TOC
Open TOC
CMU 15-445 PROJECT
Preparation
Info
https://15445.courses.cs.cmu.edu/fall2021/
https://www.gradescope.com/account
- School: CMU
- Entry Code:
4PR8G5 - Stu ID: left empty
https://zhuanlan.zhihu.com/p/366484273
Cloning the Repo
https://github.com/cmu-db/bustub#cloning-this-repository
Build
https://github.com/cmu-db/bustub#linux—mac
似乎不支持 Ubuntu 21.04
不过只要安装了下面这些就可以了
sudo apt-get install build-essential clang-8 clang-format-8 clang-tidy-8 cmake doxygen git g++-7 pkg-config valgrind zlib1g-devclang 和 g++ 版本似乎有点老
然而 cmake .. 的时候会报错
[ 22%] Performing download step (git clone) for 'googletest'Cloning into 'googletest-src'...fatal: invalid reference: masterCMake Error at googletest-download/googletest-prefix/tmp/googletest-gitclone.cmake:40 (message): Failed to checkout tag: 'master'参考 https://github.com/google/highway/issues/457
修改 build_support/gtest_CMakeLists.txt.in 中 GIT_TAG 为 release-1.11.0 即可
Project #0 - C++ Primer
Specification
修改 src/include/primer/p0_starter.h
实现矩阵的加法、乘法和简化的通用矩阵乘法
Testing
本地测试位于 test/primer/starter_test.cpp,使用 GTest 单元测试框架
$ cd build$ make starter_test$ ./test/starter_testMake sure that you remove the DISABLED_ prefix from the test names otherwise they will not run!
Formatting
$ make format$ make check-lint$ make check-clang-tidyDevelopment Hints
不要使用 printf 进行调试,而是使用一些 LOG 宏
LOG_INFO("# Pages: %d", num_pages);LOG_DEBUG("Fetching page %d", page_id);要想启用这些宏,需要重新构建项目
$ cd build$ cmake -DCMAKE_BUILD_TYPE=DEBUG ..$ make并且在使用宏的文件中添加 #include "common/logger.h"
默认级别为 LOG_LEVEL_INFO:
// Log levels.static constexpr int LOG_LEVEL_OFF = 1000;static constexpr int LOG_LEVEL_ERROR = 500;static constexpr int LOG_LEVEL_WARN = 400;static constexpr int LOG_LEVEL_INFO = 300;static constexpr int LOG_LEVEL_DEBUG = 200;static constexpr int LOG_LEVEL_TRACE = 100;static constexpr int LOG_LEVEL_ALL = 0;Any logging method with a level that is equal to or higher than LOG_LEVEL_INFO will emit logging information.
Submission
cp --parents src/include/primer/p0_starter.h ~/Templates/在 Templates 文件夹下
zip -r project0-submission.zip srcNote
- 访问父类 protected 成员需要加上
this-> - 函数体内可以直接返回
make_unique出的 unique_ptr - 一些 vim plugs 可以帮助 format 和诊断风格错误
- 注意抛出异常的格式
throw Exception(ExceptionType::OUT_OF_RANGE, "Index out of range.");Project #1 - Buffer Pool Manager
Specification
线程安全
分为三个部分
- LRU Replacement Policy
- Buffer Pool Manager Instance
- Parallel Buffer Pool Manager
LRU Replacement Policy
修改
src/include/buffer/lru_replacer.h
src/buffer/lru_replacer.cpp
需要实现四个函数
具体的使用见测试用例 test/buffer/lru_replacer_test.cpp
思路是 list + set + shared_mutex
list 便于在结尾插入,在任意位置删除
set 便于查找 list 中是否存在对应的 frame_id
shared_mutex 则用于线程间同步,使用读写锁优化一丢丢性能
Buffer Pool Manager Instance
修改
src/include/buffer/buffer_pool_manager_instance.h
src/buffer/buffer_pool_manager_instance.cpp
需要注意 frame_id 对应 pages 的下标
page_id 与 pages 的下标完全无关,可能是 AllocatePage 处的新页,也可能是之前的页
也就是说 page 只是一个容器,可以认为是 frame
有如下元数据
/** The actual data that is stored within a page. */ char data_[PAGE_SIZE]{}; /** The ID of this page. */ page_id_t page_id_ = INVALID_PAGE_ID; /** The pin count of this page. */ int pin_count_ = 0; /** True if the page is dirty, i.e. it is different from its corresponding page on disk. */ bool is_dirty_ = false; /** Page latch. */ ReaderWriterLatch rwlatch_;其中的 pin_count 的更新问题需要再斟酌,目前的方案是
- NewPgImp 和 FetchPgImp 在更新 page 时置 pin_count 为 1
- UnpinPgImp 将 pin_count 减 1,若 ≤ 0,则 Unpin
- FetchPgImp 在存在对应的 page 时 Pin,pin_count 加 1
- DeletePgImp 置 pin_count 为 0,直接插入 free_list
DiskManager 则提供了 WritePage 和 ReadPage 方法
通过 page_id 读数据到 page 中,写数据到 disk 中
线程同步方面,使用三个读写锁保护 free_list, pages 和 page_table
DiskManager 似乎自带线程同步
Replacer 目前暂未考虑
也可以考虑使用 page 自带的 rwlatch_ 进行同步
测试用例 SampleTest 的理解如下
| frame id | page id |
|---|---|
| 0 | 0 → 10 |
| 1 | 1 → 11 |
| 2 | 2 → 12 |
| 3 | 3 → 13 |
| 4 | 4 → 0 |
| 5 | 5 |
| 6 | 6 |
| 7 | 7 |
| 8 | 8 |
| 9 | 9 |
Parallel Buffer Pool Manager
修改
src/include/buffer/parallel_buffer_pool_manager.h
src/buffer/parallel_buffer_pool_manager.cpp
维护多个 BufferPoolManagerInstances
比如 num_instances 为 5,pool_size 为 10,
那么 instance[i] 维护的页面满足 page_id % 5 = i
Submission
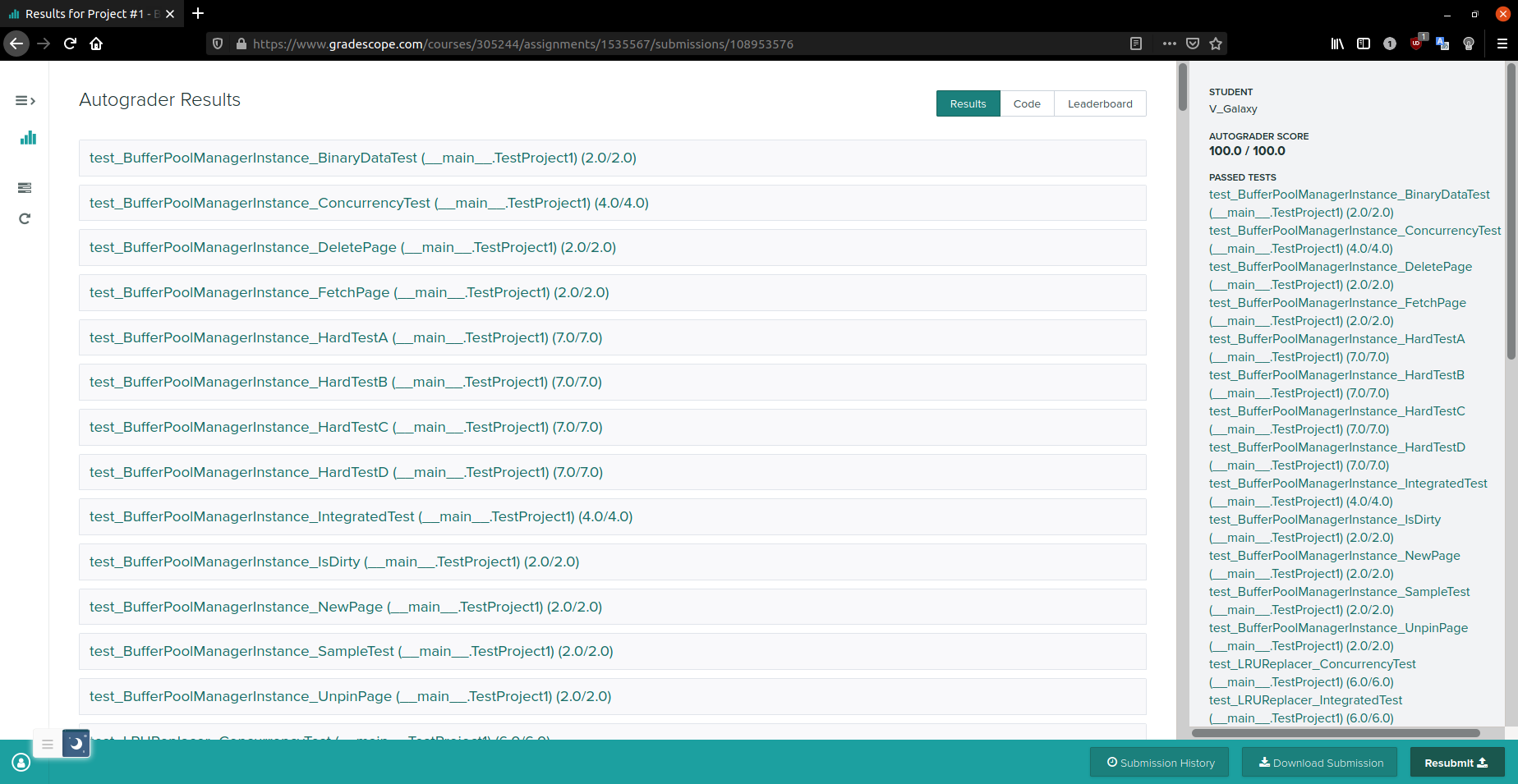
The autograder failed to execute correctly. Please ensure that your submission is valid. Contact your course staff for help in debugging this issue. Make sure to include a link to this page so that they can help you most effectively.移除了一些 C++17 的特性,加上了一个 #include <algorithm>,就可以了
Discord forum: https://discord.gg/YF7dMCg 是个好东西
喜提 82 分
注意 UnpinPgImp 中 is_dirty 的含义
若 page 已经 dirty,无论 is_dirty 取什么,page 仍然为 dirty
若 page 没有 dirty,那么 page.is_dirty_ 就和 is_dirty 一致
所以是一个 OR 操作,而非赋值操作
page.is_dirty_ |= is_dirty;82 → 85
然后优化了一下锁
85 → 96
最后的 4 分 RoundRobinNewPage
[ RUN ] ParallelBufferPoolManagerTest.RoundRobinNewPage/autograder/bustub/test/buffer/grading_parallel_buffer_pool_manager_test.cpp:1019: FailureExpected equality of these values: unpin_page + num_instances Which is: 16 page_id_temp Which is: 216/autograder/bustub/test/buffer/grading_parallel_buffer_pool_manager_test.cpp:1029: FailureExpected equality of these values: unpin_page + num_instances Which is: 17 page_id_temp Which is: 217/autograder/bustub/test/buffer/grading_parallel_buffer_pool_manager_test.cpp:1042: FailureExpected equality of these values: unpin_page + num_instances Which is: 11 page_id_temp Which is: 251[ FAILED ] ParallelBufferPoolManagerTest.RoundRobinNewPage (0 ms)大年初三发现突然进群,于是得到了完整的测试用例
然后发现是 AllocatePage 的位置不对,应该在 NewPgImp 不返回 nullptr 之后才分配
96 → 100
但是看一眼 leaderboard,运行时间为 60 多秒
后续可能还需要优化
Project #2 Extendible Hash Index
Specification
分为三个部分
-
Page Layouts
-
Extendible Hashing Implementation
-
Concurrency Control
Page Layouts
一些宏
#define MappingType std::pair<KeyType, ValueType>#define HASH_TABLE_BUCKET_TYPE HashTableBucketPage<KeyType, ValueType, KeyComparator>#define DIRECTORY_ARRAY_SIZE 512#define BUCKET_ARRAY_SIZE (4 * PAGE_SIZE / (4 * sizeof(MappingType) + 1))一个页大小为 4KB
对于 Directory Page 而言,由于数组大小为 512,代表 GD(GlobalDepth) 最大为 9
对于 Bucket Page 而言,数组大小与 MappingType 相关,另外每一项需要 2 bits 记录元数据,相当于 ¼ 字节
private: // For more on BUCKET_ARRAY_SIZE see storage/page/hash_table_page_defs.h char occupied_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1]; // 0 if tombstone/brand new (never occupied), 1 otherwise. char readable_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1]; // Do not add any members below array_, as they will overlap. MappingType array_[0];记录元数据的数组向上取整为 8 的倍数
而 array_ 使用了 flexible array member 技术
需要实现的函数如下
Bucket Page:
src/include/storage/page/hash_table_directory_page.h src/storage/page/hash_table_directory_page.cpp
- Insert
- Remove
- IsOccupied
- IsReadable
- KeyAt
- ValueAt
Directory Page:
src/include/storage/page/hash_table_bucket_page.h src/storage/page/hash_table_bucket_page.cpp
- GetGlobalDepth
- IncrGlobalDepth
- SetLocalDepth
- SetBucketPageId
- GetBucketPageId
本地测试位于 container/hash_table_page_test.cpp
Extendible Hashing Implementation
src/include/container/hash/extendible_hash_table.h src/container/hash/extendible_hash_table.cpp
Google 机翻一波
此实现要求您实现存储桶拆分/合并和目录增长/收缩。可扩展散列的一些实现跳过了桶的合并,因为它可能在某些情况下导致抖动。我们在这里实现它是为了提供对数据结构的全面理解,并为学习如何管理闩锁、锁、页面操作(获取/锁定/删除/等)提供更多机会。
- 目录索引
插入哈希索引时,您将希望使用最低有效位来索引目录。当然,可以正确使用最高有效位,但使用最低有效位会使目录扩展操作更加简单。
- 拆分桶
如果没有插入空间,则必须拆分存储桶。如果您发现这样更容易,您可以在桶装满后立即拆分。但是,仅当插入溢出页面时,参考解决方案才会拆分。因此,您可能会发现提供的 API 更适合这种方法。与往常一样,欢迎您考虑自己的内部 API。
- 合并桶
当存储桶变空时,必须尝试合并。有一些方法可以通过检查存储桶的占用率及其分割图像来更积极地进行合并,但是这些昂贵的检查和额外的合并会增加抖动。
为了使事情相对简单,我们提供了以下合并规则:
只能合并空桶。只有当它们的分割图像具有相同的局部深度时,桶才能与其分割图像合并。只有局部深度大于 0 的桶才能被合并。如果您对“分割图像”感到困惑,请查看算法和代码文档。这个概念很自然地就消失了。
- 目录增长
这没有什么花哨的规则。您要么必须增加目录,要么不需要。
- 目录收缩
仅当每个存储桶的局部深度严格小于目录的全局深度时才收缩目录。您可能会看到其他用于缩小目录的测试,但这个测试很简单,因为我们将本地深度保留在目录页面中。
- 性能
一个重要的性能细节是仅在需要时才使用写锁和闩锁。总是使用写锁将不可避免地在 Gradescope 上超时。
此外,一种潜在的优化是将您自己的扫描类型考虑到存储桶页面上,这可以避免在某些情况下重复扫描。您会发现检查存储桶页面的许多内容通常涉及全面扫描,因此您可以一次性收集所有这些信息。
本地测试位于 test/container/hash_table_test.cpp
内存安全检测
cd buildmake -j hash_table_testvalgrind --trace-children=yes \ --leak-check=full \ --track-origins=yes \ --soname-synonyms=somalloc=*jemalloc* \ --error-exitcode=1 \ --suppressions=../build_support/valgrind.supp \ ./test/hash_table_test不过需要运行一分多钟……
关键在于拆分桶的两种情形和合并桶
尤其是对 split image 的理解
uint32_t HashTableDirectoryPage::GetLocalHighBit(uint32_t bucket_idx) { // after increasing local depth return 1 << (GetLocalDepth(bucket_idx) - 1);}
uint32_t HashTableDirectoryPage::GetSplitImageIndex(uint32_t bucket_idx) { // after increasing local depth if (GetLocalDepth(bucket_idx) == 0) { return 0; } uint32_t bucket_local_high_bit = GetLocalHighBit(bucket_idx); uint32_t split_image_idx; if ((bucket_idx & bucket_local_high_bit) == bucket_local_high_bit) { split_image_idx = bucket_idx & (~bucket_local_high_bit); } else { split_image_idx = bucket_idx | bucket_local_high_bit; } return split_image_idx;}Concurrency Control
仍然机翻一波
到目前为止,您可以假设您的哈希表仅支持单线程执行。在最后一个任务中,您将修改您的实现,使其支持同时读取/写入表的多个线程。
您需要在每个存储桶上都有锁存器,这样当一个线程写入存储桶时,其他线程也不会读取或修改该索引。您还应该允许多个阅读器同时阅读同一个存储桶。
当您需要拆分或合并存储桶以及全局深度发生变化时,您将需要锁定整个哈希表。
有多种并发控制机制
table_latch_- page 内部的 ReaderWriterLatch
/** Zeroes out the data that is held within the page. */ inline void ResetMemory() { memset(data_, OFFSET_PAGE_START, PAGE_SIZE); }
/** The actual data that is stored within a page. */ char data_[PAGE_SIZE]{}; /** The ID of this page. */ page_id_t page_id_ = INVALID_PAGE_ID; /** The pin count of this page. */ int pin_count_ = 0; /** True if the page is dirty, i.e. it is different from its corresponding page on disk. */ bool is_dirty_ = false; /** Page latch. */ ReaderWriterLatch rwlatch_;注意 Directory Page 和 Bucket Page 仅仅使用了 Page 中 data_ 成员的内存空间,所以可以安全的 reinterpret_cast<Page *>,然后再使用 rwlatch_
- LockManager 和 Transaction pointer argument
Project 4 会用到,目前不考虑
Submission
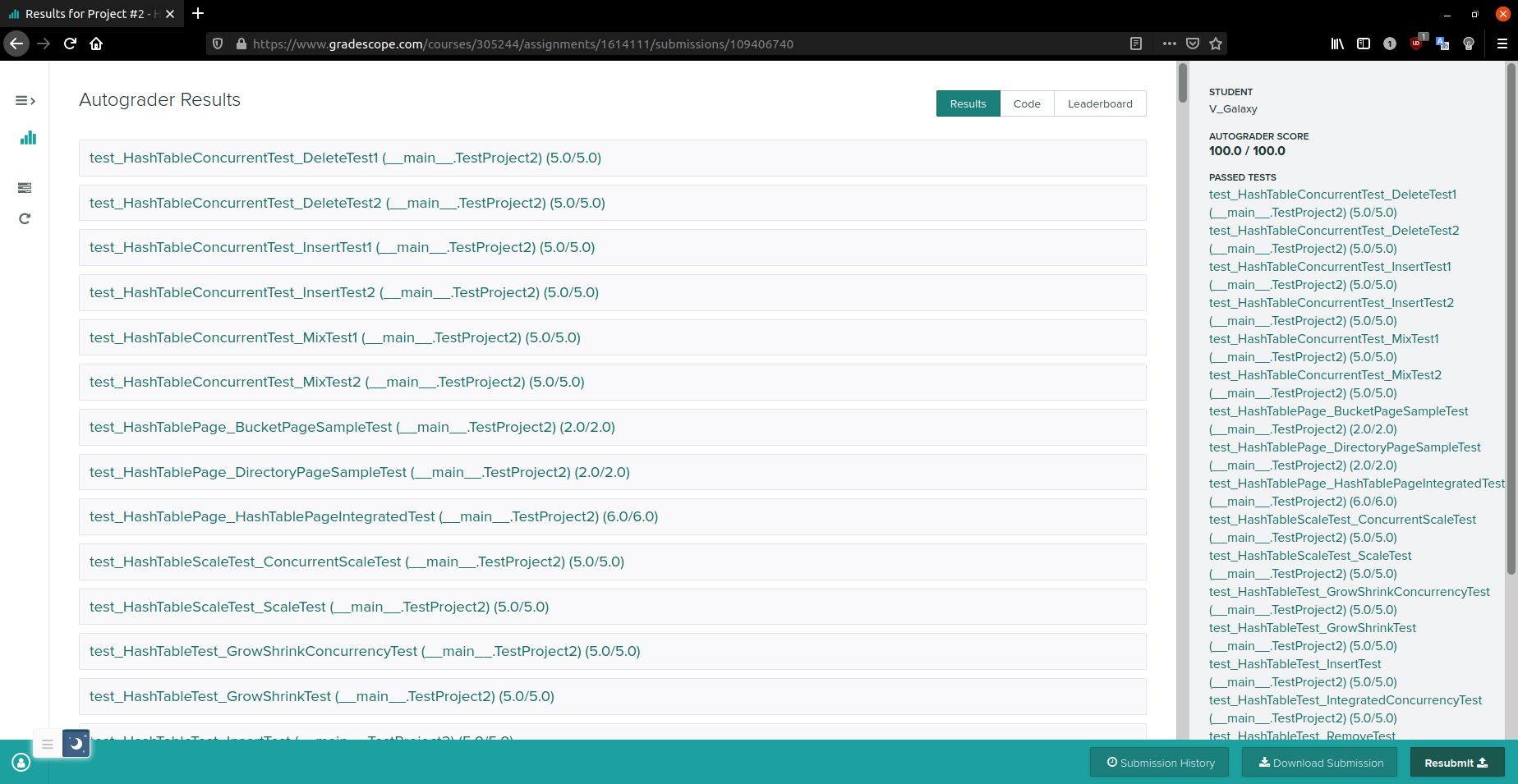
首先与 format 和 check-lint 进行了一番斗争
然后提交直接满分……
看了一眼 leaderboard 时间为 85.1
尝试优化了一下 extendible_hash_table 中的并发控制
使用 page 内部的 ReaderWriterLatch 进行更精细的控制
似乎没有必要使用 table_latch_
然后并发大失败,并且时间似乎并没有优化多少,故放弃……
每次的错误输出并不一定相同
在对应的 test 文件夹添加新的测试,然后在 build 中
cmake ..,就可以make grading_hash_table_test啦
一些需要注意的地方
- buffer pool manager 进一步优化
- rehash 时,由于只会插入到 bucket_page 或 split_image_page 中,所以可以扫描一遍 bucket_page,将对应的 pairs 直接插入到 split_image_page 中,而不是 CollectAndRemoveAll 后再重新插入
- Bucket Page 中的插入和删除操作并未遵循有序性,虽然注释写了
keys are stored in order,但实现起来似乎比较繁琐,成本较高 - Bucket Page 中 IsFull 和 IsEmpty 操作需要扫描一遍 bit map,可以在 Directory Page 中引入 uint16_t 的数组,记录每个 Bucket Page 中 readable 的数量
- 若相同 key 的数量超过 Bucket Page 的容量,由于没有实现 overflow page,会陷入无限循环
Project #3 - Query Execution
Specification
需要实现 executors 以完成下列 operations
- Access Methods: Sequential Scan
- Modifications: Insert, Update, Delete
- Miscellaneous: Nested Loop Join, Hash Join, Aggregation, Limit, Distinct
使用 Iterator Model
各 executors 的输出为 Record ID
For each query plan operator type, there is a corresponding executor object that implements the Init and Next methods.
Each executor is responsible for processing a single plan node type.
本地测试位于 test/execution/executor_test.cpp
RTFSC
先看测试用例 test/execution/executor_test.cpp
发现一个重要的文件 test/execution/executor_test_util.h
其中的 SetUp() 函数使用 TableGenerator 对象生成了一系列的表
定位到 src/catalog/table_generator.cpp 可以得到表的元数据,如
// Table 1 {"test_1", TEST1_SIZE, {{"colA", TypeId::INTEGER, false, Dist::Serial, 0, 0}, {"colB", TypeId::INTEGER, false, Dist::Uniform, 0, 9}, {"colC", TypeId::INTEGER, false, Dist::Uniform, 0, 9999}, {"colD", TypeId::INTEGER, false, Dist::Uniform, 0, 99999}}},代表 test_1 表有 TEST1_SIZE 行,有 4 列,并给出了各列的 value 类型和分布
TableInsertMeta 和 ColumnInsertMeta
下面通过元数据构造表
for (auto &table_meta : insert_meta) { // Create Schema std::vector<Column> cols{}; cols.reserve(table_meta.col_meta_.size()); for (const auto &col_meta : table_meta.col_meta_) { if (col_meta.type_ != TypeId::VARCHAR) { cols.emplace_back(col_meta.name_, col_meta.type_); } else { cols.emplace_back(col_meta.name_, col_meta.type_, TEST_VARLEN_SIZE); } } Schema schema(cols); auto info = exec_ctx_->GetCatalog()->CreateTable(exec_ctx_->GetTransaction(), table_meta.name_, schema); FillTable(info, &table_meta); }其大概流程是先通过元数据构造 Schema,然后通过 Schema 构造 TableInfo,再通过元数据填充 TableInfo
下面快速了解一下类之间的关系
catalog
- Catalog 类维护了一系列的 TableInfo 和 IndexInfo
- TableInfo 类维护了 table 的 Schema 和 TableHeap
- IndexInfo 类维护了 key index 的 Schema 和 Index
- Schema 类维护了一系列的 Column
- Column 类含有 TypeId 和 AbstractExpression 等信息
table
- TableHeap represents a physical table on disk. This is just a doubly-linked list of pages.
- InsertTuple
- ……
- TableIterator enables the sequential scan of a TableHeap.
- Tuple 类维护了 RID 和实际的数据
- RID 即为
page_id + offset/slot - 通过
vector<Value>和 Schema 构造 Tuple
- RID 即为
type
TypeId 如下
enum TypeId { INVALID = 0, BOOLEAN, TINYINT, SMALLINT, INTEGER, BIGINT, DECIMAL, VARCHAR, TIMESTAMP };Type 类为 TypeId 的实例,提供了(虚)比较函数和数学函数,使用单例模式
Value 类存储了实际的值
union Val { int8_t boolean_; int8_t tinyint_; int16_t smallint_; int32_t integer_; int64_t bigint_; double decimal_; uint64_t timestamp_; char *varlen_; const char *const_varlen_; } value_;ValueFactory 类使用了简单工厂模式,包装了从实际的值到 Value 类的构造函数
expression
AbstractExpression is the base class of all the expressions in the system.
Expressions are modeled as trees, i.e. every expression may have a variable number of children.
- AggregateValueExpression
- ColumnValueExpression
- ComparisonExpression
- ConstantValueExpression
execution
ExecutorContext 类中维护了 Catalog 对象
ExecutorFactory 类中有静态方法 CreateExecutor,根据 ExecutorContext 和 AbstractPlanNode 构造出对应的 AbstractExecutor
在 ExecutionEngine 类中,通过这个 AbstractExecutor 执行相关逻辑
bool Execute(const AbstractPlanNode *plan, std::vector<Tuple> *result_set, Transaction *txn, ExecutorContext *exec_ctx) { // Construct and executor for the plan auto executor = ExecutorFactory::CreateExecutor(exec_ctx, plan);
// Prepare the root executor executor->Init();
// Execute the query plan try { Tuple tuple; RID rid; while (executor->Next(&tuple, &rid)) { if (result_set != nullptr) { result_set->push_back(tuple); } } } catch (Exception &e) { // TODO(student): handle exceptions }
return true; }Sequential Scan
开始机翻
SeqScanExecutor 遍历一个表并一次一个地返回它的元组。顺序扫描由 SeqScanPlanNode 指定。计划节点指定执行扫描的表。计划节点还可以包含谓词;如果元组不满足谓词,则扫描不会产生它。
提示:使用 TableIterator 对象时要小心。确保您了解前置增量和后置增量运算符之间的区别。通过在 ++iter 和 iter++ 之间切换,您可能会发现自己得到奇怪的输出。
提示:您将希望在顺序扫描计划节点中使用谓词。特别是,看看 AbstractExpression::Evaluate。请注意,这将返回一个 Value,您可以在其上调用 GetAs<bool>() 以将结果评估为原生 C++ 布尔类型。
提示:顺序扫描的输出是每个匹配元组及其原始记录标识符 (RID) 的副本。主要还是要理清类之间的关系
注意在进入构造函数花括号前,所有对象都已经构造好了
所以如果某些对象没有默认构造函数,又没有在初始化列表中初始化,就会报错
还需要注意初始化的顺序,否则会报错 -Werror=reorder
不太理解如果可以在构造函数的初始化一切东西,那还需要 Init() 干什么
RID 应该和原 tuple 一致
不能使用 new,否则会出现内存泄露
不理解构造的 tuple 出了作用域为什么不会被析构,可能是有指针引用
自增 iterator_curr 的位置比较重要
Insert
继续机翻
InsertExecutor 将元组插入到表中并更新索引。您的执行程序必须支持两种类型的插入。
第一种类型是插入操作,其中要插入的值直接嵌入到计划节点本身中。我们将这些称为原始插入。
第二种类型是从子执行器中获取要插入的值的插入。例如,您可能有一个带有 SeqScanPlanNode 的 InsertPlanNode 作为子节点来实现 INSERT INTO .. SELECT ...
您可以假设 InsertExecutor 始终位于它所在的查询计划的根目录。InsertExecutor 不应修改其结果集。
提示:您需要在执行器初始化期间查找插入目标的表信息。有关访问目录的更多信息,请参阅下面的系统目录部分。
提示:您需要更新插入元组的表的所有索引。有关详细信息,请参阅下面的索引更新部分。
提示:您将需要使用 TableHeap 类来执行表修改。然后机翻 Additional Information
- 系统目录
数据库维护一个内部目录以跟踪有关数据库的元数据。在这个项目中,您将与系统目录交互以查询有关表、索引及其模式的信息。
整个目录实现在 src/include/catalog.h 中。您应该特别注意成员函数 Catalog::GetTable() 和 Catalog::GetIndex()。您将在执行程序的实现中使用这些函数来查询表和索引的目录。- 索引更新
对于表修改执行器(InsertExecutor、UpdateExecutor 和 DeleteExecutor),您必须修改操作所针对的表的所有索引。您可能会发现 Catalog::GetTableIndexes() 函数对于查询为特定表定义的所有索引很有用。一旦您拥有每个表索引的 IndexInfo 实例,您就可以在底层索引结构上调用索引修改操作。
在这个项目中,我们使用您对项目 2 中可扩展哈希表的实现作为所有索引操作的基础数据结构。因此,该项目的成功完成依赖于可扩展哈希表的工作实现。有三个相关的本地测试
- SimpleRawInsertTest
child_executor 为空的情形
- SimpleSelectInsertTest
child_executor 不为空的情形
- SimpleRawInsertWithIndexTest
需要更细致的了解 index 的实现
测试中有两个相关的函数 ParseCreateStatement 和 CreateIndex
其中 ParseCreateStatement 根据字符串提取出索引的名称和类型
CreateIndex 为 Catalog 类的成员函数,重点在下面两行
// Construct index metdata auto meta = std::make_unique<IndexMetadata>(index_name, table_name, &schema, key_attrs);
// Construct the index, take ownership of metadata // TODO(Kyle): We should update the API for CreateIndex // to allow specification of the index type itself, not // just the key, value, and comparator types auto index = std::make_unique<ExtendibleHashTableIndex<KeyType, ValueType, KeyComparator>>(std::move(meta), bpm_, hash_function);先构造 IndexMetadata 对象,再构造 ExtendibleHashTableIndex 对象
ExtendibleHashTableIndex 类继承了 Index 类
Index 类中维护了 IndexMetadata
ExtendibleHashTableIndex 类中维护了 ExtendibleHashTable,也就是 Project #2 中实现的东西
需要注意 index 的 value 总为 RID
还有一个比较重要的函数是 KeyFromTuple
Tuple Tuple::KeyFromTuple(const Schema &schema, const Schema &key_schema, const std::vector<uint32_t> &key_attrs) { std::vector<Value> values; values.reserve(key_attrs.size()); for (auto idx : key_attrs) { values.emplace_back(this->GetValue(&schema, idx)); } return Tuple(values, &key_schema);}其中的 key_attrs 实际上是 Schema 中 Column 的索引集合
Update
UpdateExecutor 修改指定表中的现有元组并更新其索引。子执行器将提供更新执行器将修改的元组(及其 RID)。
与 InsertExecutor 不同,UpdateExecutor 总是从子执行程序中提取元组来执行更新。例如,UpdatePlanNode 将有一个 SeqScanPlanNode 作为其子节点。
您可以假设 UpdateExecutor 始终位于它所在的查询计划的根目录。UpdateExecutor 不应修改其结果集。
提示:我们为您提供了一个 GenerateUpdatedTuple,它根据计划节点中提供的更新属性为您构造一个更新的元组。
提示:您需要在执行器初始化期间查找更新目标的表信息。有关访问目录的更多信息,请参阅下面的系统目录部分。
提示:您将需要使用 TableHeap 类来执行表修改。
提示:您需要更新执行更新的表的所有索引。有关详细信息,请参阅下面的索引更新部分。类似 Insert,不过 child_executor 一定不为空
Update 没有本地测试,于是将本地测试替换为 full-test 中的 executor_test.cpp
注意 UpdatePlanNode 中有映射 column index -> update operation
比如 1 -> Add 1 代表将第一列加上一
对于索引的更新,目前的处理为删除旧索引,添加新索引
Delete
DeleteExecutor 从表中删除元组并从所有表索引中删除它们的条目。像更新一样,要删除的元组是从子执行器中提取的,例如 SeqScanExecutor 实例。
您可以假设 DeleteExecutor 始终位于它所在的查询计划的根目录。DeleteExecutor 不应修改其结果集。
提示:您只需要从子执行器获取 RID 并调用 TableHeap::MarkDelete() 即可有效删除元组。所有删除都将在事务提交时应用。
提示:您需要更新删除元组的表的所有索引。有关详细信息,请参阅下面的索引更新部分。类似 Insert,不过 child_executor 一定不为空
Nested Loop Join
NestedLoopJoinExecutor 实现了一个基本的嵌套循环连接,它将来自其两个子执行器的元组组合在一起。
这个执行器应该实现讲座中介绍的简单嵌套循环连接算法。也就是说,对于连接外部表中的每个元组,您应该考虑连接内部表中的每个元组,如果满足连接谓词,则发出一个输出元组。
该项目的学习目标之一是让您了解逻辑运算符的不同物理实现的优缺点。出于这个原因,重要的是您的 NestedLoopJoinExecutor 实际上实现了嵌套循环连接算法,而不是例如为哈希连接执行器重用您的实现(见下文)。为此,我们将测试您的 NestedLoopJoinExecutor 的 IO 成本,以确定它是否正确实现了算法。
提示:您将希望在嵌套循环连接计划节点中使用谓词。特别是,看看 AbstractExpression::EvaluateJoin,它处理左元组和右元组及其各自的模式。请注意,这将返回一个 Value,您可以在其上调用 GetAs<bool>() 以将结果评估为原生 C++ 布尔类型。根据 Column 中的 AbstractExpression 判断该列属于哪个表
没有必要,直接使用 EvaluateJoin 即可
由于在 Next 中维持状态较为困难,尝试在 Init 中完成一切工作
然而这样做会无法通过 IO Test,尝试在 Sequential Scan 添加无操作的扫描会出现内存问题
考虑在 Sequential Scan 的 Init 时重置迭代器的状态,就没有内存问题了
有点奇怪的 RID,不过测试中并没有检测
Hash Join
HashJoinExecutor 实现了一个哈希连接操作,它将来自它的两个子执行器的元组组合在一起。
顾名思义(正如讲座中所讨论的),哈希连接操作是在哈希表的帮助下实现的。出于本项目的目的,我们做了一个简化假设,即连接哈希表完全适合内存。这意味着您无需担心在您的实现中将构建侧表的临时分区溢出到磁盘。
与 NestedLoopJoinExecutor 一样,我们将测试您的 HashJoinExecutor 的 IO 成本,以确定它是否正确实现了哈希连接算法。
提示:您的实现应该正确处理多个元组(在连接的任一侧)共享一个公共连接键的情况。
提示:HashJoinPlanNode 定义了 GetLeftJoinKey() 和 GetRightJoinKey() 成员函数;您应该使用这些访问器返回的表达式分别为连接的左侧和右侧构造连接键。
提示:您将需要一种方法来散列具有多个属性的元组以构造唯一键。作为起点,看一下 AggregationExecutor 中的 SimpleAggregationHashTable 如何实现此功能。
提示:回想一下,在查询计划的上下文中,哈希连接的构建端是管道中断器。这可能会影响您在实现中使用 HashJoinExecutor::Init() 和 HashJoinExecutor::Next() 函数的方式。特别要考虑join的Build阶段是应该在HashJoinExecutor::Init()还是HashJoinExecutor::Next()中进行。JoinKeyExpression 表明了为单列 Join
Hash Join 可以在 Init 中完成一切工作
为了构造哈希表,模仿 AggregationExecutor,在 hash_join_executor.h 中添加
namespace bustub {
struct HashJoinKey { std::vector<Value> values_;
bool operator==(const HashJoinKey &other) const { for (uint32_t i = 0; i < other.values_.size(); i++) { if (values_[i].CompareEquals(other.values_[i]) != CmpBool::CmpTrue) { return false; } } return true; }};
struct HashJoinValue { std::vector<Tuple> tuples_;};
} // namespace bustub
namespace std {
/** Implements std::hash on HashJoinKey */template <>struct hash<bustub::HashJoinKey> { std::size_t operator()(const bustub::HashJoinKey &key) const { size_t curr_hash = 0; for (const auto &key : key.values_) { if (!key.IsNull()) { curr_hash = bustub::HashUtil::CombineHashes(curr_hash, bustub::HashUtil::HashValue(&key)); } } return curr_hash; }};
} // namespace std不能修改 hash_join_plan.h
这样做的可能的思路是,Value 类没有重载 == 运算符,我们使用 HashJoinKey 将其包装起来,并在内部重载运算符时使用成员函数 CompareEquals,这样可以保证相等性是由 Value 类内部的 value_ 所决定的,又实现了哈希表键的多态性
另外需要特化对 bustub::HashJoinKey 的 hash 函数
注意顺序
注意 HashJoinValue 应为 std::vector<Tuple>,否则无法处理 OuterTableDuplicateJoinKeys 的情形
但似乎没有必要使用 std::vector<Value>
这样就可以使用
std::unordered_map<HashJoinKey, HashJoinValue> map_;另外在 dynamic_cast 时需要将对象的头文件包含进来,否则会报错 ISO C++ forbids declaration of ‘type name’ with no type
还有 output_schema 里列的名称不一定与原 schema 中的名称对应,所以应该这样获得对应列的值
const ColumnValueExpression *column_expr = dynamic_cast<const ColumnValueExpression *>(column.GetExpr());uint32_t column_idx = column_expr->GetColIdx();Value value = tuple_ori.GetValue(schema_, column_idx);后来发现可以简化为
Value value = column.GetExpr()->Evaluate(&tuple_ori, schema_);Aggregation
该执行器将来自单个子执行器的多个元组结果组合成一个元组。在这个项目中,我们要求您实现 COUNT、SUM、MIN 和 MAX 聚合。您的 AggregationExecutor 还必须支持 GROUP BY 和 HAVING 子句。
正如讲座中所讨论的,实现聚合的常见策略是使用哈希表。这是您将在本项目中使用的方法,但是,我们做一个简化假设,即聚合哈希表完全适合内存。这意味着您无需担心为散列聚合实现两阶段(分区、重新散列)策略,而是可以假设您的所有聚合结果都可以驻留在内存中的散列表中。
此外,我们为您提供了 SimpleAggregationHashTable 数据结构,该结构公开了内存中的哈希表 (std::unordered_map),但具有设计用于计算聚合的接口。此类还公开了可用于遍历哈希表的 SimpleAggregationHashTable::Iterator 类型。
提示:您需要汇总结果并使用 HAVING 子句进行约束。特别是,看看 AbstractExpression::EvaluateAggregate,它处理不同类型表达式的聚合评估。请注意,这将返回一个 Value,您可以在其上调用 GetAs<bool>() 以将结果评估为原生 C++ 布尔类型。
提示:回想一下,在查询计划的上下文中,聚合是管道破坏者。这可能会影响您在实现中使用 AggregationExecutor::Init() 和 AggregationExecutor::Next() 函数的方式。特别要考虑聚合的 Build 阶段是应该在 AggregationExecutor::Init() 还是 AggregationExecutor::Next() 中执行。同样在 Init 中完成一切工作
需要理清楚 plan 和 executor 和 hashtable 的关系
hashtable 中的键是 group_by 的列的取值的集合
虽然命名为 AggregateKey
hashtable 中的值是 aggregate 的列的聚合结果的集合
当没有 group_by 列时,手动添加一列,并且取值相同
有些上下文中的表达式只能是某种表达式
如这里 output_schema 中 column 的表达式应均为 AggregateValueExpression
Limit
LimitExecutor 限制来自其子执行器的输出元组的数量。如果其子执行器生成的元组数小于 LimitPlanNode 中指定的限制,则此执行器无效并产生它接收到的所有元组。过于简单,略去
Distinct
DistinctExecutor 消除从其子执行器接收到的重复元组。在确定唯一性时,您的 DistinctExecutor 应该考虑输入元组的所有列。
与聚合一样,不同的运算符通常是在哈希表的帮助下实现的(这是一个哈希不同的操作)。这是您将在本项目中使用的方法。与在 AggregationExecutor 和 HashJoinExecutor 中一样,您可以假设用于实现 DistinctExecutor 的哈希表完全适合内存。
提示:您将需要一种方法来散列具有潜在许多属性的元组,以便构造唯一键。作为起点,看一下 AggregationExecutor 中的 SimpleAggregationHashTable 如何实现此功能。类似 Hash Join,在 distinct_executor.h 中添加对应的 DistinctKey
注意到 scan 的 schema 和 distinct 的 schema 是一样的,所以可以直接使用 unordered_set 保存 tuple
发现这里不能使用 Evaluate 的方式获取 value,因为 expr 的列索引是根据 table_info->schema 而定义的,但 scan 出的 tuple 不一定满足这个 schema
另外,调试时发现可以通过如下的方式获取枚举类的值
LOG_DEBUG("%d", static_cast<std::underlying_type_t<TypeId>>(column.GetType()));Project #4 - Concurrency Control
Task #1 - Lock Manager
开始机翻
为了确保事务操作的正确交错,DBMS 将使用锁管理器 (LM) 来控制何时允许事务访问数据项。LM 的基本思想是它维护一个关于当前由活动事务持有的锁的内部数据结构。然后事务在被允许访问数据项之前向 LM 发出锁定请求。LM 将向调用事务授予锁、阻止该事务或中止它。
在您的实现中,将有一个用于整个系统的全局 LM(类似于您的缓冲池管理器)。每当事务想要访问/修改元组时,TableHeap 和 Executor 类将使用您的 LM 获取元组记录上的锁(通过记录 id RID)。
此任务需要您实现一个元组级 LM,它支持三种常见的隔离级别:READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ。锁管理器应根据事务的隔离级别授予或释放锁。详情请参阅讲座幻灯片。
在存储库中,我们为您提供了带有隔离级别属性(即 READ_UNCOMMITED、READ_COMMITTED 和 REPEATABLE_READ)的事务上下文句柄 (include/concurrency/transaction.h) 以及有关其获取的锁的信息。LM 将需要检查事务的隔离级别并公开锁定/解锁请求的正确行为。任何失败的锁定操作都应导致 ABORTED 事务状态(隐式中止)并引发异常。事务管理器将进一步捕获此异常并回滚事务执行的写操作。提示
虽然您的锁管理器需要使用死锁预防,但我们建议您首先实现您的锁管理器而不进行任何死锁处理,然后在您验证它正确锁定并在没有死锁发生时解锁后添加预防机制。
您将需要一些方法来跟踪哪些事务正在等待锁定。查看 lock_manager.h 中的 LockRequestQueue 类。
LockUpgrade 对 LockRequestQueue 的操作意味着什么?
您将需要一些方法来通知正在等待的事务何时可能要获取锁。我们建议使用 std::condition_variable
虽然某些隔离级别是通过确保严格的两阶段锁定的属性来实现的,但您的锁管理器的实现只需要确保两阶段锁定的属性。严格 2PL 的概念将通过您的执行器和事务管理器中的逻辑来实现。看看那里的 Commit 和 Abort 方法。
您还应该维护交易状态。例如,由于解锁操作,事务的状态可能会从 GROWING 阶段变为 SHRINKING 阶段(提示:查看 transaction.h 中的方法)
您还应该使用 shared_lock_set_ 和 exclusive_lock_set_ 跟踪事务获取的共享/独占锁,以便当 TransactionManager 想要提交/中止事务时,LM 可以正确释放它们。
将事务的状态设置为 ABORTED 会隐式中止它,但在调用 TransactionManager::Abort 之前不会显式中止。你应该通读这个函数来理解它的作用,以及你的锁管理器是如何在中止过程中使用的。Isolation Level
先学习一下 isolation level 隔离级别
- Dirty Reads
一个事务读取了另一个事务还未提交后的修改
- Unrepeatable Reads
第一个事务读取值,第二个事务更新(大小不变),第一个事务再次读取值,发现值变了
- Phantom Reads
第一个事务读取列,第二个事务修改(大小改变),第一个事务再次读取列,发现多了或少了某些列
参考了 database - What is the difference between Non-Repeatable Read and Phantom Read? - Stack Overflow
然后 isolation level 的参考如下
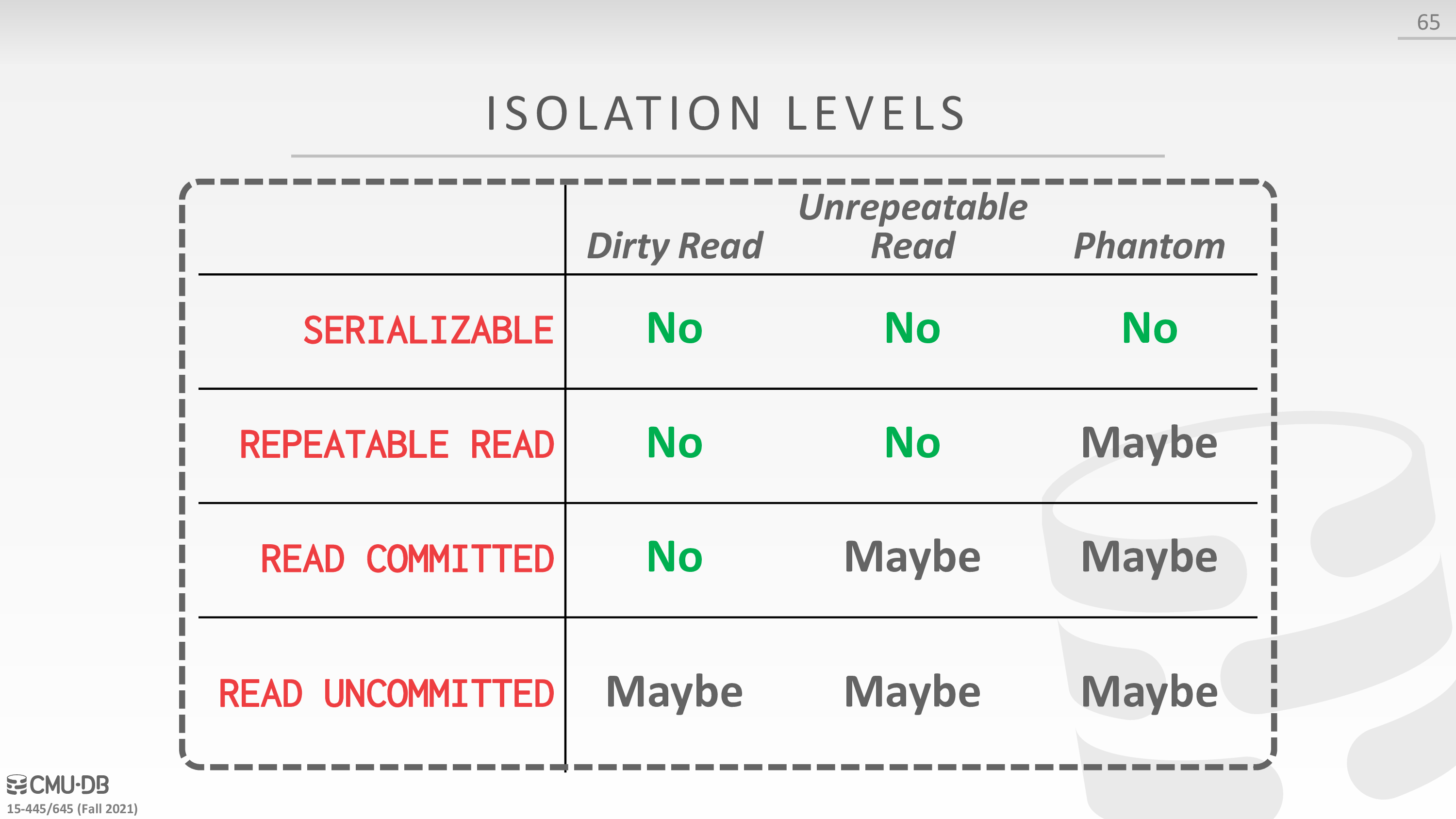
- SERIALIZABLE: Obtain all locks first; plus index locks, plus strict 2PL.
- REPEATABLE READS: Same as above, but no index locks.
- READ COMMITTED: Same as above, but S locks are released immediately.
- READ UNCOMMITTED: Same as above, but allows dirty reads (no S locks).
Test
相应的测试用例
-
lock_manager_test.cpp
- BasicTest - REPEATABLE READS
- TwoPLTest - Incorrect
- UpgradeLockTest
- 还有测试是 Deadlock Detection 的,可以不管
-
grading_lock_manager_test.cpp
- BasicTest - REPEATABLE READS / READ COMMITTED / READ UNCOMMITTED
- TwoPLTest - Correct / Incorrect
Note
1、注意对不变量的检测,方便在 Task #3 中多线程执行事务进行调试
2、通过 emplace 向 lock_table 插入新的 request_queue 时,需要使用如下的形式
lock_table_.emplace(std::piecewise_construct, std::make_tuple(rid), std::make_tuple());若使用
lock_table_.emplace(rid, LockRequestQueue())首先会调用 LockRequestQueue 类的默认构造函数,然后会调用 LockRequestQueue 类的拷贝构造函数,但是 LockRequestQueue 类中有 std::mutex 和 std::condition_variable 两个不可拷贝的成员变量,因此它的拷贝构造函数是被删除的,所以行不通
参考了 c++ - How to emplace object with no-argument constructor into std::map? - Stack Overflow
3、对三个 lock 方法语义的分析
- LockShared
txn 想要获取 rid 的 s-lock
检测完 corner case 之后,添加 request 到相应的 request_queue
因为要使用 Wound-Wait 策略进行死锁预防
所以在 wait 之前要记录等待该 rid 的 x-lock 的 younger txn,并 set abort
注意 set abort 需要 notify_all,否则就可能死循环了
然后在 wait 中寻找 hold 该 rid 的 x-lock 的 txn,若该 txn 更老,则等待
否则顺利出了 wait,并 set abort 它
最后更新 txn 的信息即可
- LockExclusive
txn 想要获取 rid 的 x-lock
检测完 corner case 之后,添加 request 到相应的 request_queue
类似上面的分析,在 wait 之前记录等待该 rid 的 lock 的 younger txn**(s)**
注意这里可能是 x-lock 也可能是 s-lock
然后在 wait 中寻找 hold 该 rid 的 lock 的 txn(s)
multiple txns hold s-lock or one txn hold x-lock
后面就类似上面的处理了
- LockUpgrade
首先 txn 拥有 rid 的 s-lock,想要升级为 x-lock
因为 request_queue 已经有记录了,所以不必再添加
但需要根据 request_queue 的 upgrading 来判断是否有其他 txn 也等待升级
类似上面的分析,在 wait 之前记录等待该 rid 的 lock 的 younger txn**(s)**
同样,这里可能是 x-lock 也可能是 s-lock
但是在 wait 中只可能是 multiple txns hold s-lock
否则若存在 one txn hold x-lock,则自己不可能拥有 s-lock
后面就类似上面的处理了
4、Isolation Level 的体现
通过 Lock Manager 和 Executor 来共同实现 Isolation Level 的语义
这里主要分析一下 Lock Manager
主体部分的逻辑是按照 2PL 和 REPEATABLE READS 来写的
对于 READ COMMITTED,体现在 Unlock 中若释放 s-lock 不必调整事务状态为 SHRINKING
对于 READ UNCOMMITTED,体现不允许获取 s-lock,否则在 LockShared 中会抛出异常
5、其他的一些观察
注意 Transaction Manager 的 Commit 和 Abort 在最后会调用 ReleaseLocks,其中会使用 Lock Manager 对 set 中的 rid 解锁
注意到 生产者 - 消费者模式,unlock 是生产者,而 lock 既是生产者也是消费者
std::unique_lock<std::mutex> lck(latch);search->second.cv_.wait(lck, [&] { ... });对于 wait 和 unique_lock 的机理,并不完全了解
似乎 wait 时 lck 就已经被释放了,从而让其他事务可以进来打破僵局
总之 lck 是保护 lock_table 的
还有 Transaction 类中一些成员变量使用不到,如 page_set 和 deleted_page_set
Task #2 - Deadlock Prevention
如果您的锁管理器被告知使用预防,您的锁管理器应该使用 WOUND-WAIT 算法来决定要中止哪些事务。
获取锁时,您将需要查看相应的 LockRequestQueue 以查看它将等待哪些事务。提示
仔细阅读幻灯片,了解如何实施 Wound-Wait。
中止事务时,请确保使用 SetState 正确设置其状态
如果事务正在升级(等待获取 X 锁),它仍然可以中止。您必须正确处理此问题。
当一个事务正在等待另一个事务时,等待图绘制边。请记住,如果多个事务持有共享锁,则单个事务可能正在等待多个事务。
当事务中止时,确保将事务的状态设置为 ABORTED 并在锁管理器中抛出异常。事务管理器将处理显式中止和回滚更改。
由于伤口等待预防策略,等待锁定的事务可能会被另一个线程中止。您必须有一种方法来通知等待的事务它们已被中止。Wound-Wait
回顾一下 Wound-Wait
优先级高 = ID 小
依据是 TransactionManager 类的 Begin 成员函数,使用 next_txn_id++ 对每个事务进行编号
所以创建更早(更老)的事务一定有更小的 ID
If requesting txn has higher priority than holding txn, then holding txn aborts and releases lock. Otherwise requesting txn waits.
Test
相应的测试用例
- lock_manager_test.cpp
- WoundWaitBasicTest
- grading_lock_manager_prevention_test.cpp
- WoundWaitBasicTest - 与上面的测试并不一样
- WoundWaitDeadlockTest
- WoundUpgradeTest
- WoundWaitFairnessTest
Note
分析一下 grading 中 WoundWaitBasicTest 的语境
txn 最老,其次是 kill_txn,wait_txn 最年轻
txn 获取了 0 的 x-lock 和 1 的 s-lock
然后 wait_txn 获取了 1 的 s-lock,在试图获取 0 的 x-lock 时陷入 wait
然后 kill_txn 获取了 1 的 s-lock,并试图获取 0 的 s-lock
关键的地方来了,此时 txn 并未 commit,kill_txn 在试图获取 0 的 s-lock,发现年轻的 wait_txn 也试图获取 0 的 x-lock,于是 kill_txn 杀了 wait_txn,kill_txn 陷入 wait
然后主程序等待 kill_txn join,kill_txn abort 掉
然后此时 txn commit 了,kill_txn 获得了 0 的 s-lock
具体的语义分析见 Task #1 的 Note
Task #3 - Concurrent Query Execution
在并发查询执行期间,执行器需要适当地锁定/解锁元组,以达到相应事务中指定的隔离级别。为了简化此任务,您可以忽略并发索引执行而只关注表元组。
您将需要更新项目 3 中实现的某些执行程序(顺序扫描、插入、更新、删除、嵌套循环连接和聚合)的 Next() 方法。请注意,当锁定/解锁失败时,事务将中止。虽然没有并发索引执行的要求,但我们仍然需要在事务中止时适当地撤消之前对表元组和索引的所有写入操作。为此,您需要维护事务中的写入集,这是事务管理器的 Abort() 方法所要求的。
你不应该假设一个事务只包含一个查询。具体来说,这意味着一个元组可能在一个事务中被不同的查询访问不止一次。想想你应该如何在不同的隔离级别下处理这个问题。只需要修改下面的 executors
src/execution/seq_scan_executor.cppsrc/execution/insert_executor.cppsrc/execution/update_executor.cppsrc/execution/delete_executor.cpp
还需要修改 execution_engine.h 捕获异常并 abort
Test
- transaction_test.cpp
- SimpleInsertRollbackTest
- DirtyReadsTest
- grading_transaction_test.cpp
- DirtyReadsTest
- UnrepeatableReadsTest
- RepeatableReadsTest
- IntegratedTest
- grading_rollback_test.cpp
- SimpleInsertRollbackTest
- SimpleDeleteRollbackTest
- SimpleUpdateRollbackTest
Note
对 Executor 的修改分为三个部分
- SeqScanExecutor
进行 LockShared
注意到一个事务可能包含多个查询,所以需要对事务已经获得 lock 的情形进行判断
正是之前对不变量的检测,才发现了这个问题
具体而言,在 Evaluate 前,REPEATABLE_READ 下可能事务已经获得 s-lock 或 x-lock,而其余的 Isolation Level 下不能有 s-lock
因为在 Evaluate 后 READ COMMITTED 需要释放 s-lock
而 READ UNCOMMITTED 就没有 s-lock
在 Evaluate 后,REPEATABLE_READ 下不能释放 s-lock,从而实现了 Rigorous 2PL
- InsertExecutor
在 InsertTuple 后才 LockExclusive
注意 TableHeap 中 InsertTuple 的签名为
/** * Insert a tuple into the table. If the tuple is too large (>= page_size), return false. * @param tuple tuple to insert * @param[out] rid the rid of the inserted tuple * @param txn the transaction performing the insert * @return true iff the insert is successful */ bool InsertTuple(const Tuple &tuple, RID *rid, Transaction *txn);所以实际上是对返回的 inserted tuple 的 rid 加锁
TableHeap 中 InsertTuple 会调用 TablePage 中的 InsertTuple,以此来确定 rid
另外 TableHeap 在最后更新了事务的 write set
// Update the transaction's write set. txn->GetWriteSet()->emplace_back(*rid, WType::INSERT, Tuple{}, this);所以就不必在 InsertExecutor 中更新了
只需要更新索引
IndexWriteRecord record(ret_rid, table_info_->oid_, WType::INSERT, target_tuple, index_info->index_oid_, exec_ctx_->GetCatalog());exec_ctx_->GetTransaction()->AppendTableWriteRecord(record);实际上应该在 ExtendibleHashTableIndex 类的 InsertEntry 中添加更新索引的代码,但是修改无法提交给 OJ
回顾 ExtendibleHashTableIndex 类继承了 Index 类
对于索引的问题,UpdateExecutor 和 DeleteExecutor 中的处理类似
- UpdateExecutor 和 DeleteExecutor
对 child_executor 返回的 rid 加锁,需要在 UpdateTuple 或 MarkDelete 之前完成
同样需要对事务已经获得 lock 的情形进行判断
REPEATABLE_READ 下一定有 s-lock,可能需要 LockUpgrade
其余的级别下一定没有 s-lock,可能需要 LockExclusive
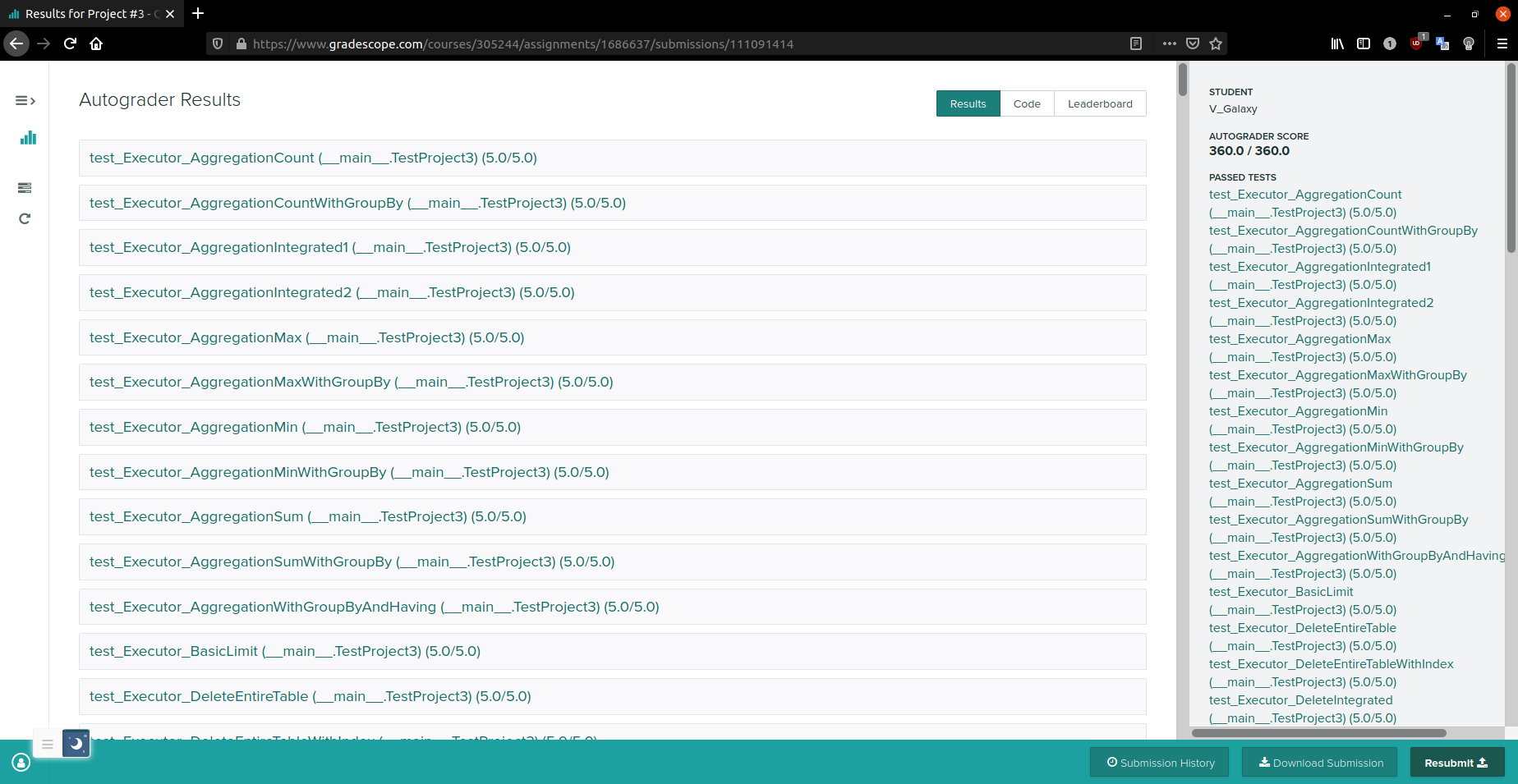
Submission
使用 gdb 调试
$ cmake -DCMAKE_BUILD_TYPE=DEBUG ..调试多线程
(gdb) info threads(gdb) break location thread id(gdb) thread apply id command提交的文件
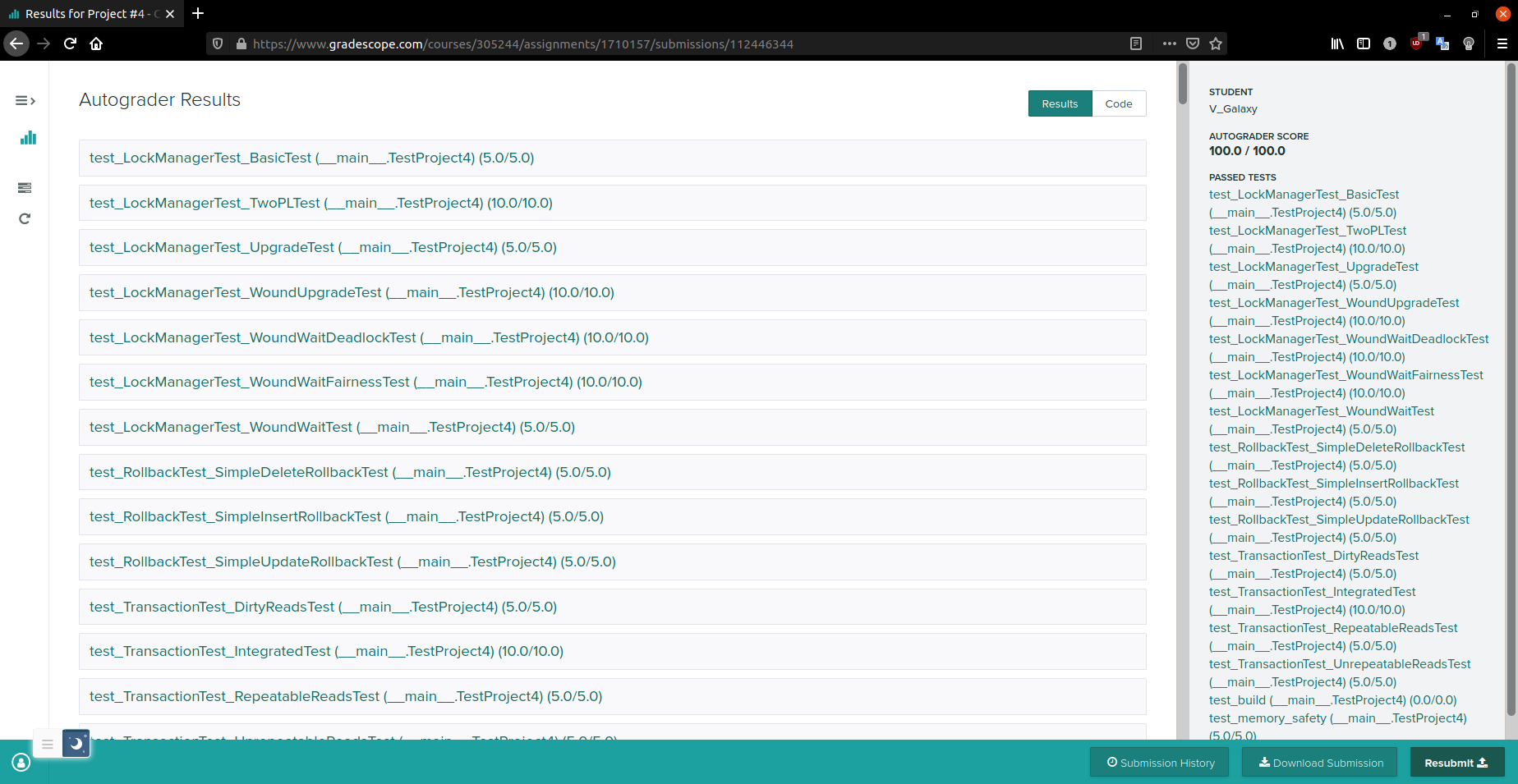
$ zip project4-submission.zip \src/include/buffer/lru_replacer.h \src/buffer/lru_replacer.cpp \src/include/buffer/buffer_pool_manager_instance.h \src/buffer/buffer_pool_manager_instance.cpp \src/include/storage/page/hash_table_directory_page.h \src/storage/page/hash_table_directory_page.cpp \src/include/storage/page/hash_table_bucket_page.h \src/storage/page/hash_table_bucket_page.cpp \src/include/container/hash/extendible_hash_table.h \src/container/hash/extendible_hash_table.cpp \src/include/execution/execution_engine.h \src/include/execution/executors/seq_scan_executor.h \src/include/execution/executors/insert_executor.h \src/include/execution/executors/update_executor.h \src/include/execution/executors/delete_executor.h \src/include/execution/executors/nested_loop_join_executor.h \src/include/execution/executors/hash_join_executor.h \src/include/execution/executors/aggregation_executor.h \src/include/execution/executors/limit_executor.h \src/include/execution/executors/distinct_executor.h \src/execution/seq_scan_executor.cpp \src/execution/insert_executor.cpp \src/execution/update_executor.cpp \src/execution/delete_executor.cpp \src/execution/nested_loop_join_executor.cpp \src/execution/hash_join_executor.cpp \src/execution/aggregation_executor.cpp \src/execution/limit_executor.cpp \src/execution/distinct_executor.cpp \src/include/concurrency/lock_manager.h \src/concurrency/lock_manager.cppProject Summary
面向 OJ 编程
测试驱动开发
1 + 3 + 3 + 5 + 3
project overview
project 0
project 1
project 2
project 3
project 4