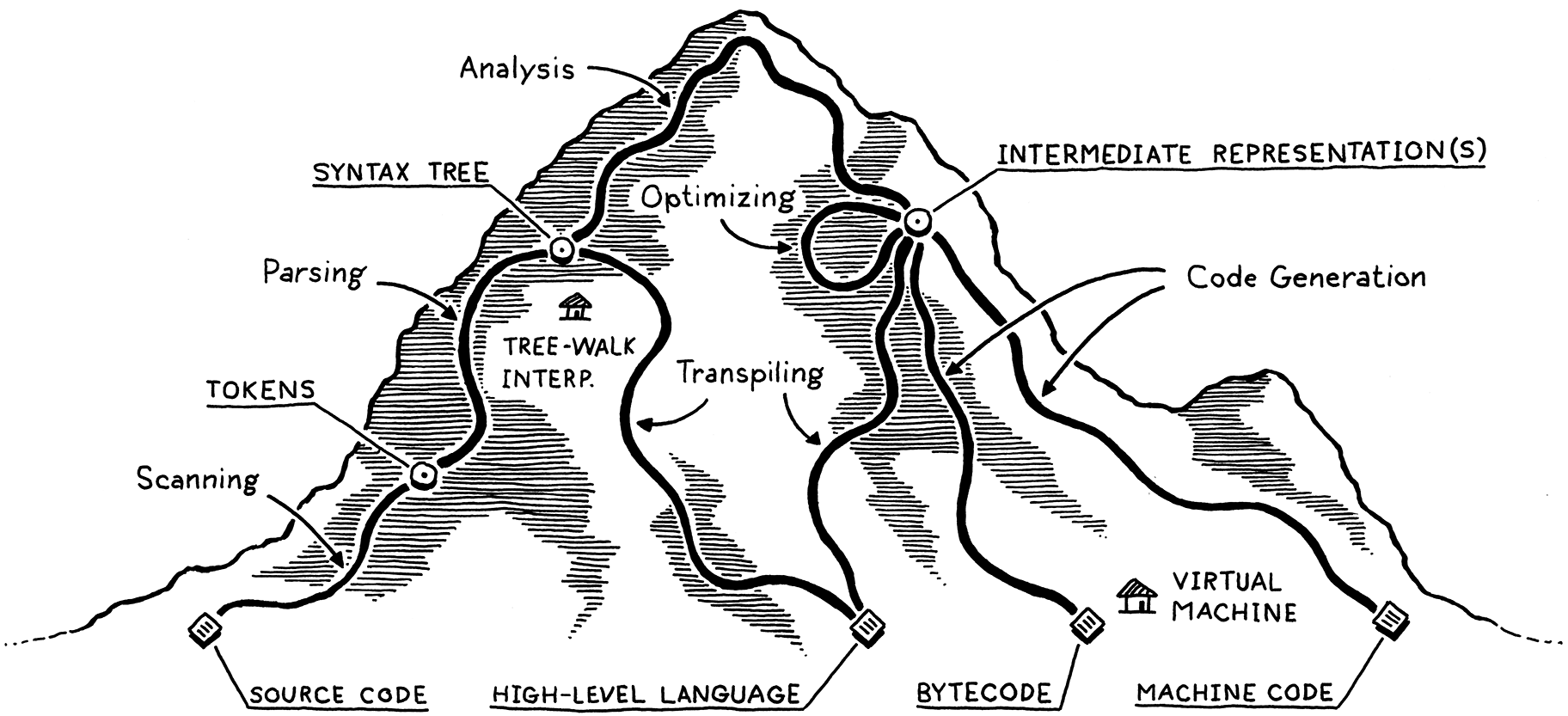
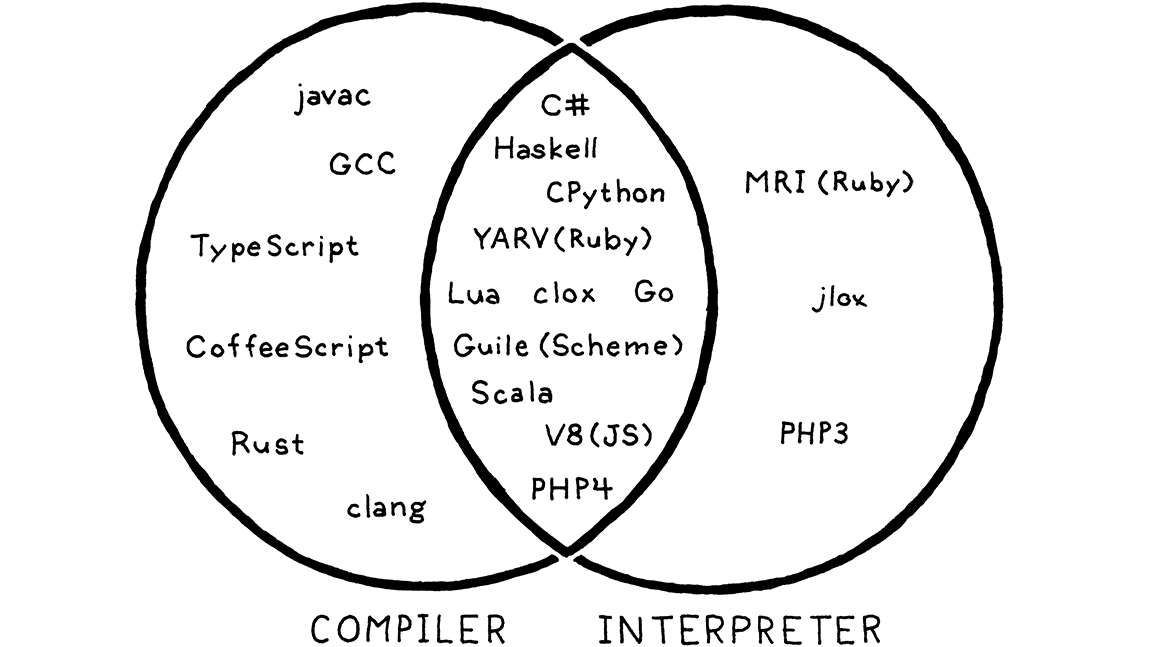
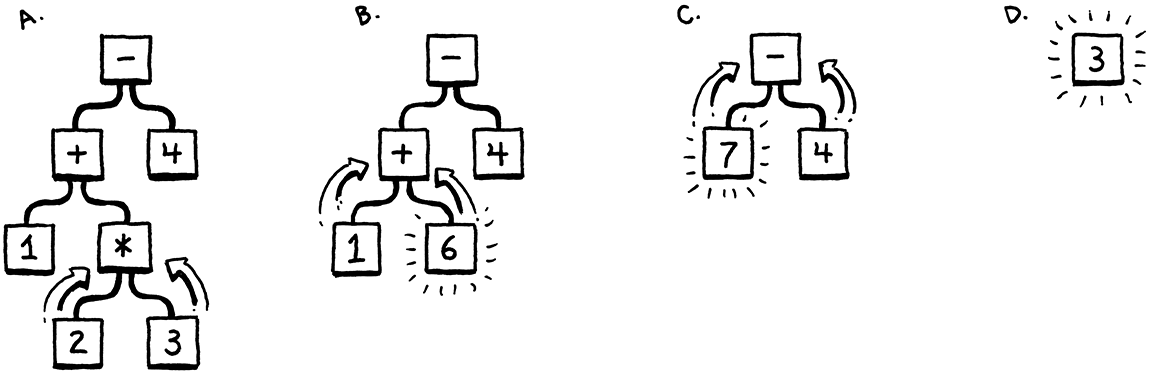
或者编写一个虚拟机,一个在运行时模拟支持虚拟体系结构的假想芯片的程序。在虚拟机中运行字节码比提前将其转换为本机代码要慢,因为每次执行指令时都必须在运行时对其进行模拟。作为回报,可以获得简单性和可移植性。比如说,用 C 语言实现虚拟机,就可以在任何有 C 编译器的平台上运行这种语言。这就是在本书中构建的第二个解释器的工作原理。
Lox 看起来最像 JavaScript,主要是因为大多数 C 语法语言都像 JavaScript。正如我们稍后将了解到的,Lox 的作用域与 Scheme 非常接近。我们将在第三部分中构建的 Lox 的 C 风格要归功于 Lua 干净、高效的实现。
Lox 是动态类型(类型检查在运行时,静态类型语言的实现需要更多的理论与实践)
Lox 拥有自动内存管理
There are two main techniques for managing memory: reference counting and tracing garbage collection (usually just called garbage collection or GC).
In practice, ref counting and tracing are more ends of a continuum than opposing sides. Most ref counting systems end up doing some tracing to handle cycles, and the write barriers of a generational collector look a bit like retain calls if you squint.
Peter J. Landin coined the term “closure”. Yes, he invented damn near half the terms in programming languages. Most of them came out of one incredible paper, The Next 700 Programming Languages.
An interactive prompt is also called a “REPL” (pronounced like “rebel” but with a “p”). The name comes from Lisp where implementing one is as simple as wrapping a loop around a few built-in functions:
(print (eval (read)))
Working outwards from the most nested call, you Read a line of input, Evaluate it, Print the result, then Loop and do it all over again.
Having said all that, for this interpreter, what we’ll build is pretty bare bones. I’d love to talk about interactive debuggers, static analyzers, and other fun stuff, but there’s only so much ink in the pen.
Strings created this way are called derivations because each is derived from the rules of the grammar.
Rules are called productions because they produce strings in the grammar.
Each production in a context-free grammar has a head - its name - and a body, which describes what it generates. In its pure form, the body is simply a list of symbols. Symbols come in two delectable flavors:
Restricting heads to a single symbol is a defining feature of context-free grammars. More powerful formalisms like unrestricted grammars allow a sequence of symbols in the head as well as in the body.
A terminal is a letter from the grammar’s alphabet. You can think of it like a literal value. In the syntactic grammar we’re defining, the terminals are individual lexemes — tokens coming from the scanner like if or 1234.
These are called “terminals” , in the sense of an “end point” because they don’t lead to any further “moves” in the game. You simply produce that one symbol.
A nonterminal is a named reference to another rule in the grammar. It means “play that rule and insert whatever it produces here”. In this way, the grammar composes.
Yes, we need to define a syntax to use for the rules that define our syntax. Should we specify that metasyntax too? What notation do we use for it? It’s languages all the way down!
这里的 NUMBER 表示任何数字文字,而 STRING 是任何字符串文字,不要和 nonterminal 混淆了。
Recursion in the grammar is a good sign that the language being defined is context-free instead of regular. In particular, recursion where the recursive nonterminal has productions on both sides implies that the language is not regular.
Tracking the number of required trailing parts is beyond the capabilities of a regular grammar. Regular grammars can express repetition, but they can’t keep count of how many repetitions there are, which is necessary to ensure that the string has the same number of ( and ) parts.
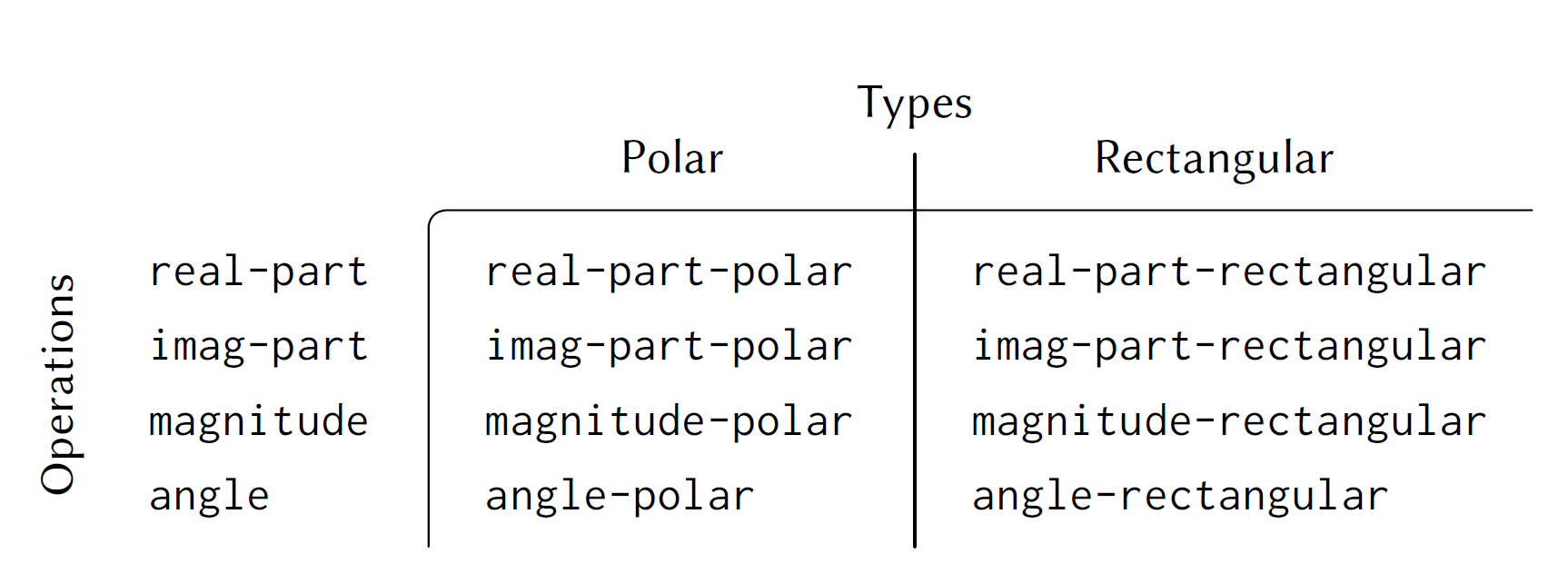
而对于函数式编程语言 ML 而言,类型和方法是分离的(Haskell 缓缓打出一个问号 🤨)。要为多种不同类型实现操作,需要定义一个函数,在该函数的主体中使用模式匹配,这使得扩展方法(一个新列)变得容易:
但是扩展类型很难,必须在所有函数的模式匹配中添加一个新的类型匹配。
Languages with multimethods, like Common Lisp’s CLOS, Dylan, and Julia do support adding both new types and operations easily. What they typically sacrifice is either static type checking, or separate compilation.
这里的讨论让我想起了 SICP 的 2.4 Multiple Representations for Abstract Data 这一章节:
Another common refinement is an additional “context” parameter that is passed to the visit methods and then sent back through as a parameter to accept(). That lets operations take an additional parameter. The visitors we’ll define in the book don’t need that, so I omitted it.
Produce a grammar that matches the same language but does not use any of that notational sugar.
expr → expr calls
expr → IDENTIFIER
expr → NUMBER
calls → calls call
calls → call
call → "(" ")"
call → "(" arguments ")"
call → "." IDENTIFIER
arguments → expr
arguments → arguments "," expr
Bonus: What kind of expression does this bit of grammar encode?
函数调用,有点怪 🤨
2
The Visitor pattern lets you emulate the functional style in an object-oriented language. Devise a complementary pattern for a functional language. It should let you bundle all of the operations on one type together and let you define new types easily.
If you wanted to do some clever Java 8, you could create a helper method for parsing a left-associative series of binary operators given a list of token types, and an operand method handle to simplify this redundant code.
The fact that the parser looks ahead at upcoming tokens to decide how to parse puts recursive descent into the category of predictive parsers.
对于 primary 层,代码如下:
private Expr primary() {
if (match(FALSE)) return new Expr.Literal(false);
if (match(TRUE)) return new Expr.Literal(true);
if (match(NIL)) return new Expr.Literal(null);
if (match(NUMBER, STRING)) {
return new Expr.Literal(previous().literal);
}
if (match(LEFT_PAREN)) {
Expr expr = expression();
consume(RIGHT_PAREN, "Expect ')' after expression.");
In C, a block is a statement form that allows you to pack a series of statements where a single one is expected. The comma operator is an analogous syntax for expressions. A comma-separated series of expressions can be given where a single expression is expected (except inside a function call’s argument list). At runtime, the comma operator evaluates the left operand and discards the result. Then it evaluates and returns the right operand.
Add support for comma expressions. Give them the same precedence and associativity as in C. Write the grammar, and then implement the necessary parsing code.
参考 C 运算符优先级 可知,在 C 中,逗号运算符具有最低的优先级,因而介于 expression 层和 equality 层之间,由于逗号运算符是二元运算符,且结合性为从左到右,只要简单的添加一层就可以了:
private Expr expression() {
return comma();
}
private Expr comma() {
Expr expr = equality();
while (match(COMMA)) {
Token operator = previous();
Expr right = equality();
expr = new Expr.Binary(expr, operator, right);
}
return expr;
}
若输入为:
1+1==2,3==4,5
则输出为:
(, (, (== (+ 1.0 1.0) 2.0) (== 3.0 4.0)) 5.0)
对于如何求值,见下一章。
2
Likewise, add support for the C-style conditional or “ternary” operator ?:. What precedence level is allowed between the ? and :? Is the whole operator left-associative or right-associative?
Add error productions to handle each binary operator appearing without a left-hand operand. In other words, detect a binary operator appearing at the beginning of an expression. Report that as an error, but also parse and discard a right-hand operand with the appropriate precedence.
Another way to handle common syntax errors is with error productions. You augment the grammar with a rule that successfully matches the erroneous syntax. The parser safely parses it but then reports it as an error instead of producing a syntax tree.
For example, some languages have a unary + operator, like +123, but Lox does not. Instead of getting confused when the parser stumbles onto a + at the beginning of an expression, we could extend the unary rule to allow it.
unary → ( "!" | "-" | "+" ) unary
| primary ;
This lets the parser consume + without going into panic mode or leaving the parser in a weird state.
Error productions work well because you, the parser author, know how the code is wrong and what the user was likely trying to do. That means you can give a more helpful message to get the user back on track, like, “Unary ’+’ expressions are not supported.” Mature parsers tend to accumulate error productions like barnacles since they help users fix common mistakes.
In Lox, values are created by literals, computed by expressions, and stored in variables.
The user sees these as Lox objects, but they are implemented in the underlying language our interpreter is written in.
Here, I’m using “value” and “object” pretty much interchangeably.
Later in the C interpreter we’ll make a slight distinction between them, but that’s mostly to have unique terms for two different corners of the implementation — in-place versus heap-allocated data. From the user’s perspective, the terms are synonymous.
private static final Interpreter interpreter = new Interpreter();
We could simply not detect or report a type error at all. This is what C does if you cast a pointer to some type that doesn’t match the data that is actually being pointed to. C gains flexibility and speed by allowing that, but is also famously dangerous. Once you misinterpret bits in memory, all bets are off.
Few modern languages accept unsafe operations like that. Instead, most are memory safe and ensure — through a combination of static and runtime checks — that a program can never incorrectly interpret the value stored in a piece of memory.
注:可以对比对象数组和对象容器的行为,详见 Core Java 泛型类型的继承规则和 Object List 部分。
习题
注:这里实现了对上一章中三目运算符和逗号运算符的求值
1
Allowing comparisons on types other than numbers could be useful. The operators might have a reasonable interpretation for strings. Even comparisons among mixed types, like 3 < "pancake" could be handy to enable things like ordered collections of heterogeneous types. Or it could simply lead to bugs and confusion.
Would you extend Lox to support comparing other types? If so, which pairs of types do you allow and how do you define their ordering? Justify your choices and compare them to other languages.
Many languages define + such that if either operand is a string, the other is converted to a string and the results are then concatenated. For example, "scone" + 4 would yield scone4. Extend the code in visitBinaryExpr() to support that.
在 PLUS 分支中加两个 if 语句就可以了:
case PLUS:
if (left instanceof Double && right instanceof Double)
return (double) left + (double) right;
if (left instanceof String && right instanceof String)
return (String) left + (String) right;
if (left instanceof String && right instanceof Double)
return (String) left + String.valueOf(stringify(right));
if (right instanceof String && left instanceof Double)
throw new RuntimeError(expr.operator, "Operands must be two numbers or two strings.");
注意这里使用了 stringify 方法,避免 "scone" + 4 变成 scone4.0
3
What happens right now if you divide a number by zero? What do you think should happen? Justify your choice. How do other languages you know handle division by zero, and why do they make the choices they do?
Change the implementation in visitBinaryExpr() to detect and report a runtime error for this case.