TOC
编译原理 实验
https://cs.nju.edu.cn/changxu/2_compiler/index.html
https://compiler.pascal-lab.net/contest
https://github.com/VGalaxies/cmm-compiler
词法分析
使用 flex
flex 源代码文件包括三个部分
{definitions}%%{rules}%%{user subroutines}在 {definitions} 部分,可以通过 %{ ... %} 的方式对变量、函数或者头文件进行声明,其内容会被拷贝到 lex.yy.c 的最前面
目前暂未使用 {user subroutines} 部分
使用命令 flex lexical.l 得到 lex.yy.c
再与 main 函数编译出可执行文件 scanner
gcc main.c lex.yy.c -lfl -o scanner注意在 main 函数需要 extern 一些变量
main 中使用的 yylex 函数即
lex.yy.c中的YY_DECL
稍微修改了一下 Makefile 以简化构建
下面分析一下 {definitions} 和 {rules} 中的正则表达式
对之前规则的引用需要使用 {...}
需要注意在 {rules} 中规则的顺序,如关键字在 ID 之前
flex 将依次尝试每一个规则,尽可能匹配最长的输入串
如果有些内容不匹配任何规则,flex 默认只将其拷贝到 stdout
所以需要在最后添加 .,以报告非法的 token
关于选做内容
- 考虑八进制数和十六进制数
- 不考虑指数形式的浮点数
- 不考虑注释
一些预先定义的变量
- yytext → 匹配的文本
- yylineno → 行号,需要使用
%option yylineno开启 - yyin → 输入流,默认为 stdin
然后是对 token 的存储
typedef struct { int yyname; union { int yylval; unsigned yyint; float yyfloat; char yystring[64]; };} Token;
Token tokens[1024];size_t curr_index = 0;可以假设每个标识符长度不超过 32 个字符
输入的整型数和浮点数是否可以由 unsigned 和 float 表示
yyname 和 yylval 源自枚举类型
注意枚举里的 INT 可能代表 "int" 的 yylval,也可能代表 123 的 yyname
设计似乎不太好
使用 install 函数记录读取的词素 (Lexeme)
对 main 函数的接口还需考虑
语法分析
构建
去掉 Makefile 中的 -ly
使用 make parser
结构变化
需要使用 -d 参数,生成头文件 syntax.tab.h,供 lexical.l 包含
这样的话,lexical.l 可以返回在 syntax.y 定义的词法单元
再让 syntax.y 包含 lex.yy.c
这样的话,bison 就可以使用 flex 提供的 yylex
main.c 中只需要调用 yyparse 即可
另外引入了 common.h 供 main.c 和 lexical.l 包含,syntax.y 不必包含 common.h
命名约定
为了区分枚举和 flex 与 bison 定义的一些单元,有如下约定
common.h中定义了 terminal 和 non-terminal,以下划线开头- flex 中定义的正则表达式的别名为小写
- bison 中定义的 terminal 和 non-terminal 与
common.h一致,只不过没有下划线
bison 参数
-d
生成头文件 syntax.tab.h,供 lexical.l 包含
-v
生成 syntax.output
https://www.gnu.org/software/bison/manual/html_node/Understanding.html
-t
打开诊断模式
需要在 yyparse 前添加 yydebug = 1
-g
生成 syntax.dot
可以使用 graphviz 绘制语法图
-Wcounterexamples
当出现 Shift/Reduce Conflicts 时生成相应的例子
语法产生式
类似 flex 源代码,bison 源代码的结构也包含三个部分
{definitions}%%{rules}%%{user subroutines}在 {definitions} 部分定义词法单元,即终结符,以 %token 开头
在 {rules} 部分书写语法产生式,例如
Program : ExtDefList;ExtDefList : ExtDef ExtDefList |;其中空的部分代表 ε
优先级和结合性
若不处理,文法可能就会有二义性
bison 会警告 Shift/Reduce Conflicts
并使用隐式的解决方案:
- 一旦出现归约/归约冲突,bison 总会选择靠前的产生式
- 一旦出现移入/归约冲突,bison 总会选择移入
https://www.gnu.org/software/bison/manual/html_node/Shift_002fReduce.html
于是需要指明词法单元的优先级和结合性,例如
%right <type_ast> ASSIGNOP%left <type_ast> OR%left <type_ast> AND%left <type_ast> RELOP%left <type_ast> PLUS MINUS%left <type_ast> STAR DIV%right <type_ast> NOT UNARY_MINUS%left <type_ast> DOT LP RP LB RB
%nonassoc <type_ast> LOWER_THAN_ELSE%nonassoc <type_ast> ELSE%left 或 %right 指明结合性,越下面的词法单元优先级越高
在产生式中使用 %prec LOWER_THAN_ELSE 指明该产生式的优先级等同于一个终结符
生成语法树
在书写了包含所有语法产生式但不包含任何语义动作的 bison 源代码,并处理了优先级和结合性后
下面是生成语法树,为此,需要统一终结符和非终结符的属性
对于终结符,加上 <T>
对于非终结符,使用 %type <T> ...
%type <type_ast> Program ExtDefList ExtDef ExtDecList Specifier StructSpecifier OptTag Tag VarDec FunDec VarList ParamDec CompSt StmtList Stmt DefList Def DecList Dec Exp Args其中 T 是一个类型
%union { struct Ast *type_ast;}在 syntax.tab.h 中会相应生成
union YYSTYPE{#line 19 "./syntax.y"
struct Ast *type_ast;
#line 99 "./syntax.tab.h"
};下面考虑语法树的结构,目前设计如下
struct Ast { int lineno; int symbol_index; int type; size_t children_count; struct Ast *children[MAX_CHILDREN];};- lineno → 行号
- symbol_index → 在符号表中的下标,若无则为
-1 - type → 对应的终结符或非终结符的枚举值
- children_count 和 children 形成多叉树结构,由于最大分支数预先可知,使用 MAX_CHILDREN 宏控制
符号表为一个联合体
typedef union { int _attr; // for TYPE or RELOP unsigned _int; // for INT float _float; // for FLOAT char _string[64]; // for ID} Symbol;注释写的很清楚了
在 install 函数中会填充符号表
在 lexical.l 的 install 函数中,需要对终结符的属性进行赋值
注意到 syntax.tab.h 中提供了
extern YYSTYPE yylval;于是可以这样处理
static void install(int type, int attr) { DBG_PRINTF();
yylval.type_ast = (struct Ast *)log_malloc(sizeof(struct Ast)); yylval.type_ast->type = type; yylval.type_ast->children_count = 0; yylval.type_ast->lineno = yylineno; ...而在 syntax.y 中产生式的语义部分使用如下函数
extern void make_root(struct Ast **root);extern void make_node(struct Ast **node, int type);extern void make_children(struct Ast **root, int count, ...);以上述产生式为例,语义部分应为
Program : ExtDefList { make_root(&$$); make_children(&$$, 1, $1); };ExtDefList : ExtDef ExtDefList { make_node(&$$, _ExtDefList); make_children(&$$, 2, $1, $2); } | { make_node(&$$, _EMPTY); }注意变长参数的使用
_EMPTY 枚举值在打印语法树时会有用
打印语法树的部分略去
错误处理与恢复
在 lexical.l 和 syntax.y 中分别引入 has_lexical_error 和 has_syntax_error
词法分析的错误处理不变
下面考虑语法分析的错误处理
https://www.gnu.org/software/bison/manual/bison.html#Error-Recovery
需要在语法的产生式中添加 error 符号
目前仅考虑在 ExtDef 和 Def 处进行处理
即全局定义处和局部定义处
另外还有一个 yyerror 函数,需要区分
上完课之后,了解到错误处理是不可能尽善尽美的
在 action 部分,即syntax_error 中进行错误处理,会出现重复报错的情形
为此需要引入 last_error_lineno,增加了复杂性
在 yyerror 中进行错误处理,不会出现重复报错,但会出现延时报错的情形
例如,对于如下的程序
int b
int main() { int a;}当 bison 处理到第三行时,才会发现少了一个 SEMI,然后就在第三行报错了,实际上是第一行有问题
为此,在 make_children 中记录最新生成的父节点的行号,即 prev_lineno
yyerror 直接打印这个行号似乎还算准确
一些无法处理的情形
int b
int main() { int a;}}对于第 5 行多余的 SEMI,prev_lineno 记录的是最新生成的 ExtDef 即函数定义的行号,为 3
关键在于,似乎难以判断在出错之前一个完整的结构是否已经生成
后来发现 gcc 对于上述情形的处理如下
/home/vgalaxy/Templates/cmake-template/main.cpp:3:1: error: expected initializer before ‘int’ 3 | int main() { | ^~~/home/vgalaxy/Templates/cmake-template/main.cpp:5:2: error: expected declaration before ‘}’ token 5 | }}也就是打印了 yylineno
然而直接打印 yylineno,行号还可能溢出,如
int a;int b会打印第 4 行出错
所以就很矛盾……
调试脚本
$ gdb -x gdb-internal.shgdb-internal.sh 内容如下
file ./parserb clear_treer ../Test/temp.c内存泄露
使用 valgrind 诊断
$ valgrind --leak-check=full --show-leak-kinds=all --error-exitcode=1 ./parser ../Test/temp.c三个方面
- 语法树结构
使用 clear_tree 函数
依赖于记录了每次动态内存分配的节点表
void *node_table[MAX_NODE];size_t node_table_index = 0;还有 log_malloc 函数
void *log_malloc(size_t size) { void *res = malloc(size); node_table[node_table_index] = res; ++node_table_index; return res;}由于出现错误后语法树的结构可能无法正确保持,所以引入了节点表
在出现错误后,有两个选择,一是继续分配内存,二是停止分配
但是两个选择目前似乎都没有问题
- lex 和 bison 的内部结构
使用 yylex_destroy 函数
https://stackoverflow.com/questions/40227135/why-yacc-have-memory-leak-at-exit
- 打开的文件
使用 fclose 函数
不使用 yyin
提交
zip -r 201250012.zip Code/ README report.pdfunzip -l 201250012.zip一键回归测试
http://www.gnu.org/software/make/manual/make.html
发现 Makefile 里面写 shell 脚本不太方便
额外写了一个 shell 脚本
TEST=$(find ../Test -name "*.c")TESTARR=(${TEST})
make cleanmake parser
for i in "${!TESTARR[@]}"do echo -e "\e[1;35m./parser ${TESTARR[i]}\e[0m" bat ${TESTARR[i]} ./parser ${TESTARR[i]} echo -e "\n"donehttps://stackoverflow.com/questions/10586153/how-to-split-a-string-into-an-array-in-bash
官方测试用例
处理在第 0 行报错
初始化 prev_lineno 为 1
语义分析
符号表
更改实验一中的符号表为属性表
设计符号表如下
typedef struct SymbolItem *Symbol;typedef struct SymbolInfoItem *SymbolInfo;
struct SymbolInfoItem { enum { TypeDef, VariableInfo, FunctionInfo } kind; char name[64]; union { Type type; struct { SymbolInfo arguments[MAX_ARGUMENT]; size_t argument_count; Type return_type; } function; } info;};
struct SymbolItem { SymbolInfo symbol_info; Symbol tail;};符号有三种类型
- 变量
- 结构体定义
- 函数
对于变量和结构体而言,只需要存储 Type 即可
对于函数而言,需要存储参数和返回值的 Type,实际上参数存储的是符号类型
内存泄露
$ valgrind --leak-check=full --show-leak-kinds=all --error-exitcode=1 ./parser ../Test/lab2/tmp.c使用跟踪整个编译程序中的动态内存分配
void *log_malloc(size_t size) { if (malloc_table_size == 0) { malloc_table = (void **)malloc(INIT_MALLOC_SIZE * sizeof(void *)); malloc_table_size = INIT_MALLOC_SIZE; }
if (malloc_table_index == malloc_table_size) { malloc_table = (void **)realloc(malloc_table, malloc_table_size * 2 * sizeof(void *)); malloc_table_size *= 2; }
void *res = malloc(size); malloc_table[malloc_table_index] = res; ++malloc_table_index; return res;}并且 malloc_table 也可以动态调整大小
另外在声明的过程中常常会使用同一个 Type 或 Symbol
为此使用 memcpy 的方式完整复制整个结构体,防止多个指针指向同一个结构体
较大的内存开销
模块化
在 flex 和 bison 的定义部分完成 static 变量的定义和外部的接口函数
在 common.h 中 extern 接口函数,就可以在全局访问这些数据结构了
具体来说
- flex → 属性表
get_attribute
- bison → 语法树
print_ast_tree_interface
get_ast_root
- semantic → 符号表
print_symbol_table_interface
后来仿照 OS Lab 里面的 MODULE 和 MODULE_DEF,设计模块如下
typedef union Attribute attribute_t;typedef struct Ast ast_t;MODULE(parser) { attribute_t (*get_attribute)(size_t); void (*print_ast_tree)(); ast_t *(*get_ast_root)(); void (*restart)(FILE *); int (*parse)(); int (*lex_destroy)();};
MODULE(analyzer) { void (*semantic_analysis)(ast_t *); void (*print_symbol_table)();};
MODULE(mm) { void *(*log_malloc)(size_t); void (*clear_malloc)();};调试信息
将调试控制宏移动到 common.h 中
#define LEXICAL_DEBUG#define SYNTAX_DEBUG#define SEMANTIC_DEBUG注意打开 SYNTAX_DEBUG 后需要修改 Makefile 中 bison 的参数
或者注释掉使用
yydebug的部分
lexical 使用 log
semantic 使用 action 和 info
换行符可能对 ANSI Escape Code 有所影响
范式
遍历语法树的范式如下
void foo(struct Ast *node) { action("hit %s\n", unit_names[node->type]); assert(node->type == _UNIT);
if (check_node(node, count, ...) { ... return; }
assert(0); return;}使用 check_node 检测结点结构
防御式编程
一些细节
Specifier的设计
主要体现在解析 specifier 和 struct_specifier 中
一些约定
int -> VariableInfostruct A -> VariableInfostruct {...} -> VariableInfostruct A {...} -> TypeDef这样就可以在使用 specifier 的类型时,根据不同情形进行处理
典型的例子是 external_definition
- 小心
EMPTY
注意文法定义中一些产生 ε 的产生式
这样上层文法就会出现 EMPTY
例如 OptTag/StmtList/DefList
另外注意到 EMPTY 的行号为 INT_MAX
- 迭代和递归
遍历语法树时通常调用函数处理
在处理递归产生式时可能使用迭代处理
如 variable_declaration 处理数组类型
或 arguments 检查函数形参和实参是否匹配
- 忽略的语义错误
使用 action 汇报
- 填充类型信息
主要体现在函数类型和结构体类型
应该有两条不会相交的遍历路径
结构体类型
struct_specifier -> definition_list -> definition -> declaration_list -> declaration -> variable_declaration函数类型
construct_insert_function_compst -> variable_list -> parameter_declaration -> variable_declaration注意到两个相似的函数 definition 和 parameter_declaration
最终集中到 variable_declaration 中处理
- 级联效应
expression 会返回类型信息
当出现语义错误时,会返回 NULL
而单个 NULL 在 check_type 中会返回 mismatch
所以可能出现级联效应
一个例子是 lab2/test1.c
- 类型等价
设计如下
static int check_structure_type(FieldList lhs, FieldList rhs) { if (lhs == NULL && rhs == NULL) { return 1; }
if (lhs == NULL || rhs == NULL) { return 0; }
// TODO: structural equivalence return check_type(lhs->type, rhs->type) && check_structure_type(lhs->tail, rhs->tail);}
static int check_type(Type lhs, Type rhs) { if (lhs == NULL && rhs == NULL) { return 1; }
if (lhs == NULL || rhs == NULL) { return 0; }
if (lhs->kind != rhs->kind) { return 0; }
if (lhs->kind == BASIC) { return lhs->u.basic == rhs->u.basic; }
if (lhs->kind == ARRAY) { /* return lhs->u.array.size == rhs->u.array.size && * check_type(lhs->u.array.elem, rhs->u.array.elem); */ // no need to check size return check_type(lhs->u.array.elem, rhs->u.array.elem); }
if (lhs->kind == STRUCTURE) { return check_structure_type(lhs->u.structure, rhs->u.structure); }
return 0;}这里认为 structural equivalence 要求按顺序字段的类型是匹配的
https://stackoverflow.com/questions/4486401/structural-equivalence-vs-name-equivalence
中间代码生成
irsim
https://www.riverbankcomputing.com/
https://stackoverflow.com/questions/55424762/importerror-no-module-named-sip-python2-7-pyqt4
- python2
https://github.com/google/pytype/blob/main/pytype/pyc/magic.py
- sip
$ wget https://www.riverbankcomputing.com/static/Downloads/sip/4.19.25/sip-4.19.25.tar.gz$ python2 configure.py --sip-module PyQt4.sip$ make -j8$ sudo make install- PyQt4
$ wget https://www.riverbankcomputing.com/static/Downloads/PyQt4/4.12.3/PyQt4_gpl_x11-4.12.3.tar.gz$ python2 configure.py$ make -j8$ sudo make install修改
QtCore/sipQtCoreQAbstractEventDispatcher.cpp -> remove override
pyrcc/Makefile -> /usr/lib/libQt5Core.sopylup/Makefile -> /usr/lib/libQt5Core.so- pip with python2
$ curl -o get-pip.py https://bootstrap.pypa.io/pip/2.7/get-pip.py$ sudo python2 get-pip.py- package
https://packages.debian.org/search?keywords=python-qt4
代号 buster
对应 ubuntu-18.04
https://en.wikipedia.org/wiki/Ubuntu#Releases
https://www.jianshu.com/p/352917274542
环境配置
$ sudo apt-get install build-essential man gdb git vim$ sudo apt-get install python-qt4换源
https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/
$ sudo vi /etc/apt/sources.list$ sudo apt-get update备份
#deb cdrom:[Ubuntu 18.04.6 LTS _Bionic Beaver_ - Release amd64 (20210915)]/ bionic main restricted
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to# newer versions of the distribution.deb http://cn.archive.ubuntu.com/ubuntu/ bionic main restricted# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic main restricted
## Major bug fix updates produced after the final release of the## distribution.deb http://cn.archive.ubuntu.com/ubuntu/ bionic-updates main restricted# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu## team. Also, please note that software in universe WILL NOT receive any## review or updates from the Ubuntu security team.deb http://cn.archive.ubuntu.com/ubuntu/ bionic universe# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic universedeb http://cn.archive.ubuntu.com/ubuntu/ bionic-updates universe# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu## team, and may not be under a free licence. Please satisfy yourself as to## your rights to use the software. Also, please note that software in## multiverse WILL NOT receive any review or updates from the Ubuntu## security team.deb http://cn.archive.ubuntu.com/ubuntu/ bionic multiverse# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic multiversedeb http://cn.archive.ubuntu.com/ubuntu/ bionic-updates multiverse# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-updates multiverse
## N.B. software from this repository may not have been tested as## extensively as that contained in the main release, although it includes## newer versions of some applications which may provide useful features.## Also, please note that software in backports WILL NOT receive any review## or updates from the Ubuntu security team.deb http://cn.archive.ubuntu.com/ubuntu/ bionic-backports main restricted universe multiverse# deb-src http://cn.archive.ubuntu.com/ubuntu/ bionic-backports main restricted universe multiverse
## Uncomment the following two lines to add software from Canonical's## 'partner' repository.## This software is not part of Ubuntu, but is offered by Canonical and the## respective vendors as a service to Ubuntu users.# deb http://archive.canonical.com/ubuntu bionic partner# deb-src http://archive.canonical.com/ubuntu bionic partner
deb http://security.ubuntu.com/ubuntu bionic-security main restricted# deb-src http://security.ubuntu.com/ubuntu bionic-security main restricteddeb http://security.ubuntu.com/ubuntu bionic-security universe# deb-src http://security.ubuntu.com/ubuntu bionic-security universedeb http://security.ubuntu.com/ubuntu bionic-security multiverse# deb-src http://security.ubuntu.com/ubuntu bionic-security multiverse体验 fish shell
https://xiao_beita.gitee.io/009_fish_omf/
版权信息
IR Simulator v 1.0.2Copyright © 2012 Grieve. All rights reserved.This application can be used to simulate the IR designed for the Compiler course here at NJU.Python 2.7.17 - Qt 4.8.7 - PyQt 4.12.1 on Linux运行古早的程序真的折磨……
IR 模块
MODULE(ir) { void (*ir_translate)(struct Ast *); void (*ir_generate)(FILE *);};和语义分析类似,仍采取遍历语法树的方案,只不过侧重点不同
语法制导的翻译
在已有符号表和没有全局变量的前提下,只需考虑
ExtDef -> Specifier FunDec CompSt注意到
CompSt -> LC DefList StmtList RC对于 DefList,只需考虑有赋值的情形即可
其余没有赋值的情形,在使用时才会进行初始化
lazy load
类型信息增补
为了支持对数组和结构体的翻译
需要添加一些类型信息
struct TypeItem { enum { BASIC, ARRAY, STRUCTURE } kind; union { // 基本类型 int basic; // 数组类型信息包括元素类型与数组大小构成 struct { Type elem; size_t size; } array; // 结构体类型信息是一个链表 FieldList structure; } u; size_t width;};
struct FieldListItem { char name[LENGTH]; // 域的名字 Type type; // 域的类型 FieldList tail; // 下一个域 size_t offset;};即每个类型的宽度,以及结构体中每个字段的偏移量
然后对应修改 variable_declaration 等地方即可
之前结构体字段的插入是反向的,修正为正向插入,仍需注意指针的读写性质
内存泄露
多了一个参数用于存放中间代码
$ valgrind --leak-check=full --show-leak-kinds=all --error-exitcode=1 ./parser ../Test/lab3/test4.c /home/vgalaxy/Desktop/shared/demo.ir中间代码表示
数据结构设计如下
struct InterCode { enum { // assign IR_ASSIGN, IR_ASSIGN_CALL, // single IR_LABEL, IR_FUNCTION, IR_GOTO, IR_RETURN, IR_ARG, IR_PARAM, IR_READ, IR_WRITE, // binop IR_ADD, IR_SUB, IR_MUL, IR_DIV, // relop IR_RELOP, // dec IR_DEC, } kind; union { struct { Operand right, left; } assign; struct { Operand result, op1, op2; } binop; struct { Operand x, y, z; int type; } relop; struct { Operand op; } single; struct { Operand var, size; } dec; } u;};
typedef struct InterCodesItem *InterCodes;struct InterCodesItem { size_t lineno; struct InterCode code; InterCodes prev, next;};将中间代码组织为双向链表
其中每一项包含了一个 InterCode 结构体
根据操作数的不同划分为多种类型
每个操作数也是一个结构体
typedef struct OperandItem *Operand;struct OperandItem { enum { OP_FUNC, OP_ADDRESS, OP_ADDRESS_ORI, OP_ADDRESS_DEREF, OP_VARIABLE, OP_CONSTANT, OP_LABEL, // for label } kind; union { size_t placeno; unsigned value; // for constant, note unsigned } u; Type type;};对操作数定义了多种类型,主要有两类
- constant
- non-constant
其中 non-constant 对应的字符串使用 placemap 存储
字符串常量池
为了在生成中间代码时能够正确的反映出 * 或 & 等前缀,进一步将 non-constant 细分
OP_FUNC / OP_VARIABLE / OP_LABEL / OP_ADDRESS- 无前缀OP_ADDRESS_ORI- 前缀为&OP_ADDRESS_DEREF- 前缀为*
关键在于区分 OP_ADDRESS / OP_ADDRESS_ORI / OP_ADDRESS_DEREF
而这需要对内存模型有所了解
内存模型
在本次实验中,只有普通变量和地址变量,地址变量的值存放在地址中,地址从 0 开始
需要注意,不存在地址的地址,也就是说,指针最多只有一层
考虑一段中间代码
FUNCTION main :DEC ir_var_a 20ir_tmp_4 := #2 * #4ir_tmp_5 := &ir_var_a + ir_tmp_4READ ir_tmp_1*ir_tmp_5 := ir_tmp_1ir_tmp_9 := #2 * #4ir_tmp_10 := &ir_var_a + ir_tmp_9WRITE *ir_tmp_10RETURN #0对其中操作数的 kind 进行说明
2:ir_var_a-OP_ADDRESS_ORI
对 IR_DEC 特判,不打印前缀 &
在第四行,打印其前缀 &
3:ir_tmp_4-OP_VARIABLE
普通变量
5:ir_tmp_5-OP_ADDRESS/6:ir_tmp_5-OP_ADDRESS_DEREF
虽然在中间代码中表现为地址变量,见第五行
但是在语境中,数组下标运算提取了其基类型,此处为 int 类型
所以在对应翻译函数返回的操作数结构体中,置 kind 为 OP_ADDRESS_DEREF,见第六行
需要注意,ir_tmp_5 只是供打印的字符串,实际的解释编码在操作数中
另外,如果基类型不是 int 类型,那么就不必进行修正,注意指针只有一层,所以还是地址变量
对于复合类型,使用线性的运算得到最终的偏移量后,再解引用得到
int值
错误处理
使用 setjmp 和 longjmp 完成非本地跳转,在 IR 模块翻译入口函数处建立快照
static void translate(struct Ast *root) { if (!setjmp(buf)) { init_ir(); build_int_type(); translate_program(root); } else { printf("IR Error: Translation fails.\n"); ir_errors++; }}主模块使用 ir_errors 判断中间代码是否正确生成
函数参数
一个比较繁琐的点
- 实参
对于 int 类型,需要传普通变量,即 OP_VARIABLE 或 OP_ADDRESS_DEREF 或 OP_CONSTANT
对于数组和结构体类型,需要传地址变量,即 OP_ADDRESS 或 OP_ADDRESS_ORI
这个问题不大
- 形参
行为类似,对于 int 类型,表现为普通变量
对于数组和结构体类型,表现为地址变量
这带来了不一致性,DEC 出的地址变量需要使用 & 前缀得到其地址,故引入了 OP_ADDRESS_ORI
而形参中的地址变量则不必使用 & 前缀,应为 OP_ADDRESS
所以使用特判,将形参中的地址变量存储为 ir_addr_xxx,其 hint 为 param
place system
本质上是个字符串常量池
不过有些小小的设计
将所有的字符串分为 5 类,分别为
- 临时变量名
- 标号名
- 函数名
- 变量名
- 形参地址变量名
使用如下的结构定义对应的前缀
static struct { const char *hint; const char *prefix;} hint_to_prefix[] = {[0] = { .hint = "tmp", .prefix = "ir_tmp_", }, [1] = { .hint = "label", .prefix = "ir_label_", }, [2] = { .hint = "func", .prefix = "", }, [3] = { .hint = "var", .prefix = "ir_var_", }, [4] = { .hint = "param", .prefix = "ir_addr_", }};这里使用了数组和结构体的初始化器
对于临时变量名和标号名,其后缀为不重复的数字,使用 next_anonymous_no 记录
其余则显式传入后缀,并且通过 load_placeno 复用
translate_exp
核心函数,所有翻译函数中唯一有返回值的函数
需要对返回的操作数提供额外的类型信息,其余操作数则不必填充
translate_exp 会被 translate_cond 和 translate_args 函数调用
同时通过自身递归调用实现复杂变量类型的翻译
如结构体数组类型和结构体中有数组类型
注意即使实验指南中有相应的要求 - 要求 3.1
- 变量 - 结构体或一维数组
- 函数参数 - 结构体
也不应限制其节点类型,否则会失去通用性
TODO
- 代码优化
暂不考虑
建议右转软件分析……
- avoid serve bool as int
引入 translate_exp_chk 检查 translate_exp 的返回值
由于 write(...) 也返回 NULL
引入 Operand 指针变量 guard 进行判断
- 复合类型直接赋值
例如对于数组类型 a, b,作赋值 b = a
由于两侧操作数类型均为 OP_ADDRESS_ORI
生成 &ir_var_b := &ir_var_a
这不合中间代码的语法要求
开摆……
- 函数返回值必须要使用
因为中间代码没有对应的格式
表现为 placeno 为 -1
目标代码生成
qtspim
$ yay -S qtspimmips32
一段简单的汇编代码
.data_prompt: .asciiz "Enter an integer:"_ret: .asciiz "\n"
.globl main
.textread: li $v0, 4 la $a0, _prompt syscall li $v0, 5 syscall jr $ra
write: li $v0, 1 syscall li $v0, 4 la $a0, _ret syscall move $v0, $0 jr $ra
main: addi $sp, $sp, -4 sw $ra, 0($sp) jal read lw $ra, 0($sp) addi $sp, $sp, 4
move $a0, $v0
addi $sp, $sp, -4 sw $ra, 0($sp) jal write lw $ra, 0($sp) addi $sp, $sp, 4
jr $ra一些约定
- 函数首 4 个参数
$a0 ~ $a3 - 函数返回值
$v0 ~ $v1 - 系统调用代码
$v0 - 函数返回地址
$ra- 跨函数需要通过栈来保存
- 调用者保存寄存器
$t0 ~ $t9 - 被调用者保存寄存器
$s0 ~ $s7
指令集参考
MIPS32 Instruction Set Quick Reference
KISS
使用朴素寄存器分配算法
仅使用寄存器 $s0 ~ $s7
只要保证同时使用的寄存器不超过 8 个即可
下面是函数调用约定,内置的 read 和 write 函数不必遵循
- 被调用者
总是保存 $ra 寄存器
使用 $fp 寄存器
subu $sp, $sp, 8sw $ra, 4($sp)sw $fp, 0($sp)addi $fp, $sp, 8...move $sp, $fplw $fp, -8($sp)lw $ra, -4($sp)jr $ra- 调用者
全部使用栈传递参数
不必保存返回地址
...subu $sp, $sp, 4 * nsw arg_1, 0($sp)...sw arg_n, (4 * n - 4)($sp)jal funcaddi $sp, $sp, 4 * n数据结构设计
使用如下三个数据结构
enum { REG_FREE = 0, REG_IN_USE };
struct RegisterDescriptor { int state; int var_no;};
struct FunctionDescriptor { const char *func_name; // for debug size_t func_no; int curr_offset_fp;};
struct VariableDescriptor { const char *var_name; // for debug size_t var_no; size_t func_no; // for offset struct { // not union, keep offset info int offset_fp; int reg_id; } pos; enum { STACK, REG } type;};FunctionDescriptor 记录当前生成对应代码的函数信息
其中 curr_offset_fp 代表 $sp 和 $fp 之间的距离
初始化为 8,即 $ra 和 old $fp
需要注意代码生成是线性的,而代码执行是栈式的
所以不必模拟执行时的栈式结构
RegisterDescriptor 记录寄存器的使用情况
对于临时使用的寄存器,其 var_no 为 -1
VariableDescriptor 记录变量信息
其中匿名结构体 pos 同时记录了 offset_fp 和 reg_id
其目的是为了当 spill variable 时,知晓存储在栈中的位置
寄存器分配范式
朴素寄存器分配算法
get_var_reg/get_tmp_reg- 获取空闲的寄存器
- 若非临时使用,则根据
var_no得到变量信息 - 若变量第一次出现,为其在栈中分配位置
- 若变量并非第一次出现,从栈中获取变量可能的最新值
generate_codegenerate_code前统一获取寄存器generate_code后统一释放寄存器- 唯一的例外是条件跳转语句
- 由于该语句对寄存器没有写入,并且控制流可能会发生变化
- 所以在
generate_code前统一释放寄存器
free_reg- 将变量可能的最新值存储到栈中
函数参数传递
在函数调用前,提前在栈中存储实参的信息
注意此时的 offset 是一个非正数
数组地址
本质上是将对应的地址存储到寄存器中
由于 free_reg 会将变量的值存储到栈中
所以栈中实际上有两种类型的数据
- 变量值
- 地址值
而地址值会在适当的时候,在 lw 和 sw 指令中使用,例如
lw %s, 0(%s)sw %s, 0(%s)编译器测试
测试生成问题(充分性)
- 随机生成输入
https://github.com/csmith-project/csmith/
- 覆盖率评估 - 程序执行
实际执行
符号执行
动态符号执行
测试预言问题(可能性)
使用间接的方式
https://dl.acm.org/doi/10.1109/APSEC.2010.39
构造在一定输入下等价的程序,判断其结果是否一致
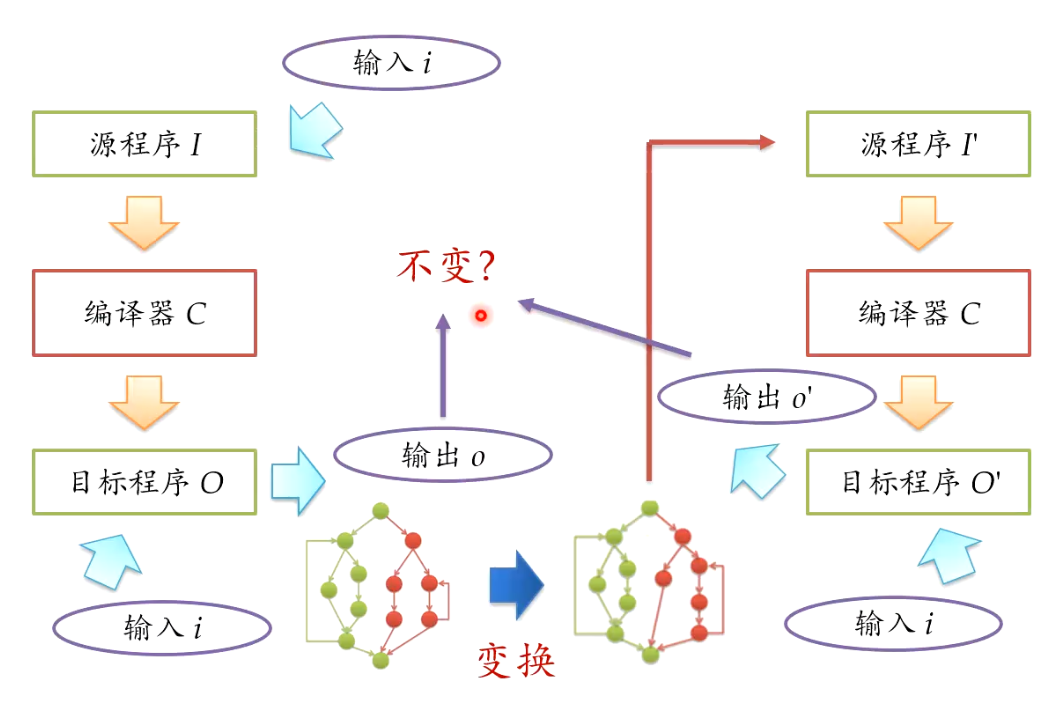
测试与验证
测试
- 动态分析
- 测试用例
验证
- 静态分析
- 软件规约
- verification (do thing correctly) and validation (do correct thing)
多线程因素
错误检测
- predictive trace analysis (PTA)
- 线程调速
- 调速采样
错误调试
- 程序插桩
- 空间开销
- 时间开销 - 加锁
- 优化 - 线程局部性 - 乐观
环境交互因素
- 基于空间采样的测试
- 根据程序执行路径划分
- 面向非确定性的验证
- 反例发现与确认