’t chain. However, the reference to call allows any high-precedence expression before the last dot, including any number of getters, as in:
使用 GenerateAst 生成:
"Set : Expr object, Token name, Expr value"
对应修改 Parser 类中的 assignment 方法:
private Expr assignment() {
Expr expr = ternary();
if (match(EQUAL)) {
Token equals = previous();
Expr value = assignment();
if (expr instanceof Expr.Variable) {
Token name = ((Expr.Variable) expr).name;
return new Expr.Assign(name, value);
} else if (expr instanceof Expr.Get) {
Expr.Get get = (Expr.Get) expr;
return new Expr.Set(get.object, get.name, value);
}
error(equals, "Invalid assignment target.");
}
return expr;
}
对于语义,类似访问属性的部分,不再赘述。
由于实例属性的动态性,我们没有必要在设置属性前检查属性是否存在。
类方法
这里的类方法并不是指我们可以通过类名直接调用方法,这只是为了暗示方法是存储在类中的。
我们在一个类实例上访问并调用方法,如图所示:
现在一个问题是,如果将访问和调用方法的过程分开,会发生什么,例如考虑下面的代码:
class Person {
sayName() {
print this.name;
}
}
var jane = Person();
jane.name = "Jane";
var method = jane.sayName;
method(); // ?
结果应该是 Jane,那下面的代码呢:
class Person {
sayName() {
print this.name;
}
}
var jane = Person();
jane.name = "Jane";
var bill = Person();
bill.name = "Bill";
bill.sayName = jane.sayName;
bill.sayName(); // ?
结果依然是 Jane。这带给我们一个启示(现在用不上 🤣):
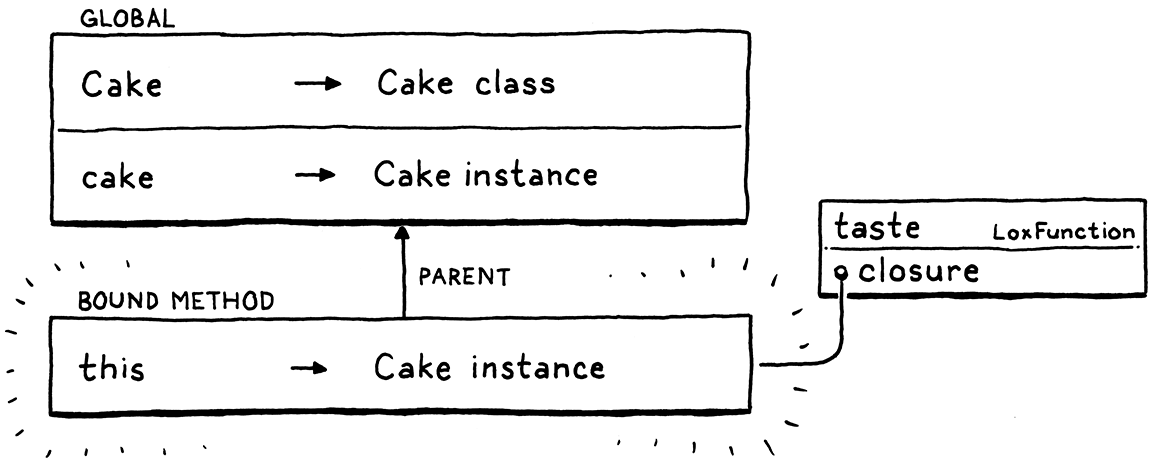
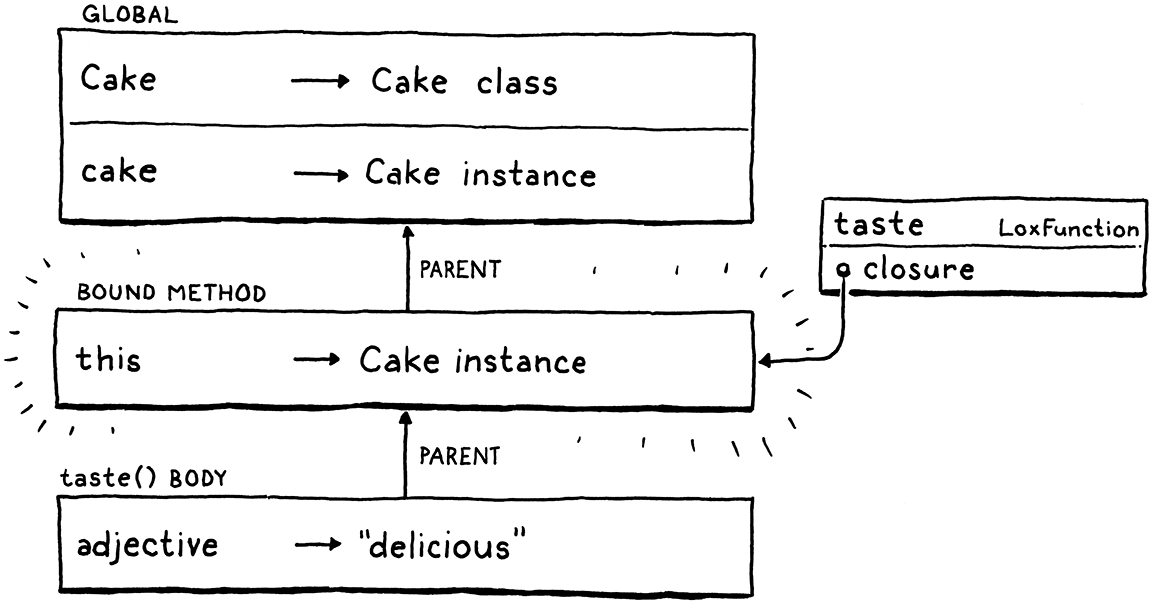
We will have methods “bind” this to the original instance when the method is first grabbed. Python calls these bound methods.
这里涉及了方法(函数)是一等对象及 this 表达式等内容,比较费解 🤣。
A motivating use for this is callbacks. Often, you want to pass a callback whose body simply invokes a method on some object. Being able to look up the method and pass it directly saves you the chore of manually declaring a function to wrap it. Compare this:
scopes.peek().put("this", new Variable(null, VariableState.READ));
for (Stmt.Function method : stmt.methods) {
FunctionType declaration = FunctionType.METHOD;
resolveFunction(method.function, declaration);
}
endScope();
return null;
}
这里的 scopes.peek().put("this", new Variable(null, VariableState.READ)); 也是为了识别未使用的局部变量,之所以不用 VariableState.DEFINED,是因为若类声明中的方法里没有出现 this 的话,Resolver 类的 endScope 方法就会报错。这里使用 null,是因为没有该token的信息。
The resolver has a new scope for this, so the interpreter needs to create a corresponding environment for it. Remember, we always have to keep the resolver’s scope chains and the interpreter’s linked environments in sync with each other.
另外,我们还要检测出对 this 表达式的非法使用,方法和检查函数体之外调用 return 语句完全类似,在 Resolver 添加对应的枚举类 ClassType 即可。
init
”Constructing” an object is actually a pair of operations:
The runtime allocates the memory required for a fresh instance. In most languages, this operation is at a fundamental level beneath what user code is able to access.
Then, a user-provided chunk of code is called which initializes the unformed object.
C++‘s “placement new” is a rare example where the bowels of allocation are laid bare for the programmer to prod.
The latter is what we tend to think of when we hear “constructor”, but the language itself has usually done some groundwork for us before we get to that point. In fact, our Lox interpreter already has that covered when it creates a new LoxInstance object.
We’ll do the remaining part - user-defined initialization - now.
我们需要修改 LoxClass 中的 call 方法和 arity 方法:
@Override
public Object call(Interpreter interpreter, List<Object> arguments) {
We have methods on instances, but there is no way to define “static” methods that can be called directly on the class object itself. Add support for them. Use a class keyword preceding the method to indicate a static method that hangs off the class object.
class Math {
class square(n) {
return n * n;
}
}
print Math.square(3); // Prints "9".
You can solve this however you like, but the “metaclasses” used by Smalltalk and Ruby are a particularly elegant approach. Hint: Make LoxClass extend LoxInstance and go from there.
Most modern languages support “getters” and “setters” - members on a class that look like field reads and writes but that actually execute user-defined code. Extend Lox to support getter methods. These are declared without a parameter list. The body of the getter is executed when a property with that name is accessed.
class Circle {
init(radius) {
this.radius = radius;
}
area {
return 3.141592653 * this.radius * this.radius;
}
}
var circle = Circle(4);
print circle.area; // Prints roughly "50.2655".
Python and JavaScript allow you to freely access an object’s fields from outside of its own methods. Ruby and Smalltalk encapsulate instance state. Only methods on the class can access the raw fields, and it is up to the class to decide which state is exposed. Most statically typed languages offer modifiers like private and public to control which parts of a class are externally accessible on a per-member basis.
What are the trade-offs between these approaches and why might a language prefer one or the other?
The decision to encapsulate at all or not is the classic trade-off between whether you want to make things easier for the class consumer or the class maintainer. By making everything public and freely externally visible and modifier, a downstream user of a class has more freedom to pop the hood open and muck around in the class’s internals.
However, that access tends to increasing coupling between the class and its users. That increased coupling makes the class itself more brittle, similar to the “fragile base class problem”. If users are directly accessing properties that the class author considered implementation details, they lose the freedom to tweak that implementation without breaking those users. The class can end up harder to change. That’s more painful for the maintainer, but also has a knock-on effect to the consumer — if the class evolves more slowly, they get fewer newer features for free from the upstream maintainer.
On the other hand, free external access to class state is a simpler, easier user experience when the class maintainer and consumer are the same person. If you’re banging out a small script, it’s handy to be able to just push stuff around without having to go through a lot of ceremony and boilerplate. At small scales, most language features that build fences in the program are more annoying than they are useful.
As the program scales up, though, those fences become increasingly important since no one person is able to hold the entire program in their head. Boundaries in the code let you make productive changes while only knowing a single region of the program.
Assuming you do want some sort of access control over properties, the next question is how fine-grained. Java has four different access control levels. That’s four concepts the user needs to understand. Every time you add a member to a class, you need to pick one of the four, and need to have the expertise and forethought to choose wisely. This adds to the cognitive load of the language and adds some mental friction when programming.
However, at large scales, each of those access control levels (except maybe package private) has proven to be useful. Having a few options gives class maintainers precise control over what extension points the class user has access to. While the class author has to do the mental work to pick a modifier, the class consumer gets to benefit from that. The modifier chosen for each member clearly communicates to the class user how the class is intended to be used. If you’re subclassing a class and looking at a sea of methods, trying to figure out which one to override, the fact that one is protected while the others are all private or public makes your choice much easier — it’s a clear sign that that method is for the subclass’s use.
You might be surprised that we store the superclass name as an Expr.Variable, not a Token. The grammar restricts the superclass clause to a single identifier, but at runtime, that identifier is evaluated as a variable access. Wrapping the name in an Expr.Variable early on in the parser gives us an object that the resolver can hang the resolution information off of.
| NUMBER | STRING | IDENTIFIER | "(" expression ")"
| "super" "." IDENTIFIER ;
Typically, a super expression is used for a method call, but, as with regular methods, the argument list is not part of the expression. Instead, a super call is a super access followed by a function call. Like other method calls, you can get a handle to a superclass method and invoke it separately.
So the super expression itself contains only the token for the super keyword and the name of the method being looked up.
使用 GenerateAst 生成:
"Super : Token keyword, Token method"
对应在 Parser 类的实现略去。
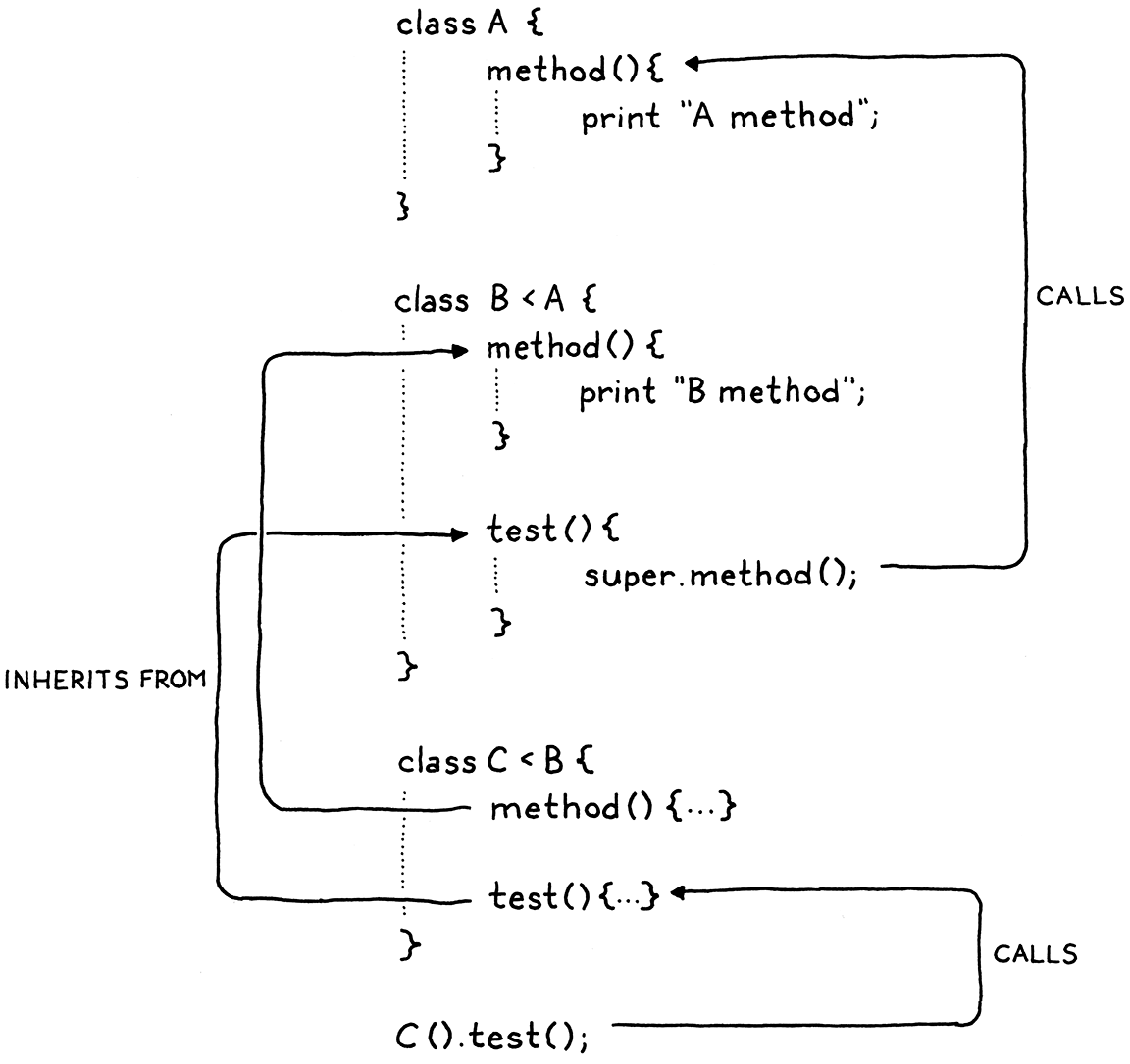
super 表达式的语义需要慎重考虑,思考下面的代码:
class A {
method() {
print "A method";
}
}
class B < A {
method() {
print "B method";
}
test() {
super.method();
}
}
class C < B {}
C().test();
正确的结果应该是 A method,分析见图:
The execution flow looks something like this:
We call test() on an instance of C.
That enters the test() method inherited from B. That calls super.method().
The superclass of B is A, so that chains to method() on A, and the program prints “A method”.
若 super 表达式从 this 的超类开始寻找,结果就变成了 B method。所以 super 表达式应该从包含 super 表达式的类的超类开始寻找。
为了实现这个语义,我们采用和 this 表达式类似的方法 - 闭包。
One important difference is that we bound this when the method was accessed. The same method can be called on different instances and each needs its own this. With super expressions, the superclass is a fixed property of the class declaration itself. Every time you evaluate some super expression, the superclass is always the same.
第四条语句是函数调用表达式语句。callee 为 C().test,这本身又是一个 Get 表达式语句,其 object 也就是 C() 也是一个函数调用语句。不过这些东西都在全局环境中,也无所谓。
再来看看 interpreter 干了些什么:
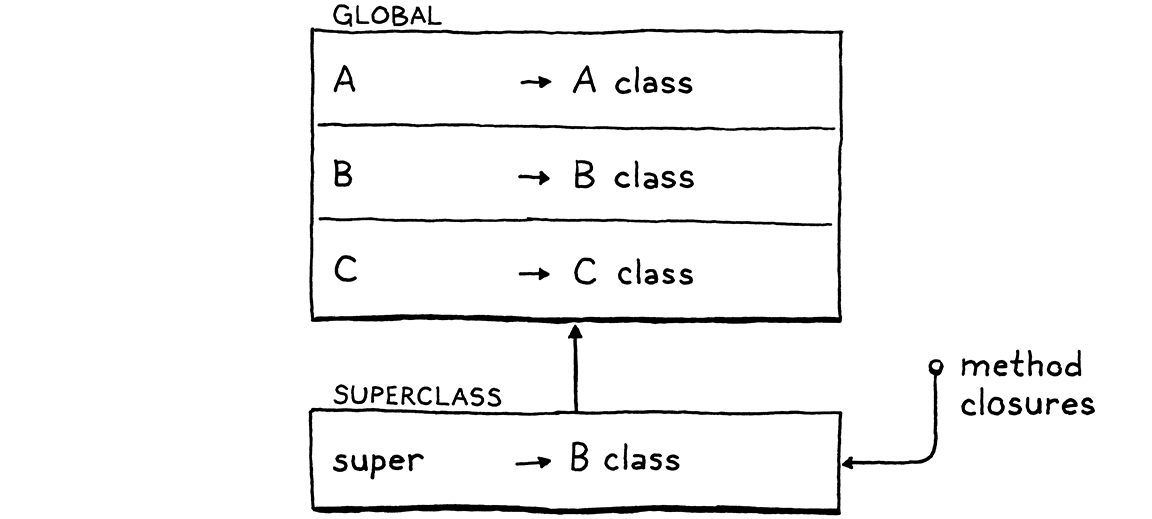
第一条语句是类声明语句,我们在全局环境中添加类名 A。
第二条语句是类声明语句,我们在全局环境中添加类名 B。同时,以全局环境为父环境创建一个新的环境,其 super 引用了类 A。
第三条语句是类声明语句,我们在全局环境中添加类名 C。同时,以全局环境为父环境创建一个新的环境,其 super 引用了类 B。
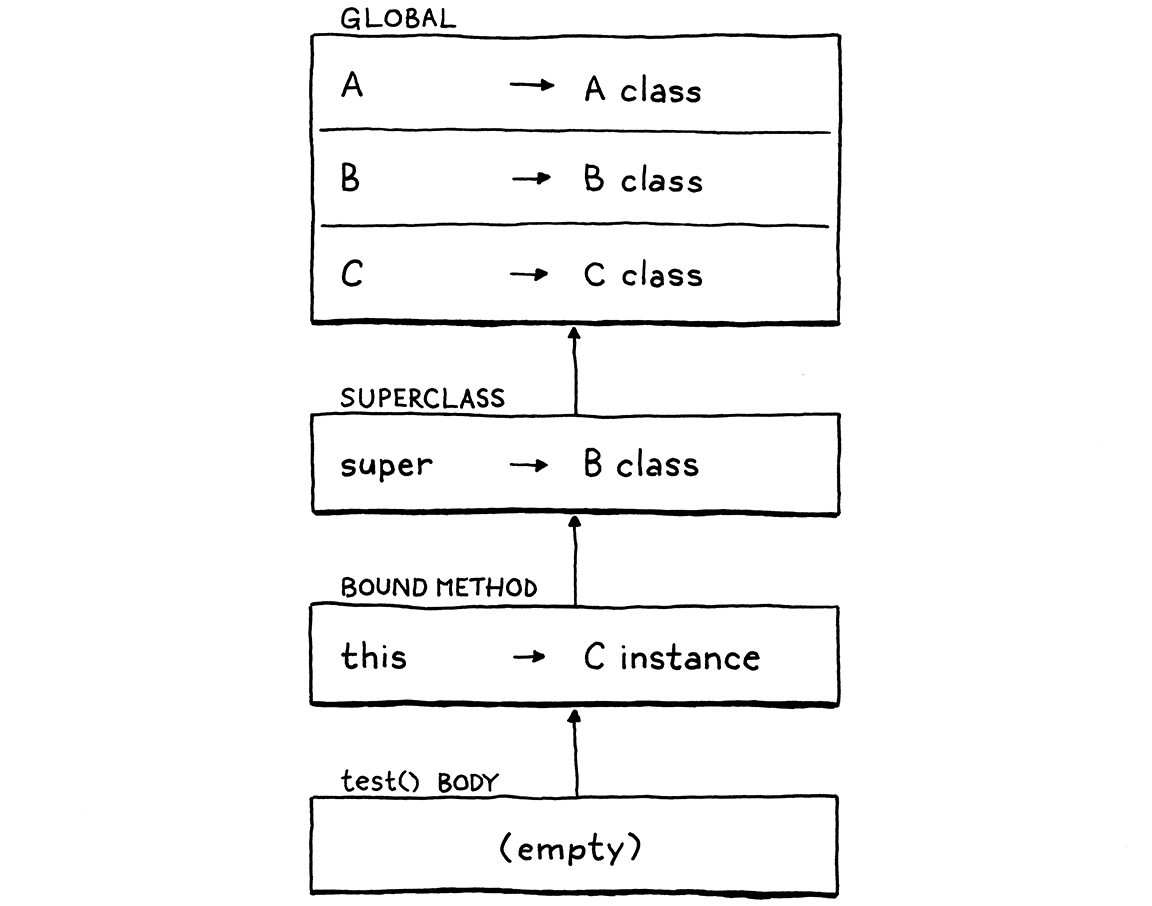
第四条语句是函数调用表达式语句。我们调用 visitCallExpr 方法,在 evaluate(expr.callee); 的过程中,先调用 visitGetExpr 方法,其中 evaluate(expr.object);,这又调用了 visitCallExpr 方法,通过 evaluate(expr.callee); 得到 callee 为全局环境中的类 C,最终得到了类 C 的一个实例。我们回到 visitGetExpr 方法中,在该实例上get方法 test,我们在其超类 B 中找到了 test 方法,此时的环境图如下(super 所引用的应该是 A class):
在 method.bind(this); 中,注意这里的 test 方法存储在类 B 中,而 this 却是类 C 的实例。最终我们回到了 visitCallExpr 方法,在 function.call(this, arguments); 中创建了一个新的环境,并执行函数体。此时环境图如下(super 所引用的应该是 A class):
习题
Lox supports only single inheritance- a class may have a single superclass and that’s the only way to reuse methods across classes. Other languages have explored a variety of ways to more freely reuse and share capabilities across classes: mixins, traits, multiple inheritance, virtual inheritance, extension methods, etc.
If you were to add some feature along these lines to Lox, which would you pick and why? If you’re feeling courageous (and you should be at this point), go ahead and add it.
In Lox, as in most other object-oriented languages, when looking up a method, we start at the bottom of the class hierarchy and work our way up - a subclass’s method is preferred over a superclass’s. In order to get to the superclass method from within an overriding method, you use super.
The language BETA takes the opposite approach. When you call a method, it starts at the top of the class hierarchy and works down. A superclass method wins over a subclass method. In order to get to the subclass method, the superclass method can call inner, which is sort of like the inverse of super. It chains to the next method down the hierarchy.
The superclass method controls when and where the subclass is allowed to refine its behavior. If the superclass method doesn’t call inner at all, then the subclass has no way of overriding or modifying the superclass’s behavior.
Take out Lox’s current overriding and super behavior and replace it with BETA’s semantics. In short:
When calling a method on a class, prefer the method highest on the class’s inheritance chain.
Inside the body of a method, a call to inner looks for a method with the same name in the nearest subclass along the inheritance chain between the class containing the inner and the class of this. If there is no matching method, the inner call does nothing.
For example:
class Doughnut {
cook() {
print "Fry until golden brown.";
inner();
print "Place in a nice box.";
}
}
class BostonCream < Doughnut {
cook() {
print "Pipe full of custard and coat with chocolate.";
}
}
BostonCream().cook();
This should print:
Fry until golden brown.
Pipe full of custard and coat with chocolate.
Place in a nice box.
In the chapter where I introduced Lox, I challenged you to come up with a couple of features you think the language is missing. Now that you know how to build an interpreter, implement one of those features.