TOC
Open TOC
- CMU 15-445 NOTE
- Info
- Lecture #01 - Course Introduction and the Relational Model
- Lecture #02 - Advanced SQL
- Homework #1 - SQL
- Lecture #03 - Database Storage I
- Lecture #04 - Database Storage II
- Lecture #05 - Buffer Pools
- Lecture #06 - Hash Tables
- Lecture #07 - Trees Indexes I
- Lecture #08 - Trees Indexes II
- Lecture #09 - Index Concurrency Control
- Lecture #10 - Sorting + Aggregations
- Lecture #11 - Joins Algorithms
- Lecture #12 - Query Execution I
- Lecture #13 - Query Execution II
- Lecture #14 - Query Planning & Optimization I
- Lecture #15 - Query Planning & Optimization II
- Lecture #16 - Concurrency Control Theory
- Lecture #17 - Two**-Phase Locking Concurrency Control**
- NOTE CONTINUED
CMU 15-445 NOTE
Info
https://zhuanlan.zhihu.com/p/405828728
https://15445.courses.cs.cmu.edu/fall2019/schedule.html
使用 2019 fall 的 schedule
使用如下命令
wget -r -l 1 https://15445.courses.cs.cmu.edu/fall2019/notes快速下载所有课件
Lecture #01 - Course Introduction and the Relational Model
Overview
- Relational Databases
Lecture #01~02
- Storage
Lecture #03~09
- Execution
Lecture #10~15
- Concurrency Control
Lecture #16~19
- Recovery
Lecture #20~21
- Distributed Databases
Lecture #22~24
Layer
- Query Planning
Lecture #14~15
- Operator Execution
Lecture #10~13
- Access Methods
Lecture #06~09
- Buffer Pool Manager
Lecture #05
- Disk Manager
Lecture #03~04
Note
从 CSV 引入数据库的概念,介绍了与数据库相关的问题,如数据完整性、持久性和数据库的实现
介绍了数据库系统 DBMS,这是一个高层的概念,由此不用再考虑一些底层的问题
一个类比
- 数据库系统和数据库
- 编译器生成汇编代码和手写汇编代码
核心精神还是抽象和解耦
然后介绍了数据模型中的关系模型,有一些基本的概念
- relation → 表
- tuple → 记录、元组、一行
- attribute → 属性、字段、一列
- domain → 域、attribute 可取值的集合,实际上区分并不明显
- schema → 表的组成与表之间的关联
数据模型,如 ML 中常使用数组和矩阵表示数据
接着介绍了 Data Manipulation Languages
- Procedural: Relational Algebra
- Non-Procedural (Declarative): Relational Calculus
HOW 和 WHAT 的区别
最后介绍了关系代数中的几种运算,注意这在 HOW 的范畴内
Lecture #02 - Advanced SQL
SQL 光速入门
注意区分
- 关系代数建立在 sets (unordered, no duplicates) 之上
- SQL 建立在 bags (unordered, allows duplicates) 之上
另外 SQL 有很多的版本和方言,并且仍在不断更新迭代
要追求用一行请求达成目的
Homework #1 - SQL
Preparation
- answer
$ mkdir placeholder$ cd placeholder$ touch q1_sample.sql\ q2_string_function.sql\ q3_northamerican.sql\ q4_delaypercent.sql\ q5_aggregates.sql\ q6_discontinued.sql\ q7_order_lags.sql\ q8_total_cost_quartiles.sql\ q9_youngblood.sql\ q10_christmas.sql$ cd ..$ zip -j submission.zip placeholder/*.sql- sqlite3
sudo apt install sqlite3- database dump
source:
https://github.com/jpwhite3/northwind-SQLite3
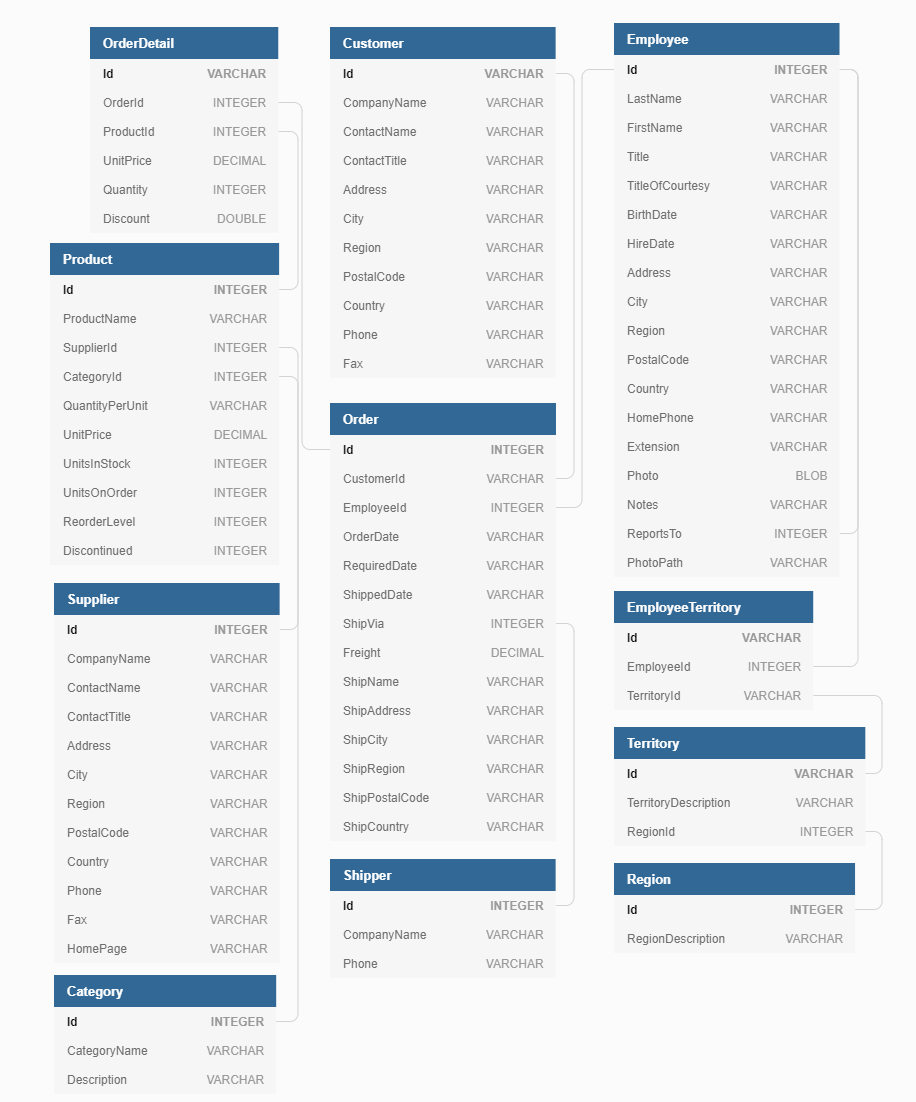
schema illustration:
Queries
Q1
SELECT CategoryName FROM Category ORDER BY CategoryName;白送
Q2
Get all unique ShipNames from the Order table that contain a hyphen '-'.
In addition, get all the characters preceding the (first) hyphen.
Return ship names alphabetically.
Your first row should look like Bottom-Dollar Markets|Bottom.
select distinct ShipName as name, substr(ShipName, 0, instr(ShipName, '-'))from 'Order'where name like '%-%'order by ShipName;内置函数 substr 和 instr
RTFM → https://sqlite.org/index.html
Q3
Indicate if an order’s ShipCountry is in North America.
For our purposes, this is 'USA', 'Mexico', 'Canada'.
You should print the Order Id, ShipCountry, and another column that is either 'NorthAmerica' or 'OtherPlace' depending on the Ship Country.
Order by the primary key (Id) ascending and return 20 rows starting from Order Id 15445.
Your output should look like 15445|France|OtherPlace or 15454|Canada|NorthAmerica.
select Id, ShipCountry, printf("NorthAmerica")from 'Order'where Id >= 15445 and ShipCountry in ('USA', 'Mexico', 'Canada')unionselect Id, ShipCountry, printf("OtherPlace")from 'Order'where Id >= 15445 and ShipCountry not in ('USA', 'Mexico', 'Canada')order by Idlimit 20;简单的 union
Q4
For each Shipper, find the percentage of orders which are late.
An order is considered late if ShippedDate > RequiredDate.
Print the following format, order by descending precentage, rounded to the nearest hundredths, like United Package|23.44.
with delay (name, res) as ( select CompanyName, count(*) from 'Order' as o, Shipper as s where o.ShipVia == s.Id and o.ShippedDate > o.RequiredDate group by CompanyName)select CompanyName, printf("%.2f", res * 100.0 / count(*))from 'Order' as o, Shipper as s, delay as dwhere o.ShipVia == s.Id and s.CompanyName == d.namegroup by CompanyNameorder by 2 desc;人快麻了……
因为需要从两个角度进行计数
所以使用 Common Table Expressions 引入临时表 delay
Q5
Compute some statistics about categories of products.
Get the number of products, average unit price (rounded to 2 decimal places), minimum unit price, maximum unit price, and total units on order for categories containing greater than 10 products.
Order by Category Id.
Your output should look like Beverages|12|37.98|4.5|263.5|60.
select c.CategoryName, count(*), round(avg(p.UnitPrice), 2), round(min(p.UnitPrice), 2), round(max(p.UnitPrice), 2), sum(p.UnitsOnOrder)from Category as c, Product as pwhere p.CategoryId == c.Idgroup by c.Idhaving count(*) > 10order by c.Id;对加粗的部分进行阅读理解
不涉及 Order 和 OrderDetail 的部分,单纯就是 sum(UnitsOnOrder)
虽然无法理解这个字段的意义
主要考察 having 语法
还有 round 和 printf 的区别
- round(4.5, 2) = 4.5
- printf(“%.2f”, 4.5) = 4.50
Q6
For each of the 8 discontinued products in the database, which customer made the first ever order for the product? Output the customer’s CompanyName and ContactName.
Print the following format, order by ProductName alphabetically: Alice Mutton|Consolidated Holdings|Elizabeth Brown.
with res (product_name, order_date, company_name, contact_name) as ( select distinct p.ProductName, min(o.OrderDate), c.CompanyName, c.ContactName from Product as p, OrderDetail as od, 'Order' as o, Customer as c where p.Discontinued == 1 and od.OrderId == o.Id and od.ProductId == p.Id and o.CustomerId == c.Id group by p.ProductName)select product_name, company_name, contact_namefrom resorder by product_name;这里利用了在 Aggregations 时,对应的信息能够正确的提取出来
如对于 min(OrderDate),CompanyName 和 ContactName 就是对应顾客的信息
由于不需要 date 信息,所以引入临时表进行字段的提取
Q7
For the first 10 orders by CutomerId BLONP: get the Order’s Id, OrderDate, previous OrderDate, and difference between the previous and current.
Return results ordered by OrderDate (ascending).
The “previous” OrderDate for the first order should default to itself (lag time = 0).
Use the julianday() function for date arithmetic (example).
Use lag(expr, offset, default) for grabbing previous dates.
Please round the lag time to the nearest hundredth, formatted like 17361|2012-09-19 12:13:21|2012-09-18 22:37:15|0.57.
For more details on window functions, see here.
with curr (oid, cid, curr_date) as( select o.Id, c.Id, o.OrderDate from Customer as c, 'Order' as o where o.CustomerId == c.Id and c.Id == 'BLONP' order by o.OrderDate limit 10),layer (oid, cid, curr_date, min_date) as( select curr.oid, curr.cid, curr.curr_date, min(o.OrderDate) from 'Order' as o, curr where curr.cid == o.CustomerId group by curr.curr_date)select layer.oid, layer.curr_date, layer.min_date, round(julianday(layer.curr_date) - julianday(layer.min_date), 2)from 'Order' as o, layerwhere layer.cid == o.CustomerId and layer.curr_date == layer.min_dategroup by layer.curr_dateunionselect layer.oid, layer.curr_date, max(o.OrderDate), round(julianday(layer.curr_date) - julianday(max(o.OrderDate)), 2)from 'Order' as o, layerwhere layer.cid == o.CustomerId and layer.curr_date != layer.min_date and o.OrderDate < layer.curr_dategroup by layer.curr_dateorder by layer.curr_date;双重 Common Table Expressions
因为 curr_date 可能是顾客的第一笔订单,所以添加一个临时表得到 min_date
最后分类讨论再合并
Q8
For each Customer, get the CompanyName, CustomerId, and “total expenditures”.
Output the bottom quartile of Customers, as measured by total expenditures.
Calculate expenditure using UnitPrice and Quantity (ignore Discount).
Compute the quartiles for each company’s total expenditures using NTILE.
The bottom quartile is the 1st quartile, order them by increasing expenditure.
Make sure your output is formatted as follows (round expenditure to nearest hundredths): Bon app|BONAP|4485708.49.
There are orders for CustomerIds that don’t appear in the Customer table. You should still consider these “Customers” and output them.
If the CompanyName is missing, override the NULL to 'MISSING_NAME' using IFNULL.
with cost (company_name, cid, expenditure) as( select IFNULL(c.CompanyName, 'MISSING_NAME'), o.CustomerId, round(sum(od.UnitPrice * od.Quantity), 2) as expenditure from 'Order' as o inner join OrderDetail od on od.OrderId = o.Id left join Customer c on c.Id = o.CustomerId group by o.CustomerId order by expenditure),layer as(select *, ntile(4) over () as tagfrom cost)select company_name, cid, expenditurefrom layerwhere tag = 1;这题不太会……
有如下知识点:
- Window Functions → ntile
- join
- 之前都是 from a, b 然后在 where 里面给出约束条件
- 这等价于在 from 里面使用 inner join,然后在 on 里面给出约束条件
- 然而表 Order 里面存在一些 CustomerId,这些 CustomerId 在 Customer 表中没有对应
- 所以我们需要 left join,Order 表在左边,代表即使右边的表 Customer 中没有对应约束的记录,也需要返回
- 同理还有 right join
- 还有一个 natural join,返回两个表中所有相同的字段,值也相同的记录
==可以写成=
Q9
Find the youngest employee serving each Region.
If a Region is not served by an employee, ignore it.
Print the Region Description, First Name, Last Name, and Birth Date. Order by Region Id.
Your first row should look like Eastern|Steven|Buchanan|1987-03-04.
select r.RegionDescription, e.FirstName, e.LastName, max(e.BirthDate)from Region as r, Territory as t, EmployeeTerritory as et, Employee as ewhere r.Id = t.RegionId and t.Id = et.TerritoryId and e.Id = et.EmployeeIdgroup by r.Id;简化后的 Q6
Q10
Concatenate the ProductNames ordered by the Company 'Queen Cozinha' on 2014-12-25.
Order the products by Id (ascending).
Print a single string containing all the dup names separated by commas like Mishi Kobe Niku, NuNuCa Nuß-Nougat-Creme....
You might find Recursive CTEs useful.
with info (product_name, order_date) as( select p.ProductName, o.OrderDate from 'Order' as o, Customer as c, OrderDetail as od, Product as p where o.CustomerId = c.Id and od.OrderId = o.id and od.ProductId = p.Id and c.CompanyName = 'Queen Cozinha' and o.OrderDate like '2014-12-25%' order by p.Id)select group_concat(info.product_name, ', ')from info;内置函数 group_concat 默秒全
不过参考答案也值得一看
with p as ( select Product.Id, Product.ProductName as name from Product inner join OrderDetail on Product.id = OrderDetail.ProductId inner join 'Order' on 'Order'.Id = OrderDetail.OrderId inner join Customer on CustomerId = Customer.Id where DATE(OrderDate) = '2014-12-25' and CompanyName = 'Queen Cozinha' group by Product.id),c as ( select row_number() over (order by p.id asc) as seqnum, p.name as name from p),flattened as ( select seqnum, name as name from c where seqnum = 1 union all select c.seqnum, f.name || ', ' || c.name from c join flattened f on c.seqnum = f.seqnum + 1)select name from flattenedorder by seqnum desc limit 1;引入 row_number 便于递归计数
f 为 flattened 别名?
Summary
有一种 FP 的感觉
gradescope 似乎没有更新 Homework 的评测
所以写了一个程序验证正确性
#include <assert.h>#include <stdio.h>#include <string.h>#include <unistd.h>
#define BUFSIZE 1024
const char *prefix_sol = "sqlite3 northwind-cmudb2021.db < sol/";const char *prefix_ref = "sqlite3 northwind-cmudb2021.db < ref/";
const char *filenames[] = { "q1_sample.sql", "q2_string_function.sql", "q3_northamerican.sql", "q4_delaypercent.sql", "q5_aggregates.sql", "q6_discontinued.sql", "q7_order_lags.sql", "q8_total_cost_quartiles.sql", "q9_youngblood.sql", "q10_christmas.sql"};
FILE *fp;char buf[BUFSIZE];
void test(char *cmd, char *res) { fp = popen(cmd, "r"); assert(fp); while (fgets(buf, BUFSIZE, fp) != NULL) strcat(res, buf); pclose(fp);}
int main() { char cmd[BUFSIZE]; char sol_res[BUFSIZE], ref_res[BUFSIZE]; for (int i = 0; i < 10; ++i) { memset(cmd, 0, sizeof(cmd)); memset(sol_res, 0, sizeof(sol_res)); strcat(cmd, prefix_sol); strcat(cmd, filenames[i]); test(cmd, sol_res);
memset(cmd, 0, sizeof(cmd)); memset(ref_res, 0, sizeof(ref_res)); strcat(cmd, prefix_sol); strcat(cmd, filenames[i]); test(cmd, ref_res);
if (strcmp(sol_res, ref_res)) printf("Error at %s\n", filenames[i]); else printf("OK at %s\n", filenames[i]); }}项目结构如下
.├── Makefile├── northwind-cmudb2021.db├── ref│ ├── q1_sample.sql│ ├── q2_string_function.sql│ ├── q3_northamerican.sql│ ├── q4_delaypercent.sql│ ├── q5_aggregates.sql│ ├── q6_discontinued.sql│ ├── q7_order_lags.sql│ ├── q8_total_cost_quartiles.sql│ ├── q9_youngblood.sql│ └── q10_christmas.sql├── sol│ ├── q1_sample.sql│ ├── q2_string_function.sql│ ├── q3_northamerican.sql│ ├── q4_delaypercent.sql│ ├── q5_aggregates.sql│ ├── q6_discontinued.sql│ ├── q7_order_lags.sql│ ├── q8_total_cost_quartiles.sql│ ├── q9_youngblood.sql│ └── q10_christmas.sql└── verify.cLecture #03 - Database Storage I
进入 Storage 的部分
两个议题:
-
How the DBMS represents the database in files on disk → Lecture #03 and Lecture #04
-
How the DBMS manages its memory and move data back-and-forth from disk → Lecture #05
Intro
DBMS 使用非易失性存储器,这里以磁盘 disk 为代表
磁盘中有 datebase file,内存中有 buffer pool
不使用 OS 进行页的交换,因为 OS 对 DB 里面的数据一无所知
File Storage
我们使用 storage manager 管理 datebase file,它将文件组织为 pages
Heap File Organization 是一种无序的组织形式,tuple 在 page 中是无序的
比较好的实现为 Page Directory,也就是用一个单独的 page 管理其他 pages
Page Layout
一个 page 里面有 header 存储一些元数据
剩下的部分存储记录 tuple
tuple 可以是定长也可以是变长
需要一个 slot array 存储指向各个 tuple 的指针
也可以使用 log-structured 方式
此时 page 里面存放的不是 tuple,而是一些 log records
这种方式更适合分布式数据库
Tuple Layout
同样有一个 header
剩下的部分存储 attribute data
不必存储 schema
The DBMS’s catalogs contain the schema information about tables that the system uses to figure out the tuple’s layout.
可能会对相关联的表进行 denormalize,即在存储层面上预先 join 起来
对每个 tuple,DBMS 可能会使用 page_id + offset/slot 的方式引用
Lecture #04 - Database Storage II
Data Representation
- 整型
- 浮点型和定点小数,由于浮点数运算的误差,常常使用定点小数表示法,也就是字符串加上一些元数据
- 字符型,有 header 记录长度
- 时间
另外还要考虑两个问题
- large values
使用 overflow storage pages 存储那些超出页大小的记录
比如用一个指针指向一个字符串
字符串的实际内容就存放在 overflow storage pages 中
- external value storage
如果数据实在太大,可以将其存放在 external file 中
也就是 blob 类型
System Catalogs
一些数据库的元数据
我们以 sqlite 为例
可以查看所有的表
sqlite> .tablesCategory EmployeeTerritory RegionCustomer Order ShipperCustomerCustomerDemo OrderDetail SupplierCustomerDemographic Product TerritoryEmployee ProductDetails_V也可以查看表的 schema
sqlite> .schema CategoryCREATE TABLE IF NOT EXISTS "Category"( "Id" INTEGER PRIMARY KEY, "CategoryName" VARCHAR(8000) NULL, "Description" VARCHAR(8000) NULL);Storage Models
注意到两种不同类型的事务 workload
我们需要使用不同的 storage models
- OLTP
On-line Transaction Processing
只是读取或更新一小块数据,通常在一个 tuple 或 page 内
比如限制了查询的 ID
这种事务通常使用 n-ary storage model (NSM)
也就是我们上面一直在介绍的内容
连续的存储记录的所有字段,也就是以行为单位
- OLAP
On-line Analytical Processing
读取较大的一块数据,通常横跨几个 page
比如 join 几个表,查询满足某种限制的所有信息
这种事务通常使用 decomposition storage model (DSM)
以列为单位,在一个表中只存放一种字段的域
通常是定长的,通过偏移量对应字段所属的记录
- HTAP
对于混合型的事务,通常结合 OLTP 和 OLAP
即 Hybrid Transaction
经由 Extract Transform Load
再进行 Analytical Processing
参考图如下
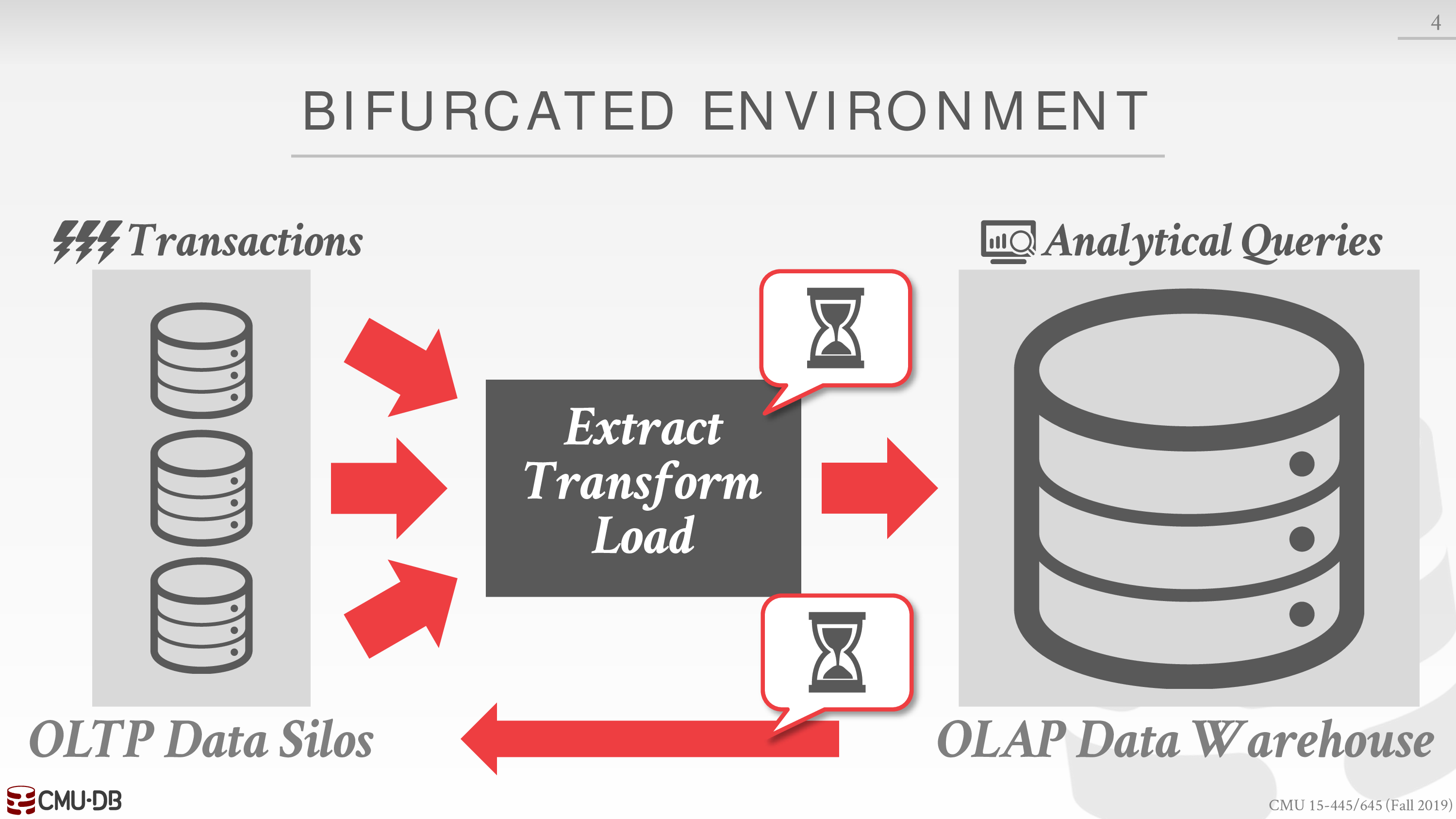
虽然不太看得懂
converter:
https://jdhao.github.io/2019/11/20/convert_pdf_to_image_imagemagick/
注意下标从 0 开始
Lecture #05 - Buffer Pools
Buffer Pool Manager
buffer pool 中存放 page 的位置称为 frame
buffer pool 的元数据存放在 page table 中
如记录加载到 buffer pool 中的 page 编号,各个 page 的 dirty flag 和 pin / reference counter
注意区分 page table 和 page directory
有一些优化 buffer pool 的方案
- Multiple Buffer Pools
多个 buffer pool,便于采用不同 local policy,也避免 latch 之间的竞争
需要区分 latch 和 lock,目前不太懂
Locks:⚝ Protects the database's logical contents from other transactions.⚝ Held for transaction duration.⚝ Need to be able to rollback changes.
Latches:⚝ Protects the critical sections of the DBMS's internal data structure from other threads.⚝ Held for operation duration.⚝ Do not need to be able to rollback changes.- Pre-Fetching
根据顺序查询或索引查询,预先准备好 page 到 buffer pool 中
例子见课件
- Scan Sharing
不同于缓存
当多个查询请求到来时,试图最大化 buffer pool 中 page 的利用率
即让多个查询同时利用 buffer pool 中的 page
例子见课件
- Buffer Pool Bypass
不将 page 读取到 buffer pool 中,防止一些临时数据污染 buffer pool
另外需要注意,buffer pool 通过 OS 的 API 从 disk 中获得数据,但是并不需要 OS 维持其 filesystem 的 cache
所以大多数 DBMS 使用 direct IO,从而避免多重备份和驱逐策略之间的矛盾
Replacement Policies
使用时间戳或链表实现 LRU
或者使用 clock 技术近似实现 LRU
但是 LRU 会出现遭受 sequential flooding 的打击
一次顺序读取,读取了所有页
所以出现了下面一些策略
- LRU-K
- local policy
- priority hints
对于 dirty page 的处理,也需要考虑其 policy
Other Memory Pools
The DBMS needs memory for things other than just tuples and indexes.These other memory pools may not always backed by disk. Depends on implementation.⚝ Sorting + Join Buffers⚝ Query Caches⚝ Maintenance Buffers⚝ Log Buffers⚝ Dictionary CachesLecture #06 - Hash Tables
Layer → Access Methods
Intro
为了造一个数据库,需要在不同的部分使用不同的数据结构
- Internal Meta-data
- Core Data Storage
- Temporary Data Structures
- Table Indexes → B+ Trees
由于 Hash Tables 在范围查询上有明显的劣势,所以 Table Indexes 通常不使用 Hash Tables
Hash Tables
空间复杂度
时间复杂度
对常数很敏感
两个议题
- Hash Function → map
- Hashing Scheme → solve collisions
Hash Functions
使用非加密哈希函数
不要重复造轮子 → http://cyan4973.github.io/xxHash/
Static Hashing Schemes
大小固定,rehash 时需要重建整张表
- Linear Probe Hashing
线性探测
需要考虑删除的策略
- Robin Hood Hashing
通过交换,平均化探测距离
- Cuckoo Hashing
最坏情形为常数
使用多张表和哈希函数
Dynamic Hashing Schemes
动态调整大小,调整时不必重建整张表
- Chained Hashing
分离链接
无视性能的话,实际上都不必调整大小……
-
Extendible Hashing
-
Linear Hashing
这两种策略具体见课件
主要在于理解如何实现 rehash 不必重建整张表
存储指针减少了移动数据的开销
Lecture #07 - Trees Indexes I
听到这一讲才发现有精校中文翻译……
Table Indexes
表索引是表中一些字段的副本
通过某种方式组织起来,从而提供更高效的访问
有序性,范围查询,部分查询(对于组合索引而言)
DBMS 需要保证表的内容和表索引的内容是一致的
通常 DBMS 会根据具体的查询,自动寻找最高效的索引方式
B+Tree Overview
在一些 DBMS 实现中声称的 B-Tree 实际上就是 B+Tree
在具体的实现中,B+Tree 会结合一些 B-Tree 变种的优点,所以没有绝对意义上的概念
典型的,请牢记这张结构图
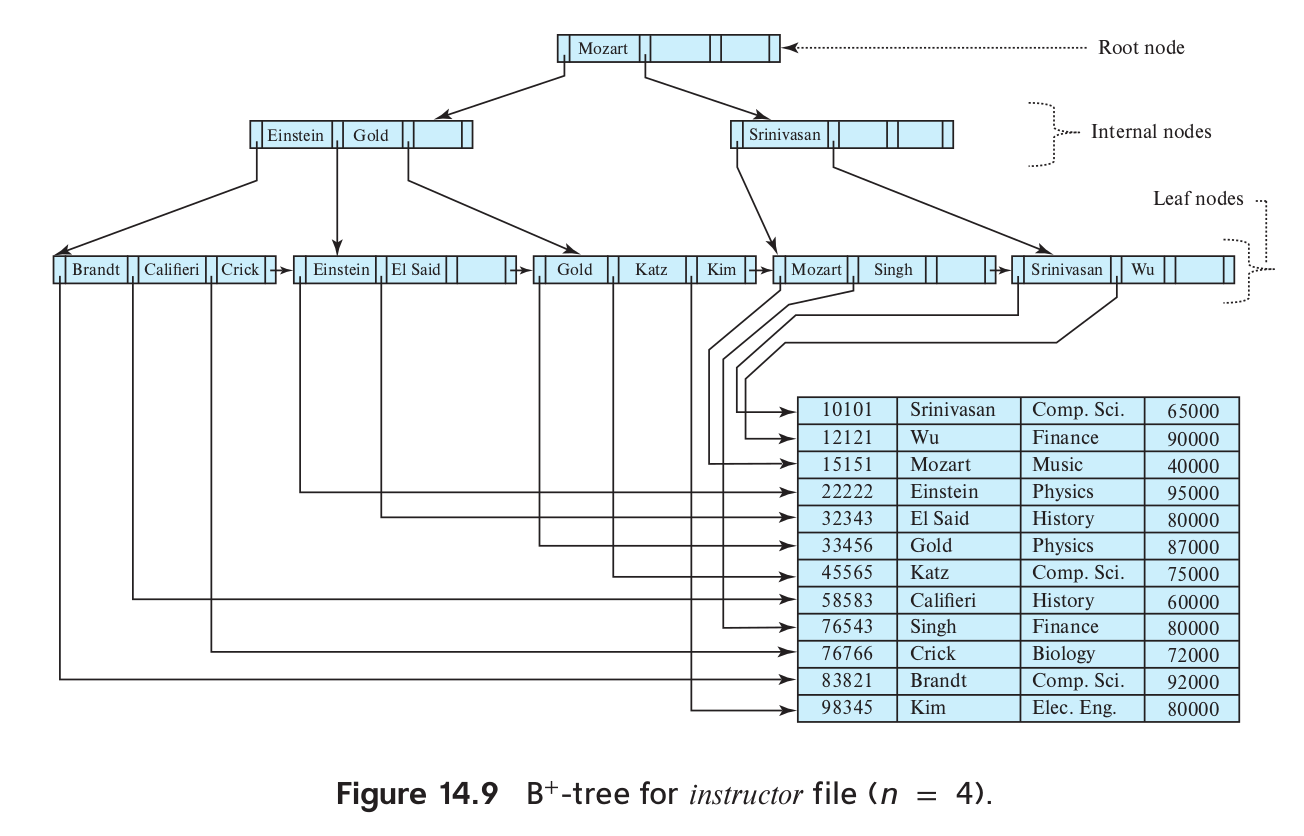
内部节点的 Key 在逻辑上可以不在索引的字段中,这样优化了删除操作
相应的 Value 则是指向下一层的指针
最底层的叶子节点记录了所有索引的字段,对应 Key
而相应的 Value 可以是 Record Ids,也可以是 Tuple Data
Record Ids 通常为
page_id + offset/slot需注意 tuple 的无序性和访存开销
目前我们考虑 Value 为 Record Ids 的情形
通常叶子节点的结构图如下
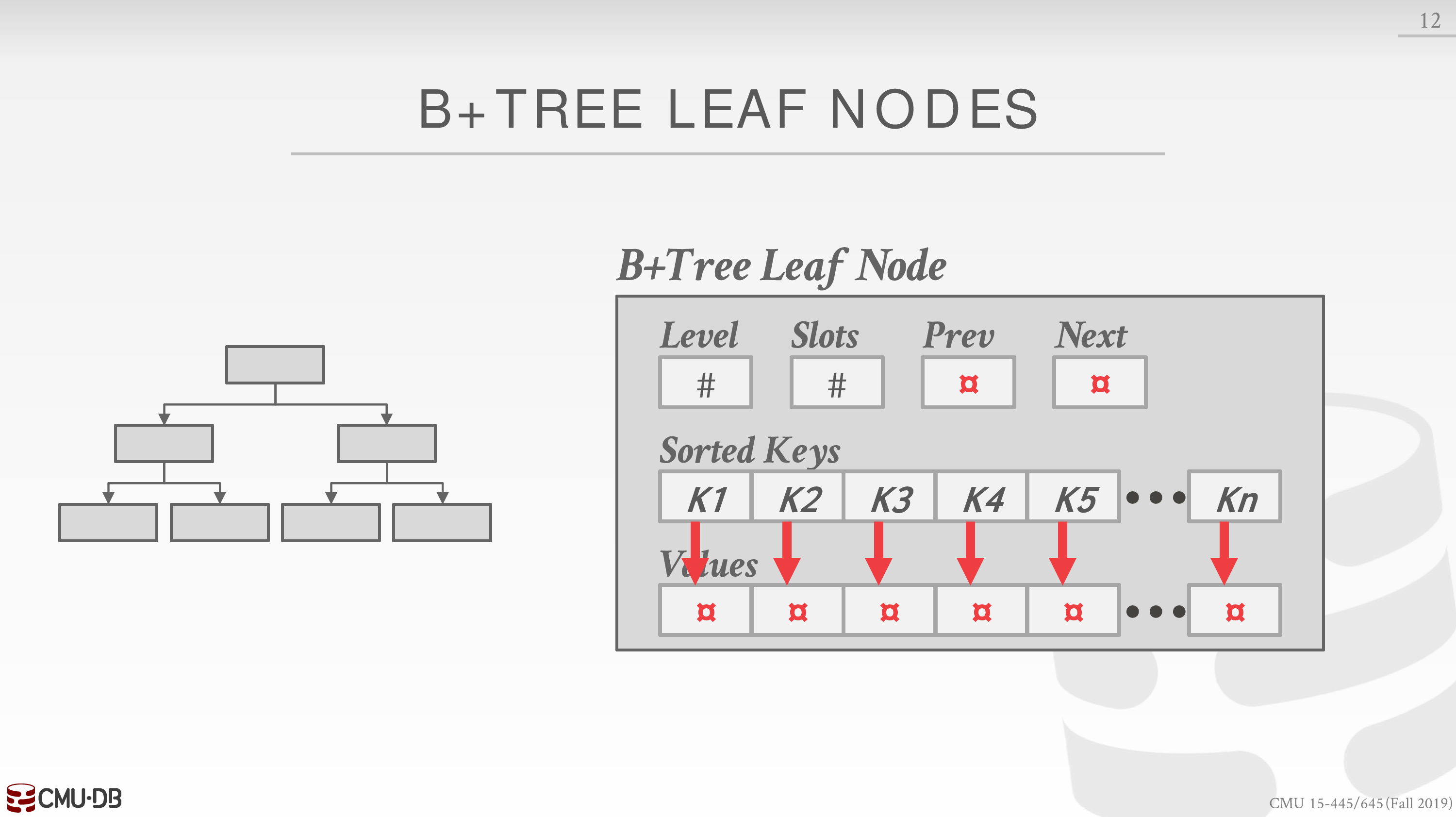
另外,我们假定 Value 是定长的,而 Key 可以是定长也可以是变长,变长的情形下面会讨论
对于插入和删除操作,可以参考 https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
最后,index 通常选定为 primary key,这被称为 clustered index
在未指定 primary key 时,有些 DBMS 会引入隐藏的 row-id 作为 index
对于 clustered index,键值的逻辑顺序决定了表中相应行的物理顺序
https://www.sqlite.org/withoutrowid.html
Design Decisions
参考 https://dl.acm.org/citation.cfm?id=2185842
Node Size
存储设备越慢,顺序访问事务越多,大小越大
Merge Threshold
当半满时,不必立即合并
Variable Length Keys
考虑 Key 变长的情形
可以像 Value 一样存储 Record Ids,也可以使用 padding
不过更好的策略是 Key Map,优化叶子节点的内部结构
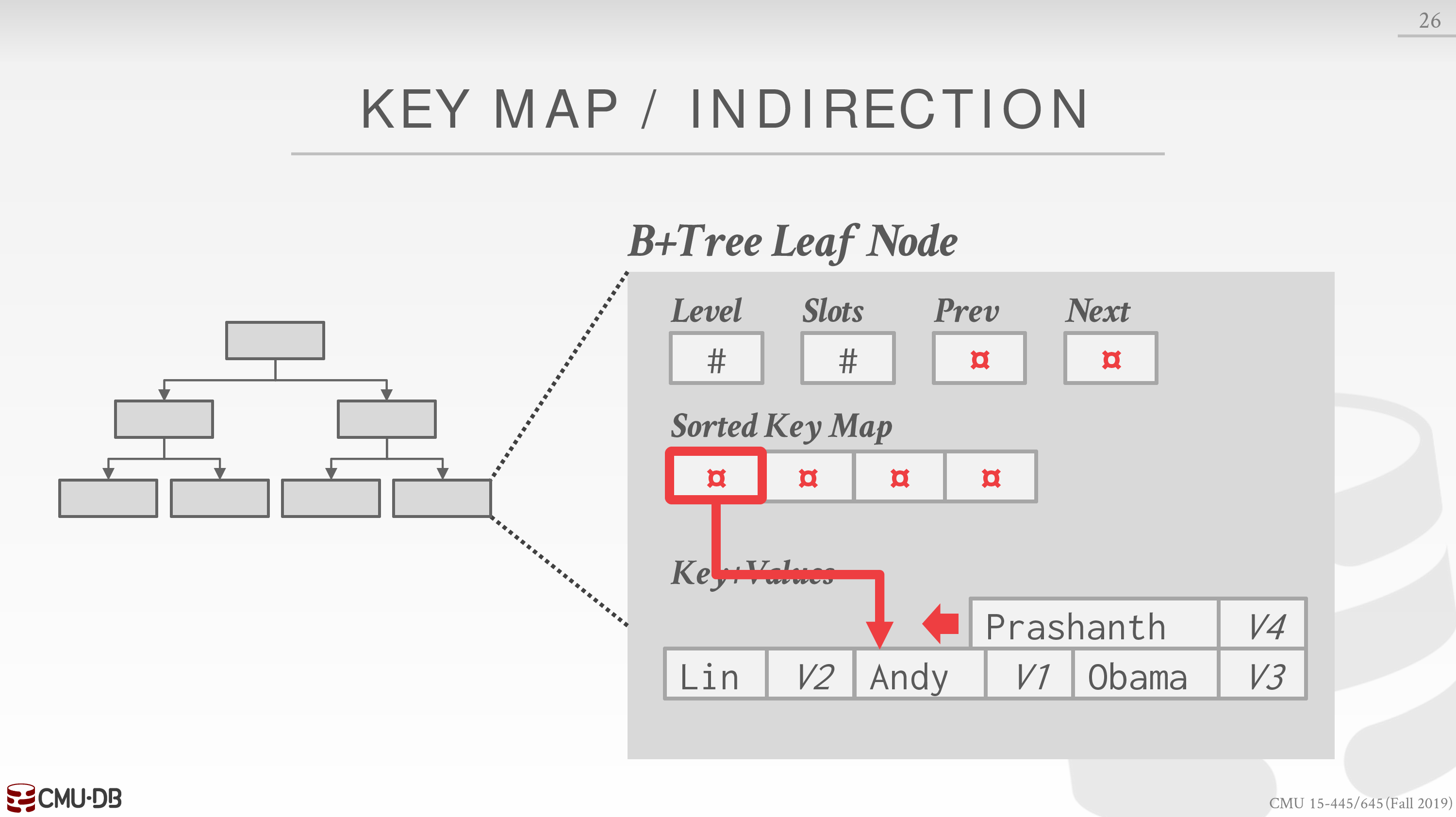
虽然是线性搜索,但由于指针指向的实际的 Key 是有序的,可以通过某些方式优化
Non-Unique Indexes
常见的两种策略
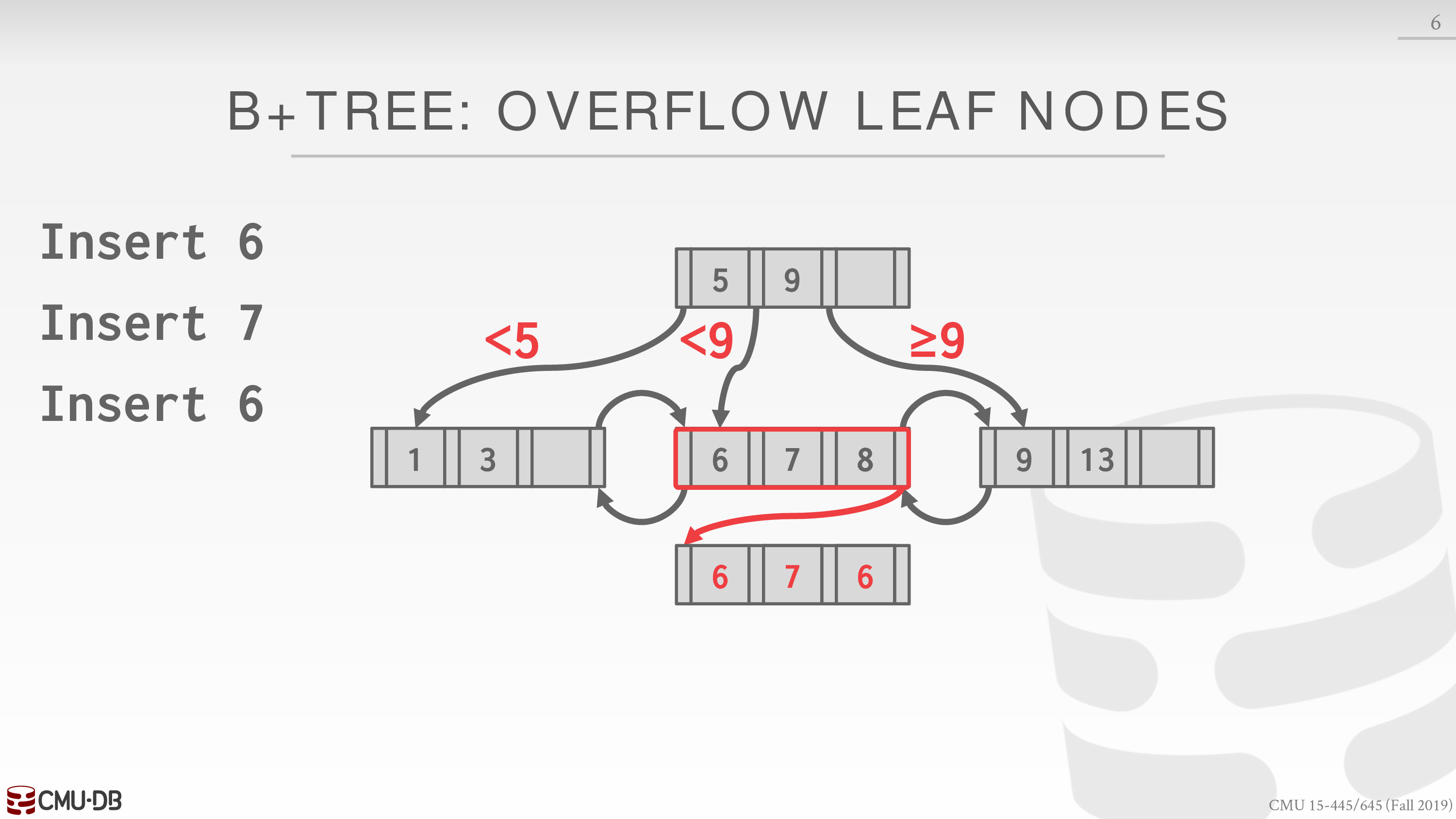
- Duplicate Keys
这种策略有两种实现方式
将 key 对应的 record-id 追加到 key 后,从而形成 unique 的 key
相当于组合索引
在搜索时,利用 B+Tree **部分查询(对于组合索引而言)**的特性,可以找到所有满足条件,即前缀为 key 的条目
另一种方式是直接插入,当叶子节点溢出时,使用额外的追加页,从而避免分裂开销,不必维护局部有序性,直接线性搜索找到所有满足条件的条目
- Value Lists
维护 record-id 的序列
Intra-Node Search
在叶子节点的 Sorted Keys 中定位到 Key
取决于 Key 是否有序,采用线性或二分搜索
也可以根据 Key 的分布进行一些计算
Optimizations
Prefix Compression
相同前缀合并
Suffix Truncation
不同后缀截断
Bulk Insert
当预先知道 Keys 的序列时,排序后自底向上建树(构建索引)
比如在 DBMS 中手动要求索引
Pointer Swizzling
注意树中节点实际上对应着 pages
所以内部节点 Value 和叶子节点的 prev 和 next 实际上都是一些 page-id
需要通过 buffer pool 从内存中获得实际的数据
如果 buffer pool 中的一些 pages 是 pin 的,那么可以直接存储指向这些 pages 的指针
比如 DBMS 会将树中上层内部节点的 value 对应的页面 pin,从而减少时间开销
Lecture #08 - Trees Indexes II
Index Demo
以 sqlite3 为例
以 hw1 为例
初始化数据库时,DBMS 会自动创建一些索引
sqlite> .indicessqlite_autoindex_CustomerCustomerDemo_1sqlite_autoindex_CustomerDemographic_1sqlite_autoindex_Customer_1sqlite_autoindex_EmployeeTerritory_1sqlite_autoindex_OrderDetail_1sqlite_autoindex_Territory_1sqlite> SELECT * FROM sqlite_master WHERE type = 'index';index|sqlite_autoindex_Customer_1|Customer|5|index|sqlite_autoindex_OrderDetail_1|OrderDetail|15|index|sqlite_autoindex_CustomerCustomerDemo_1|CustomerCustomerDemo|17|index|sqlite_autoindex_CustomerDemographic_1|CustomerDemographic|19|index|sqlite_autoindex_Territory_1|Territory|23|index|sqlite_autoindex_EmployeeTerritory_1|EmployeeTerritory|25|sqlite> .schema sqlite_masterCREATE TABLE sqlite_master ( type text, name text, tbl_name text, rootpage integer, sql text);考虑 hw1 中的部分请求
sqlite> EXPLAIN QUERY PLAN ...Q1
sqlite> EXPLAIN QUERY PLAN SELECT CategoryName FROM Category ORDER BY CategoryName;QUERY PLAN|--SCAN TABLE Category`--USE TEMP B-TREE FOR ORDER BY生成临时的 B-TREE 用于排序
Q3
sqlite> EXPLAIN QUERY PLAN select Id, ShipCountry, printf("NorthAmerica")from 'Order'where Id >= 15445 and ShipCountry in ('USA', 'Mexico', 'Canada')unionselect Id, ShipCountry, printf("OtherPlace")from 'Order'where Id >= 15445 and ShipCountry not in ('USA', 'Mexico', 'Canada')order by Idlimit 20;QUERY PLAN`--MERGE (UNION) |--LEFT | `--SEARCH TABLE Order USING INTEGER PRIMARY KEY (rowid>?) `--RIGHT `--SEARCH TABLE Order USING INTEGER PRIMARY KEY (rowid>?)使用 PRIMARY KEY,即自动生成的 clustered index
Q4
sqlite> EXPLAIN QUERY PLAN with delay (name, res) as ( select CompanyName, count(*) from 'Order' as o, Shipper as s where o.ShipVia == s.Id and o.ShippedDate > o.RequiredDate group by CompanyName)select CompanyName, printf("%.2f", res * 100.0 / count(*))from 'Order' as o, Shipper as s, delay as dwhere o.ShipVia == s.Id and s.CompanyName == d.namegroup by CompanyNameorder by 2 desc;QUERY PLAN|--MATERIALIZE 1| |--SCAN TABLE Order AS o| |--SEARCH TABLE Shipper AS s USING INTEGER PRIMARY KEY (rowid=?)| `--USE TEMP B-TREE FOR GROUP BY|--SCAN TABLE Order AS o|--SEARCH TABLE Shipper AS s USING INTEGER PRIMARY KEY (rowid=?)|--SEARCH SUBQUERY 1 AS d USING AUTOMATIC COVERING INDEX (name=?)|--USE TEMP B-TREE FOR GROUP BY`--USE TEMP B-TREE FOR ORDER BYCOVERING INDEX,在下面的 Additional Index Magic 会提到
一般而言,如果没有索引,DBMS 会使用线性搜索 SCAN
目前不清楚如何在 sqlite3 中创建 Hash Indexes
对于 Hash Indexes,对单点查询支持良好
对于 B+Tree Indexes,对范围和部分查询支持良好
若查询极值,SCAN 可能比 B+Tree Indexes 更好,考虑到 Indexes 的开销
总之,DBMS 会在不同的查询请求和多种索引中寻找最优解
Additional Index Magic
- IMPLICIT INDEXES
主键约束和唯一约束
有点类似 clustered index
- PARTIAL INDEXES
https://www.sqlite.org/partialindex.html
在一个表的部分记录上创建索引
有一个 WHERE 子句
CREATE INDEX po_parent ON purchaseorder(parent_po) WHERE parent_po IS NOT NULL;- COVERING INDEXES
处理查询的所有字段都能在索引中找到
不必访问索引的 Value
- INDEX INCLUDE COLUMNS
在索引中存储额外的列
额外的列不属于 Key
- FUNCTIONAL/EXPRESSION INDEXES
https://www.sqlite.org/expridx.html
Tries / Radix Trees
注意到一个现象
当使用 B+Tree Indexes 时,为了判断一个 Key 是否在索引中,我们需要到对应的叶子节点进行线性搜索
而 Tries / Radix Trees 可以不必到叶子节点,就能判断出来
Tries Trees 即前缀树
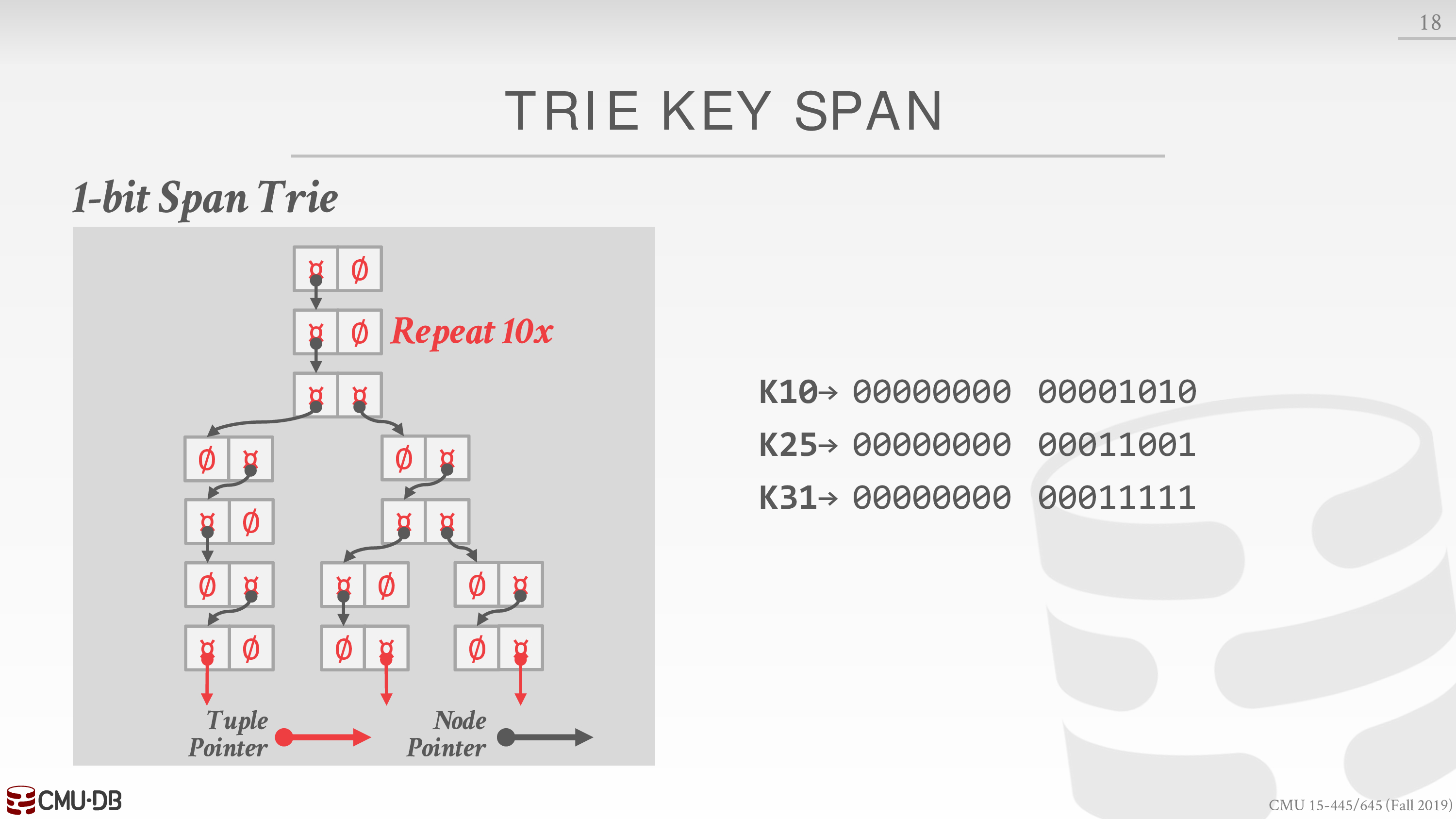
忽略一些无用节点就变成了 Radix Trees

我们考虑如下的 Tries Trees,其比特数为
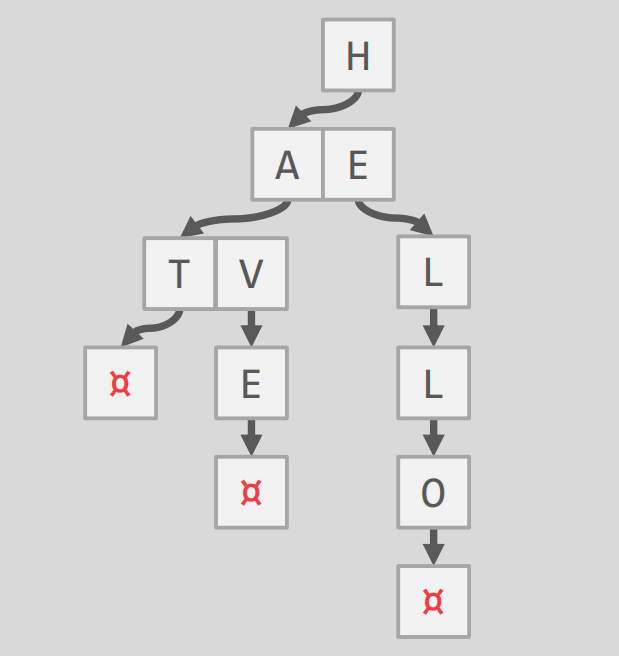
可以发现为了简化书写,其中省略了很多 ∅
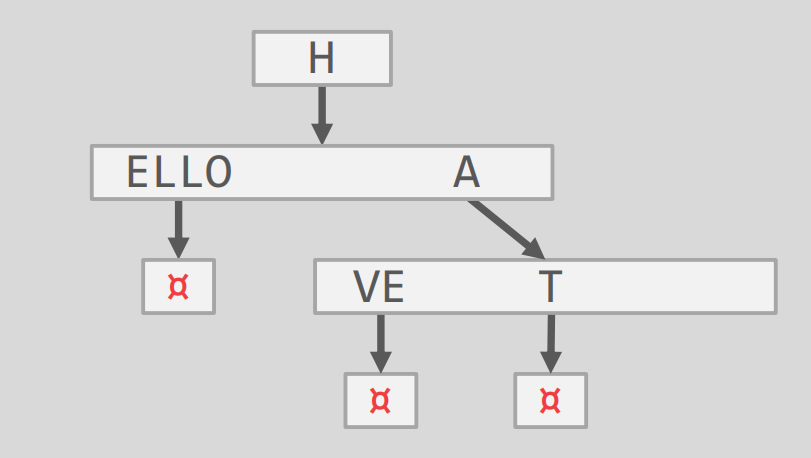
其等价的 Radix Trees 为
Inverted Indexes
目前的索引支持良好的请求场景有
- point queries
- range queries
但是对 keyword queries 支持并不良好
Find all Wikipedia articles that contain the word “Pavlo”.
我们可以使用 inverted index
An inverted index stores a mapping of words to records that contain those words in the target attribute.
目前主流的索引技术有三种:倒排文件、后缀数组和签名。后缀数组的方法虽然快,但是其维护困难,代价相当高,不适合做引擎的索引。签名是一种很好的索引方式,但倒排文件的速度和性能已经超过了签名。
Inverted indexes are covered in CMU 11-442.
We did not discuss geo-spatial tree indexes:
- Examples: R-Tree, Quad-Tree, KD-Tree
- This is covered in CMU 15-826.
Lecture #09 - Index Concurrency Control
Concurrency Control
Concurrency Control 主要是维护数据两方面的正确性
- Logical Correctness: Can I see the data that I am supposed to see?
- Physical Correctness: Is the internal representation of the object sound?
这节课主要考虑维护 Physical Correctness,主要工具就是 latch
强化一下之前对于 lock 和 latch 的认知
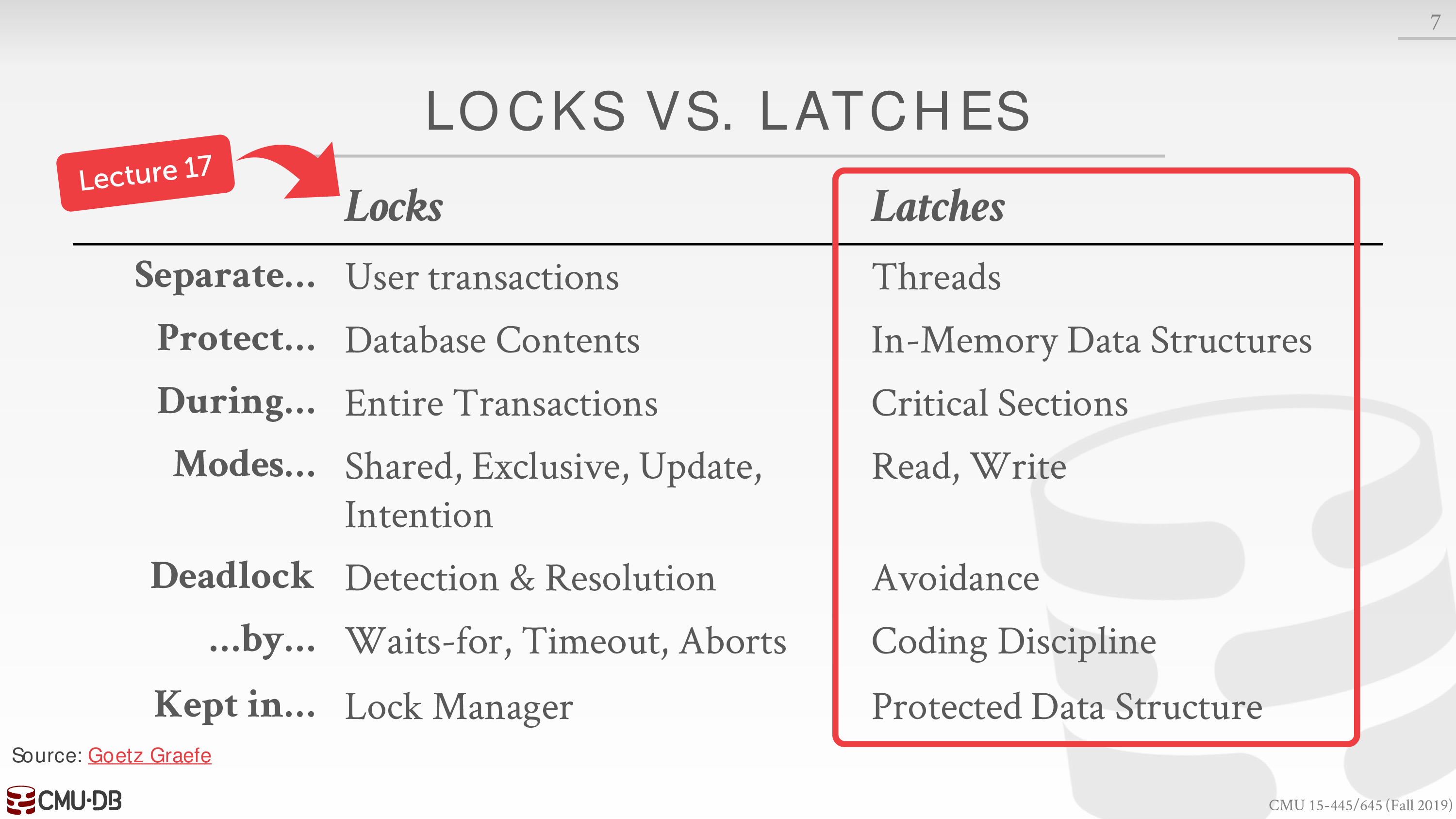
latch 用来保证数据库内部数据结构能够在线程之间保持同步
Latches Overview
latch 有两种模式,读模式和写模式
类似读写锁,不多赘述
实现有多种方式
- OS 提供的 std::mutex
- 硬件提供的原子操作,典型为 CAS
通过第二种方式就可以实现 latch 的两种模式
Hash Table Latching
考虑最简单的线性探测,由于扫描顺序相同,不会发生死锁现象
当需要 rehash 时,只需要对整个 table 加锁即可
下面考虑 table 大小固定的情形
可以有两种粒度的 latch
- page latch
- slot latch
注意 table 可能横跨多个 page
具体例子见课件
B+Tree Latching
考虑多线程的两种场景
第一个场景:两个线程同时 access 或 modify 节点
主要策略称为 latch crabbing / coupling
基本思想是获得父节点的 latch,再获得子节点的 latch
如果对子节点的操作不会波及父节点,即保证父节点不会分裂或合并
则释放父节点的 latch
对于 access 的线程而言,获取的都是 read latch
对于 modify 的线程而言,获取的都是 write latch
由于一般节点的大小都很大,所以分裂或合并的情形并不常见
所以可以优化 modify 的线程获取 read latch,当然最后的叶子节点获取的是 write latch
若 modify 后会波及父节点,则重启操作,都获取 write latch
若不会波及,那么性能就得到了提升
write latch 是独占的
具体见课件
Leaf Node Scans
第二个场景:一个线程 access 或 modify 节点,另一个节点 scan 叶子节点
可能会出现死锁情形
于是要求当一个线程陷入等待时,立刻重启操作
具体见课件
Delayed Parent Updates
进一步优化第一个场景中,modify 后会波及父节点的情形
不必重启操作,延迟更新父节点
具体见课件
Lecture #10 - Sorting + Aggregations
Layer → Operator Execution
查询计划
将操作符组织为一棵树
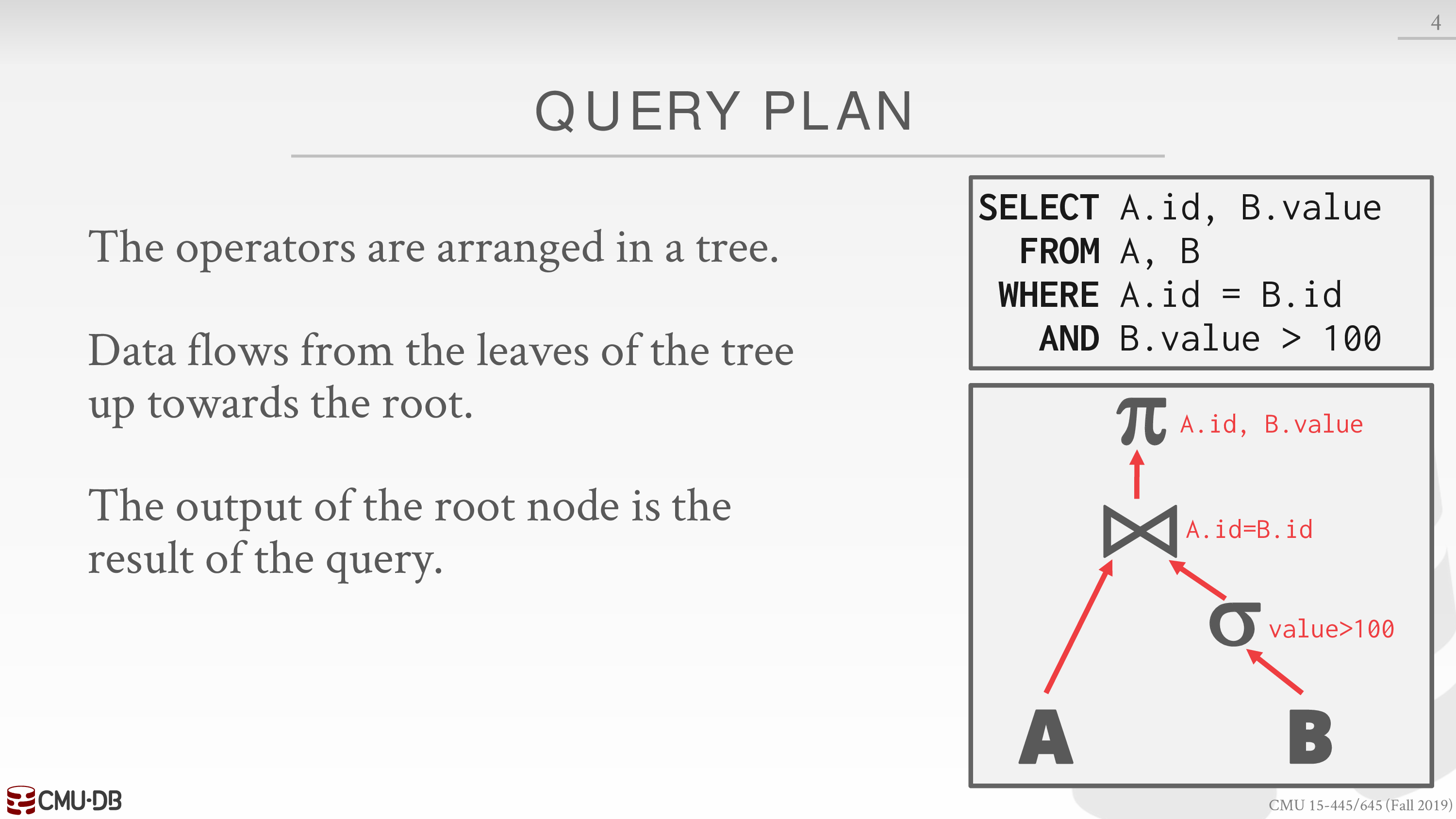
这一节主要讨论操作符实现的具体算法
External Merge Sort
注意到 tuple 的无序性
所以排序操作是很常见的
由于数据不一定能够全部放到内存中
所以一些就地排序算法,如快速排序,涉及到大量随机 I/O,就不太高效
所以我们介绍外部归并排序
我们使用 buffer pool 存放临时的 page
若 buffer pool 可用 𝓑 个 page
𝓐𝓑𝓒𝓓𝓔𝓕𝓖𝓗𝓘𝓙𝓚𝓛𝓜𝓝𝓞𝓟𝓠𝓡𝓢𝓣𝓤𝓥𝓦𝓧𝓨𝓩
而数据可以分割为 𝓝 个 page
在第一轮,我们将这 𝓑 个 page 置于 buffer pool 中进行排序,相当于得到了 ⌈𝓝/𝓑⌉ 组有序的 runs
在接下来的每一轮,归并 𝓑 - 1 组 runs,形成更大的 runs
空出一个 page 用于存放输出,若满了则写回 disk,清空后继续接受输出
直至排序完成
可归纳如下

注意这里的成本
这里有一个例子

关键在于使用 buffer pool 在 disk 和 memory 之间传递 page,详见课件
可以通过预读和多线程的方式减少等待 I/O 请求的时间
如果排序的字段是 clustered index,那么可以使用 B+Tree 加速排序
这里要求必须是 clustered index,保证键值的逻辑顺序决定了表中相应行的物理顺序,避免随机 I/O
如果不是 clustered index,有如下的优化方式

Aggregations
下一个操作是聚合操作
我们有两种实现策略
Sorting
比如 DISTINCT 聚合操作
排序后去重会非常容易
Hashing
如果我们并不需要数据是有序的,我们可以考虑哈希的策略
仍然考虑数据不一定能够全部放到内存中的情形
核心思想仍然是 divide and conquer
分为两个阶段
- Phase #1 – Partition
Divide tuples into buckets based on hash key.
Write them out to disk when they get full.
- Phase #2 – ReHash
Build in-memory hash table for each partition and compute the aggregation.
第一阶段利用了哈希的局部性,若 buffer pool 可用 𝓑 个 page,则分为 𝓑 - 1 个 partitions
空出一个 page 用于存放输入
注意对结果取模
第二阶段可能需要根据具体的聚合操作维护一些 Running Totals,如 sum 或 count
两个阶段使用的哈希函数是不同的,可能是不同的哈希种子
具体的例子见课件
Project
每一年的 project2 似乎都不同
2019 → linear probing hash table
2020 → B+Tree
2021 → extendible hash table
Lecture #11 - Joins Algorithms
这一节主要讲 join 操作的实现
We will focus on combining two tables at a time with inner equijoin algorithms.
Joins
考虑 join 操作的两个方面
Operator Output
可以是数据,直接全部拷贝过来,或根据 projection 操作有选择的拷贝
可以是 Record ID,这种技术被称为 late materialization,适合于以列为单位的 DBMS
通常 join 作为中间操作,其结果会被缓存下来,若结果太大,则溢出到 disk 中
Cost Analysis
成本模型是 I/O 次数
定义一些变量
- M pages in table R, m tuples total
- N pages in table S, n tuples total
Nested Loop Join
本质上是二重循环
The table in the outer for loop is called the outer table, while the table in the inner for loop is called the inner table.
outer table 也被称为 left table
DBMS 希望 outer table 比较小,这里的小可能是 page,也可能是 tuple
Simple Nested Loop Join
foreach tuple r ∈ R: foreach tuple s ∈ S: emit, if r and s match成本
于是 outer table 的 tuple 要比较小
Block Nested Loop Join
没有必要每个 tuple 都读取一遍表 S
foreach block Br ∈ R: foreach block Bs ∈ S: foreach tuple r ∈ Br: foreach tuple s ∈ Bs: emit, if r and s match成本
于是 outer table 的 page 要比较小
如果我们有 buffer pool,并且 buffer pool 可用 𝓑 个 page
那么我们可以将 outer table 存放在 buffer pool 中,以减少冗余的 I/O 次数
- Use
𝓑 - 2buffers for scanning the outer table. - Use one buffer for the inner table, one buffer for storing output.
foreach B - 2 blocks Br ∈ R: foreach block Bs ∈ S: foreach tuple r ∈ Br: foreach tuple s ∈ Bs: emit, if r and s match成本
Index Nested Loop Join
注意到上面的两种算法在底层仍然是线性搜索
考虑引入索引,假设 inner table 中有 join key 的索引
foreach tuple r ∈ R: foreach tuple s ∈ Index(ri = sj): emit, if r and s match成本
这里的 𝓒 取决于索引的类型,如 hash index 或 B+Tree index
Sort-Merge Join
先根据 join key 做排序操作,然后通过两个游标收集结果
排序操作的成本见上一节
归并操作的成本通常为
key 分布越不均匀,成本越高
最坏情形为所有的 key 均相同
通常 Sort-Merge Join 是很有用的,特别是 join key 本身就是 clustered index,或者 SQL 请求中有 order by,因为收集的结果是有序的
Hash Join
Basic Hash Join
- Phase #1: Build
Scan the outer relation and populate a hash table using the hash function h on the join attributes.
- Phase #2: Probe
Scan the inner relation and use h on each tuple to jump to a location in the hash table and find a matching tuple.
注意这里使用的是相同的哈希函数
value content 可以是完整的 tuple,也可以是 Record ID
类似之前的 Operator Output
可以优化 Probe 阶段
在 Build 阶段使用 Bloom Filter
从而 Probe 时若 Bloom Filter 返回 false,则一定不存在匹配,就不必 Probe 了
Bloom Filter 不会出现假阴性,即漏报的情形
在数据无法全部放到内存中的情形下,减少无意义的 disk I/O 甚至 network I/O
Grace Hash Join
下面考虑数据无法全部放到内存中的情形
由于是随机 I/O,访问 inner table 成本相当高
我们考虑对两个表同时进行哈希,利用哈希的局部性,在 bucket 上进行 Nested Loop Join
类似 Hash Aggregation,但是哈希函数是相同的
动态还是静态取决于哈希表的大小是否固定或可预测
若相同 key 的 bucket 溢出,可以使用 recursive partitioning
成本分析见课件
Lecture #12 - Query Execution I
Processing Models
A DBMS’s processing model defines how the system executes a query plan.
These models can also be implemented to invoke the operators either from top-to-bottom (most common) or from bottom-to-top.
下面以 top-to-bottom 为例,通过函数调用传递 tuples
Iterator Model
Also called Volcano or Pipeline Model.
所有的运算符需要实现 next 方法
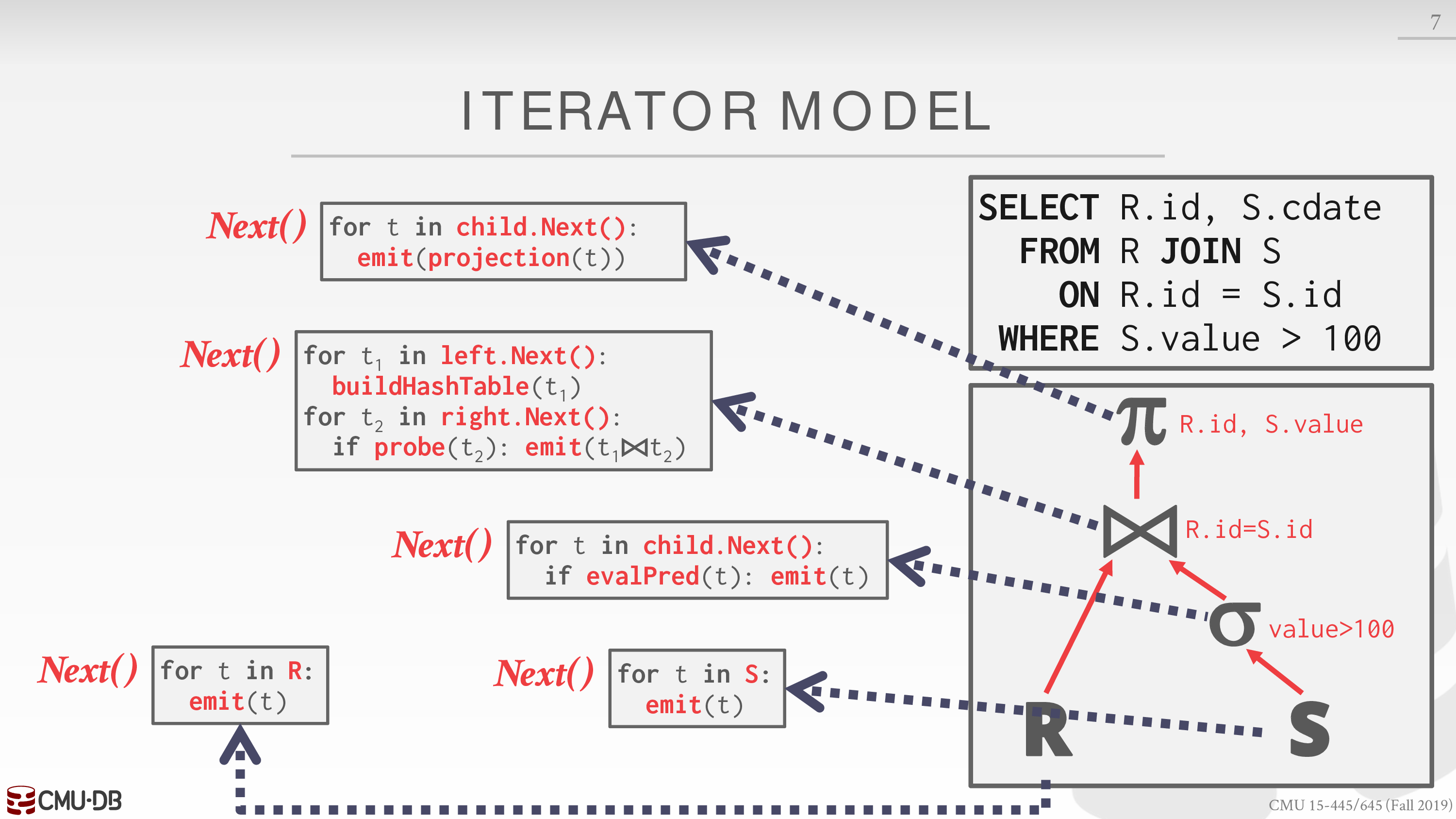
注意这里的 emit 类似 yield,每次 emit 一个 tuple
in 后面的东西相当于迭代器
Materialization Model
所有的运算符需要实现 output 方法
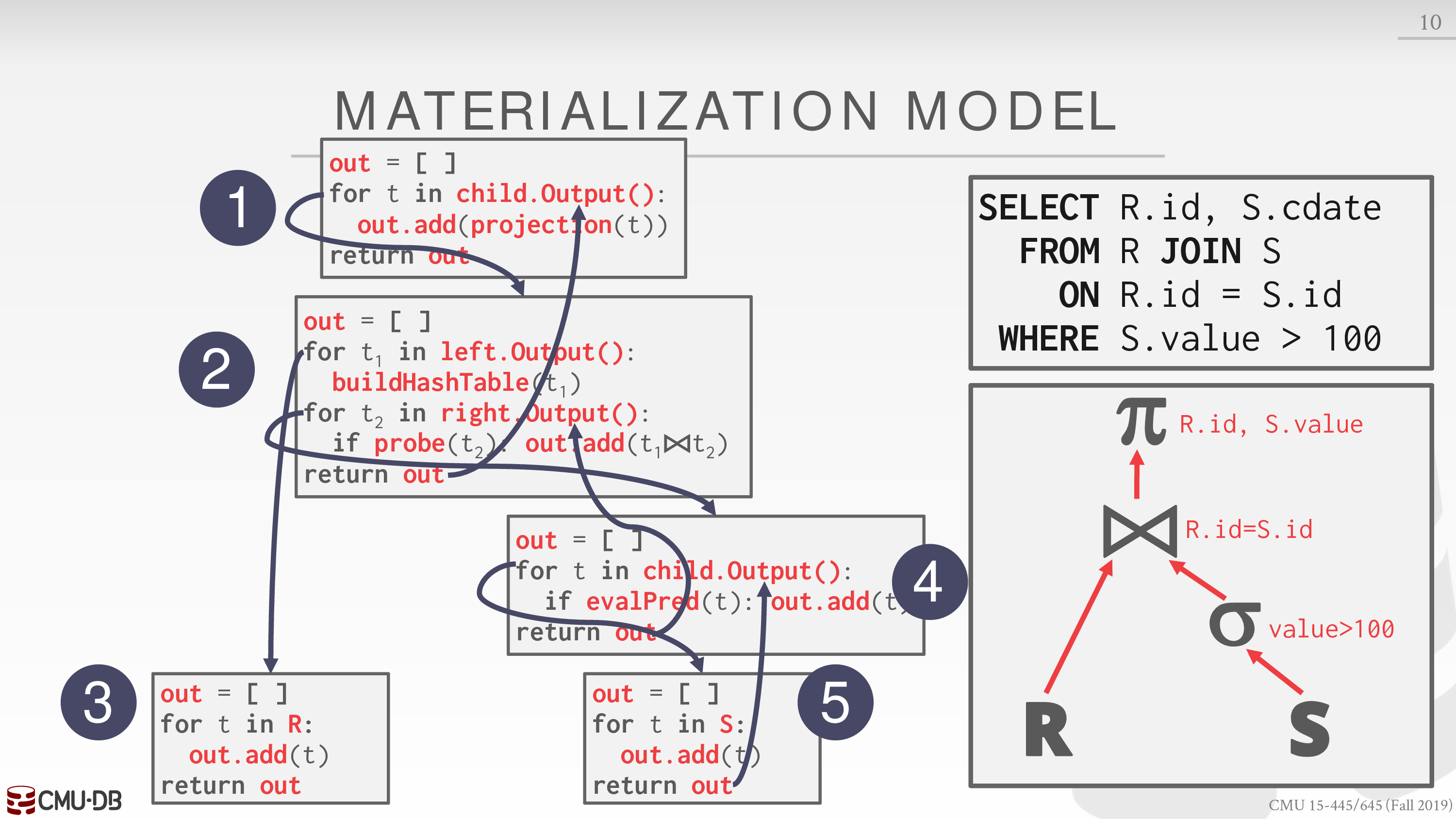
一次性发送所有的 tuples
更适合 OLTP,减少函数调用开销
可以利用 late materialization 减少传递的数据量
Vectorized / Batch Model
类似 Iterator Model
每次发送一组 tuples
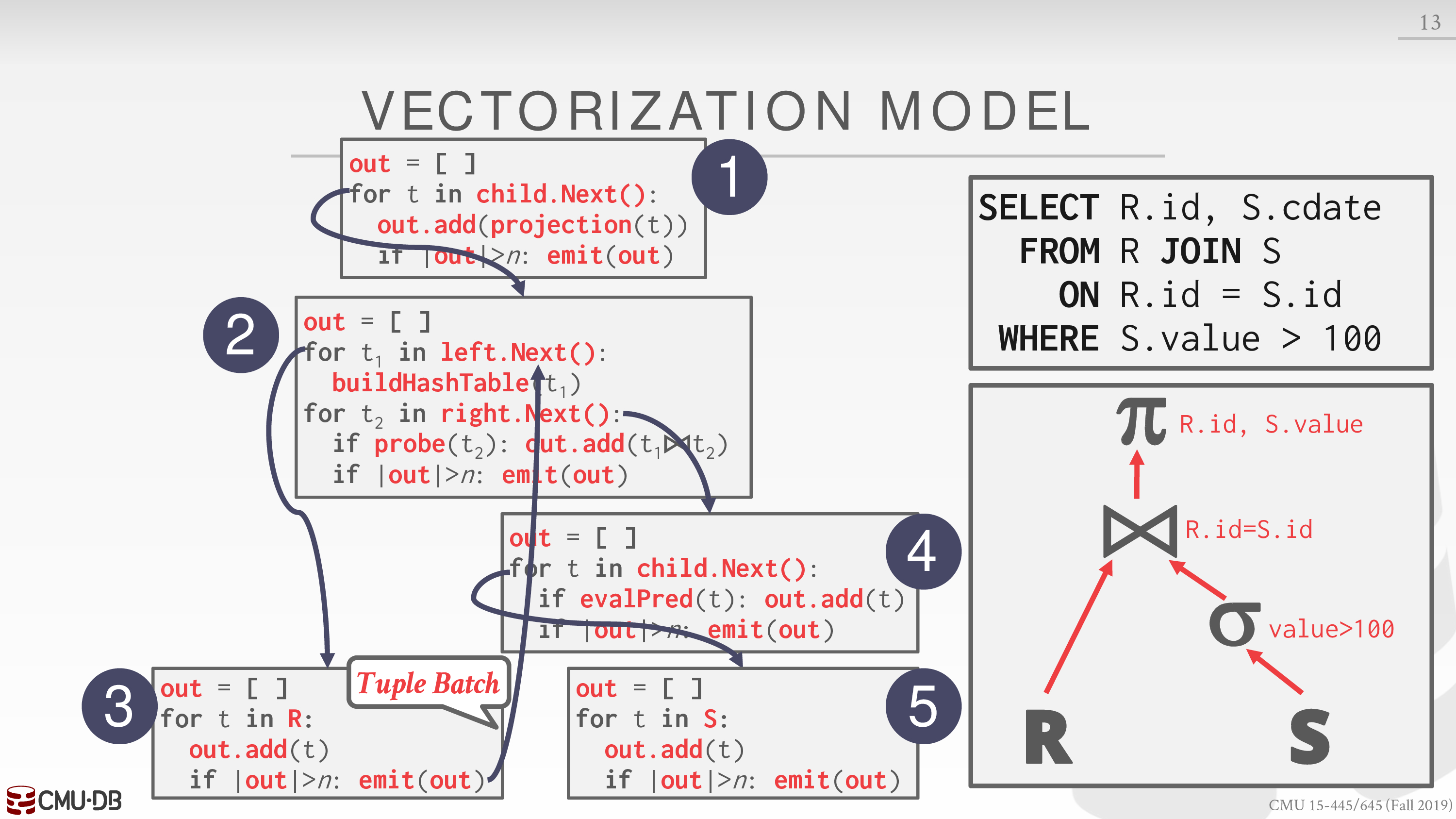
可以利用 SIMD 快速处理一组 tuples
Access Methods
对于 Processing Models 中 for t in ... 的部分,需要使用 Access Methods 获得对应的数据
Sequential Scan
最基本的扫描方式
一些优化手段
- Prefetching → 减少等待 I/O 请求的时间
- Buffer Pool Bypass → 防止一些临时数据污染 buffer pool
- Parallelization → 见 Lecture #13
- Zone Maps → 记录数据的一些聚合信息,如极值、平均值
- Late Materialization → 减少传递的数据量
- Heap Clustering → clustered index
Index Scan
DBMS 需要在索引中进行选择
下面是一个例子

对于情形一,选择索引 dept
对于情形二,选择索引 age
更复杂的例子见 Lecture #14
Multi-Index / “Bitmap” Scan
DBMS 可以利用多个索引,然后对各自的中间结果取交集或并集
下面是一个例子
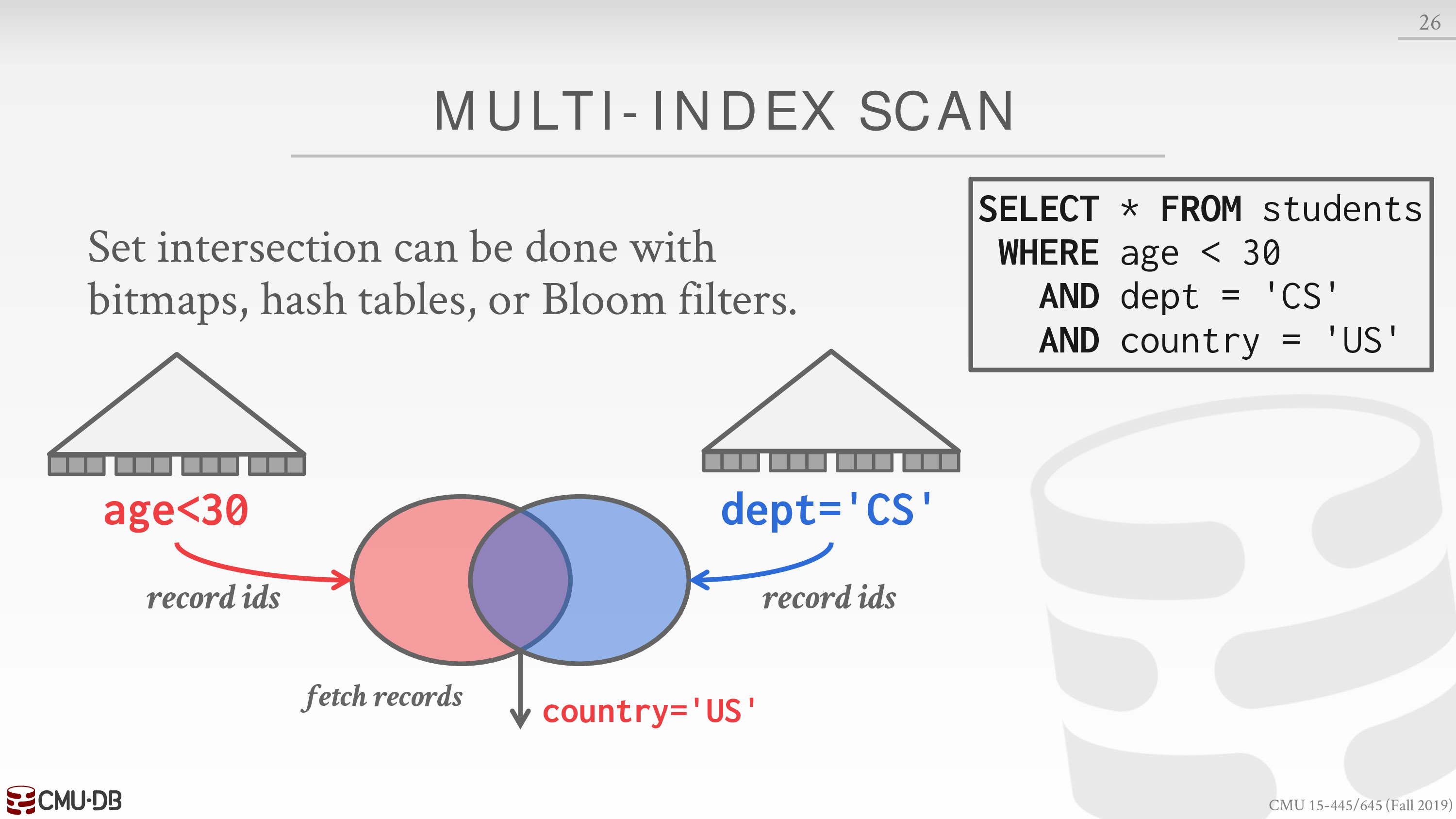
对中间结果进行操作实际上相当于 join
可以尝试上一节中的 join 算法
Expression Evaluation
The DBMS represents a WHERE clause as an expression tree.
下面有一个例子
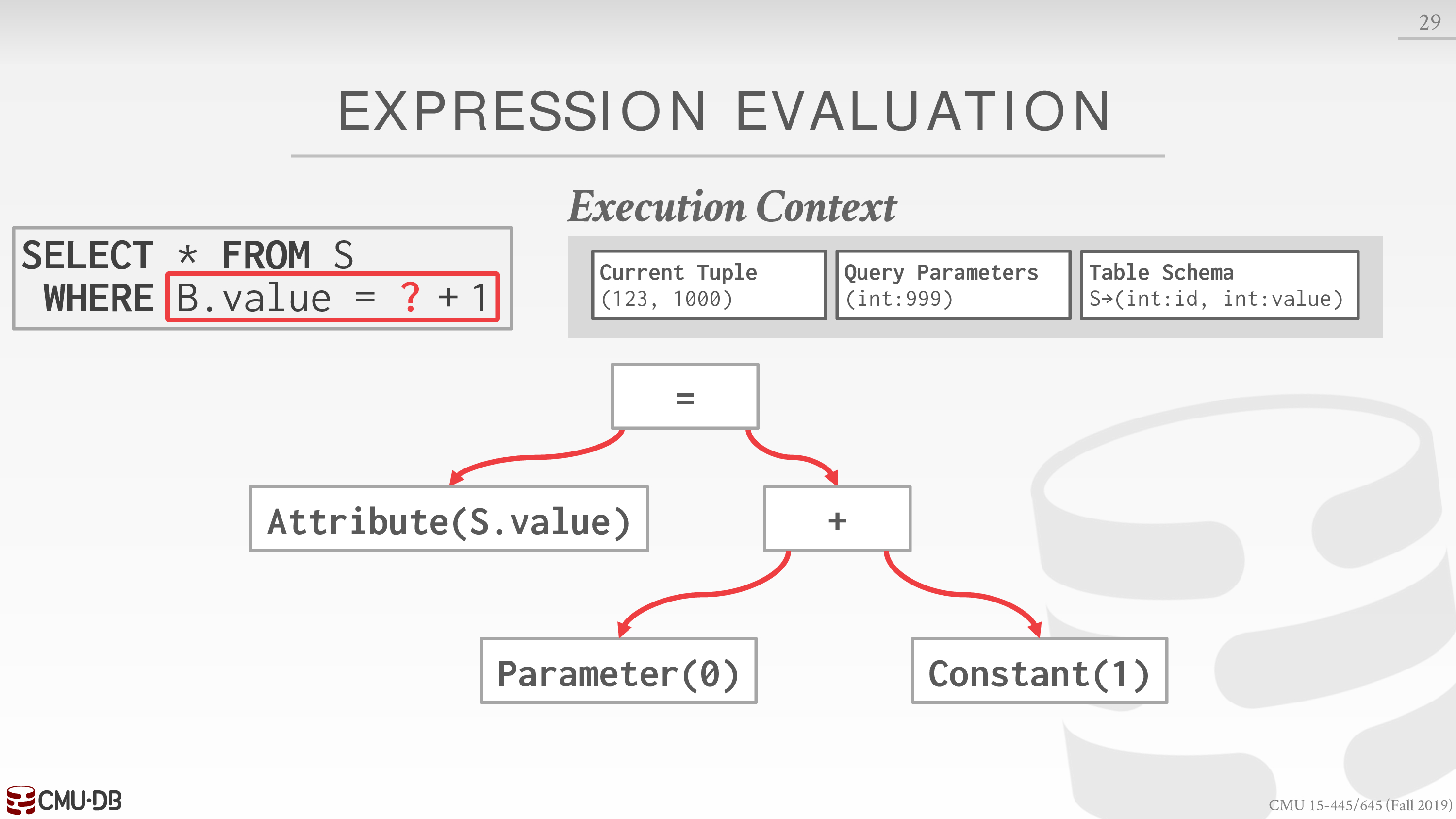
这里的 SQL 语句相当于一个模板,需要客户端输入一个参数
加一是个哲学问题
- 程序代码处理 → 指令
- DBMS 处理 → 模拟
还有一些无意义的 where 子句,可以将其直接编译成指令,而不必遍历一遍表达式树

Lecture #13 - Query Execution II
上一节我们假定只有一个 worker 在执行 SQL 请求
现在我们考虑使用多个 worker 来执行 SQL 请求
根据 resources 的分布,可以将多个 worker 的 DBMS 细分为
Parallel DBMSs:
- Resources are physically close to each other.
- Resources communicate with high-speed interconnect.
- Communication is assumed to cheap and reliable.
Distributed DBMSs:
- Resources can be far from each other.
- Resources communicate using slow(er) interconnect.
- Communication cost and problems cannot be ignored.
Process Models
注意区分 Process Models 和上一节的 Processing Models
A DBMS’s process model defines how the system is architected to support concurrent requests from a multi-user application.
如单个用户的 OLAP,分割给多个 worker
或多个用户的 OLTP,分派给多个 worker
这里的 worker 可以是进程,也可以是线程
有三种 Process Models
Process per DBMS Worker
每一个 worker 都是 fork 出的一个进程
通过 shared-memory 共享 buffer pool manager
进程间通信
OS 负责调度
一个 worker 崩溃不会让整个系统崩溃
Process Pool
通过 Process Pool 减少 fork 开销
其余类似 Process per DBMS Worker
Thread per DBMS Worker
DBMS 负责调度
自动共享 buffer pool manager
一个 worker 崩溃可能让整个系统崩溃
The thread per worker model does not mean that the DBMS supports intra-query parallelism.
Execution Parallelism
将查询进行分类
- Inter-Query: Different queries are executed concurrently.
多个用户的 OLTP,分派给多个 worker
- Intra-Query: Execute the operations of a single query in parallel.
单个用户的 OLAP,分割给多个 worker
Inter-Query Parallelism
若每个 worker 对 DB 都是读取,那么没有问题
若存在对 DB 的修改,详见 Lecture #16
Intra-Query Parallelism
可以用生产者 - 消费者模式来理解
有三种策略,这些策略可以被综合使用
- Intra-Operator (Horizontal)
Decompose operators into independent fragments that perform the same function on different subsets of data.
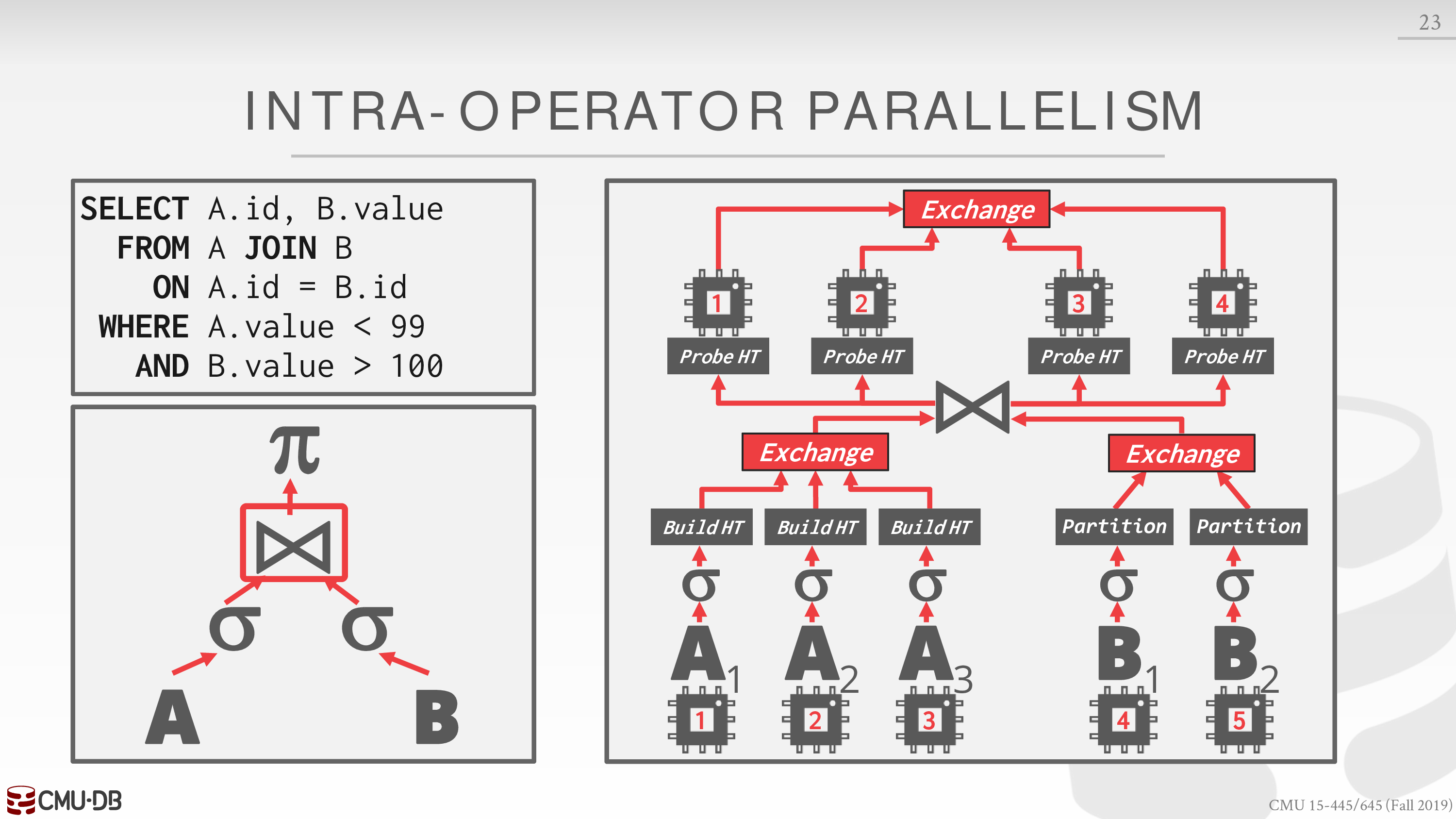
使用 exchange 操作符收集数据
exchange 操作符有不同的类型,详见课件
https://docs.microsoft.com/en-us/archive/blogs/craigfr/the-parallelism-operator-aka-exchange
- Inter-Operator (Vertical)
Operations are overlapped in order to pipeline data from one stage to the next without materialization.
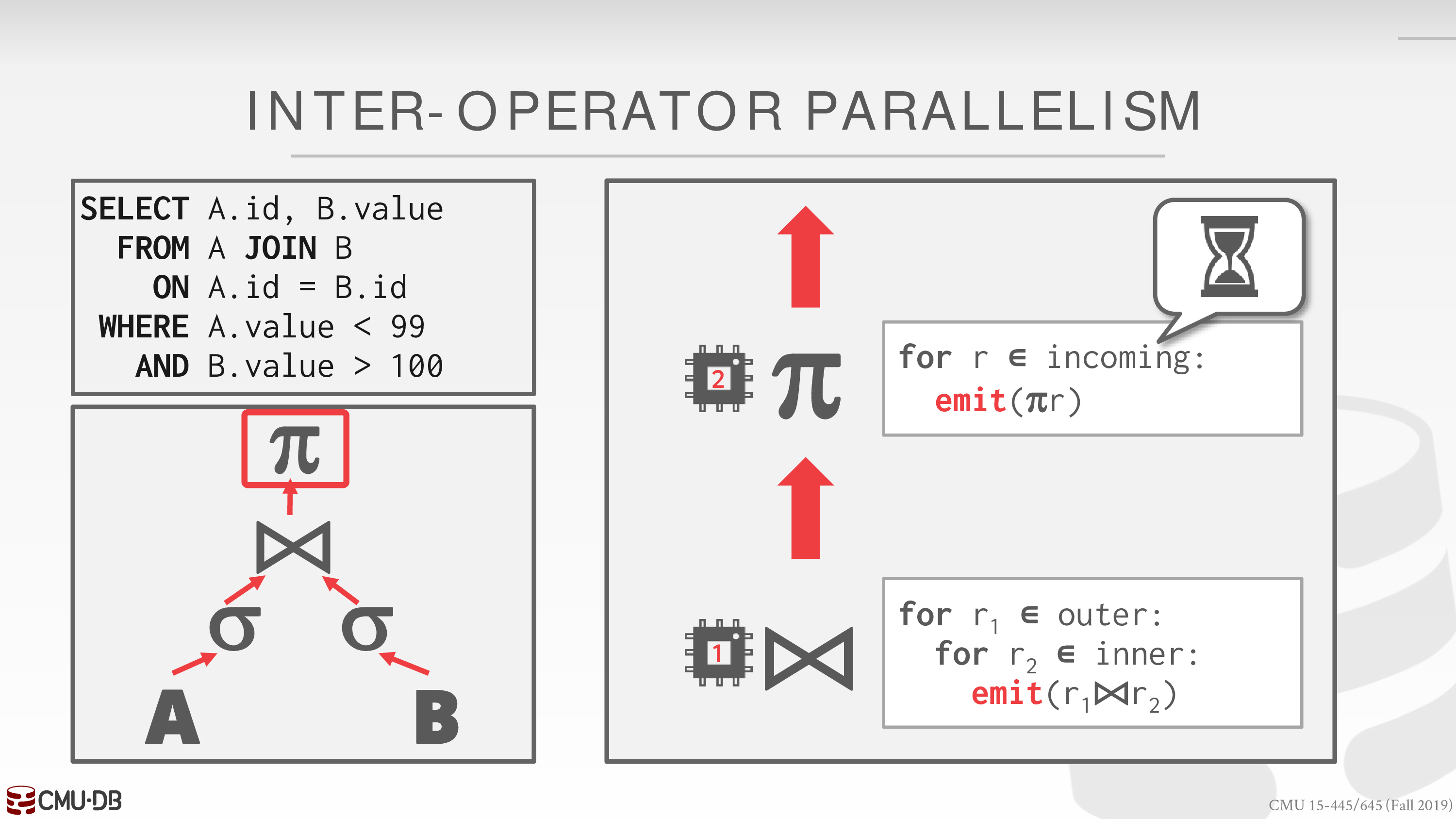
存在线程自旋现象
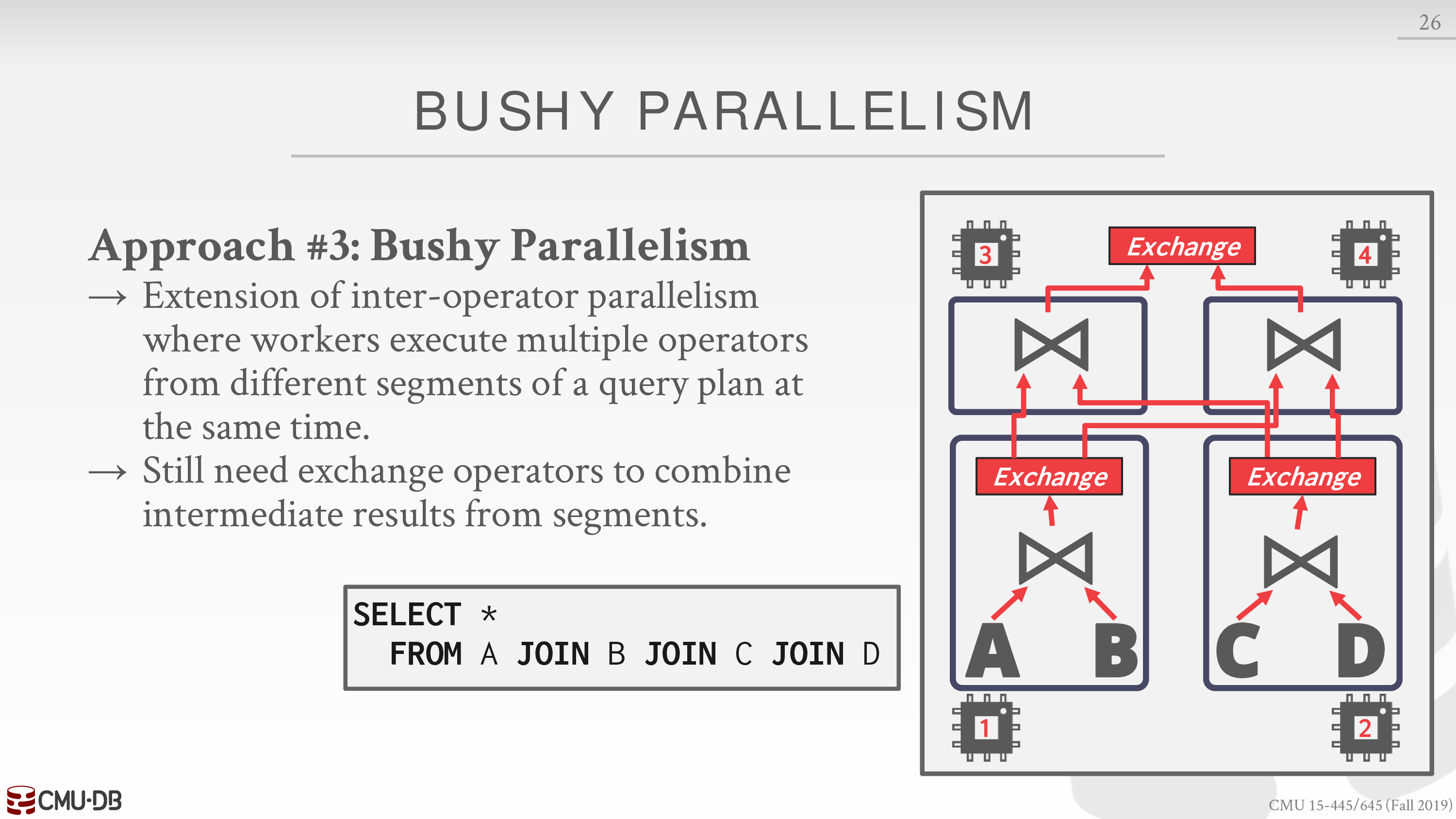
- Bushy
一图胜千言
I/O Parallelism
如果 disk I/O 是主要瓶颈的话,执行方面的并行并不会提升性能
因此我们需要考虑 I/O 方面的并行
主要有两种方式,多磁盘和分区
Multi-Disk Parallelism
将数据存储在多个磁盘中
对于 DBMS 而言,逻辑上是一个磁盘,但物理上是多个磁盘
比如 RAID 技术

File-based Partitioning
Some DBMSs allow you to specify the disk location of each individual database.
The buffer pool manager maps a page to a disk location.
Logical Partitioning
Split single logical table into disjoint physical segments that are stored/managed separately.
可以是水平分区,也可以是垂直分区
也许和 NSM 还是 DSM 相关
Lecture #14 - Query Planning & Optimization I
Overview
查询优化是 NP-Hard 的
通常分为两个部分
Heuristics / Rules
- Rewrite the query to remove stupid / inefficient things.
- These techniques may need to examine catalog, but they do not need to examine data.
Cost-based Search
- Use a model to estimate the cost of executing a plan.
- Evaluate multiple equivalent plans for a query and pick the one with the lowest cost.
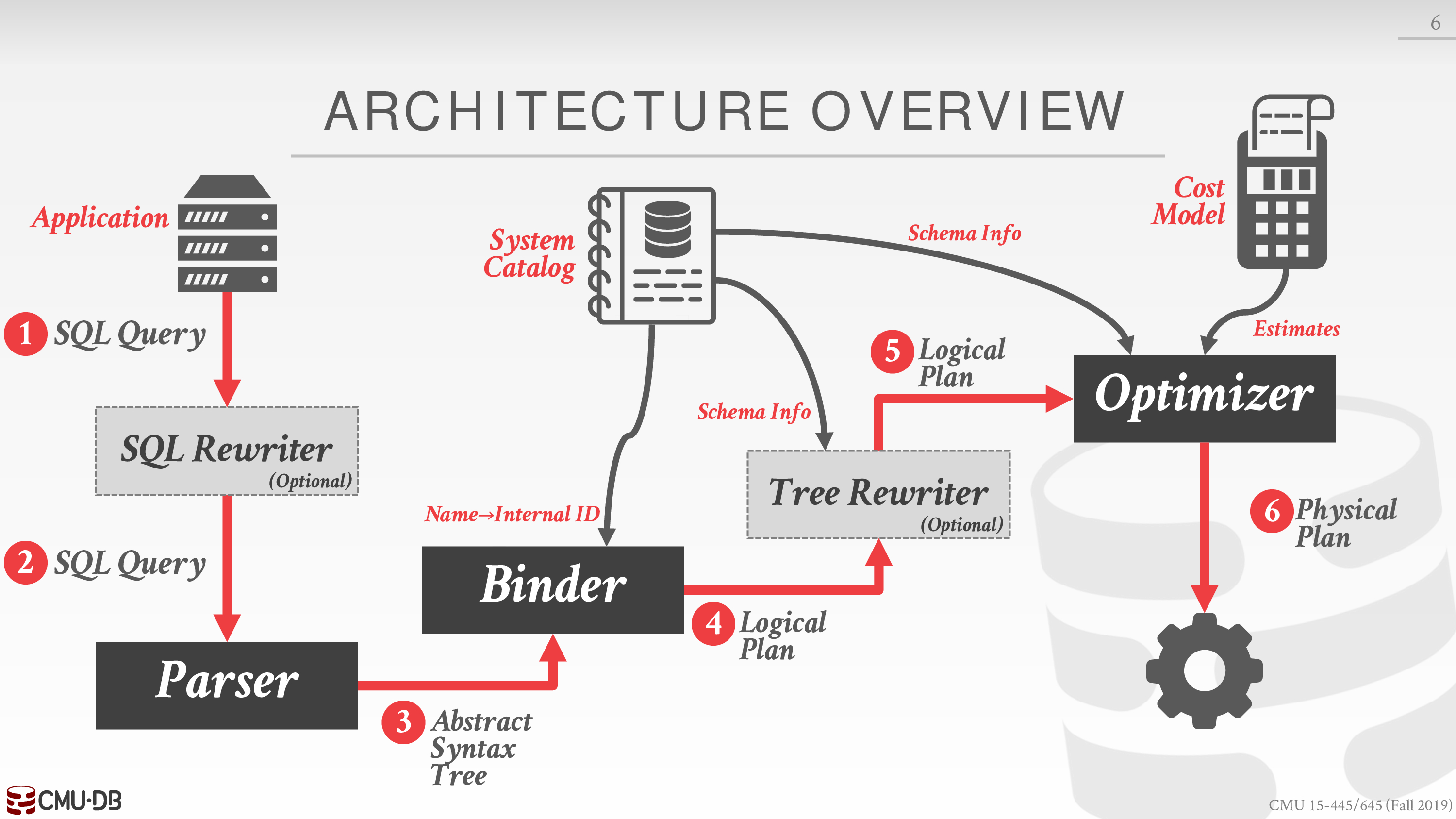
下面是全景图
需要注意 physical plan 和 logical plan 不一定是一一对应的
Rule-based Query Optimization
即 Overview 中的 rewriter
通过等价的关系代数和 catalog 信息来简化
不需要通过成本模型判断
等价代表输出相同的结果,并不一定要顺序相同
不清楚 Rule-based 的优化究竟可以 examine 多少东西
比如 catalog 中是否可能有一些表的元数据,如 Zone Maps
这样对多个谓词,我们可以重新排序,从而尽早过滤掉更多数据
但是 catalog 中有 uniqueness 或 foreign-key 或 not-null 等信息
下面是一些例子
更多的例子见 https://blog.jooq.org/10-cool-sql-optimisations-that-do-not-depend-on-the-cost-model/
Predicate Push-down
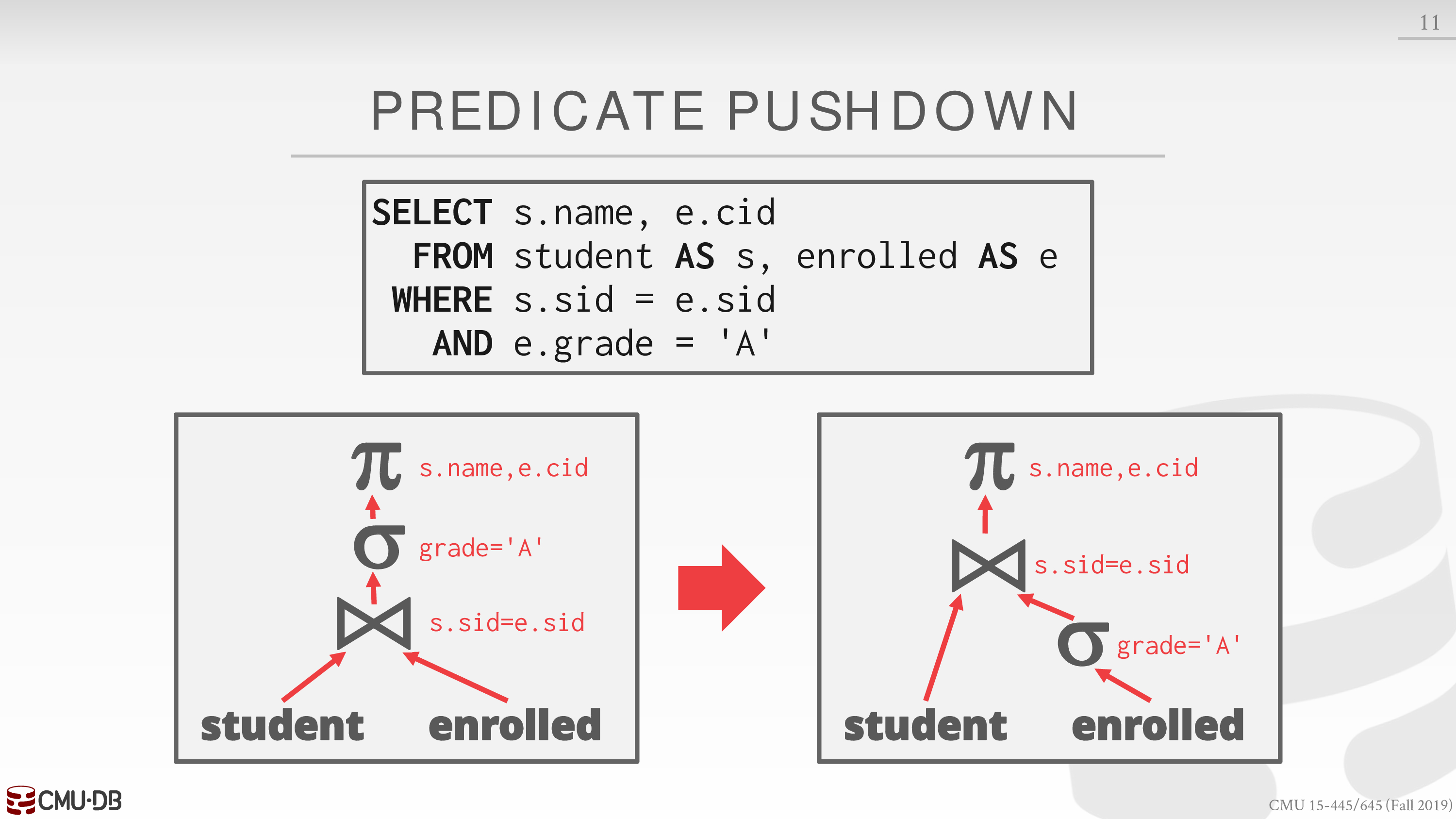
从而减少 join 的开销
也有可能相较而言 Predicate 的开销更大
不过可能就需要 examine data 来判断了
Projections Push-down
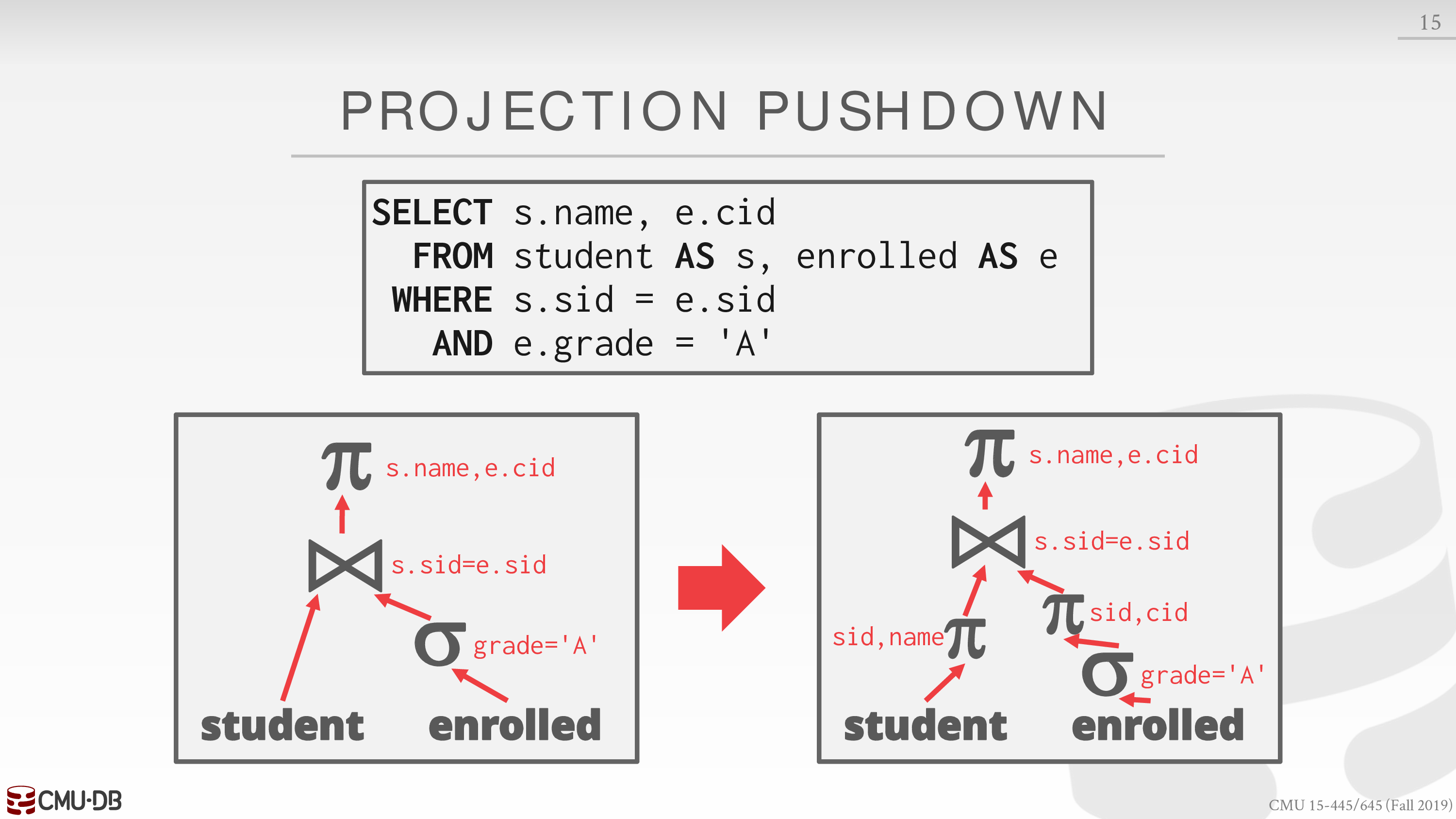
减少传递的数据量
对 DSM 而言是无意义的
Expression Simplification
比如 where 子句中有 1 = 0 或 1 = 1
下面是一个 Demo,仍以 sqlite3 为例
使用 EXPLAIN 而非 EXPLAIN QUERY PLAN
sqlite> EXPLAIN SELECT CategoryName FROM Category where 1 = 0;addr opcode p1 p2 p3 p4 p5 comment---- ------------- ---- ---- ---- ------------- -- -------------0 Init 0 8 0 0 Start at 81 Ne 2 7 1 80 if r[1]!=r[2] goto 72 OpenRead 0 3 0 2 0 root=3 iDb=0; Category3 Rewind 0 7 0 04 Column 0 1 3 0 r[3]=Category.CategoryName5 ResultRow 3 1 0 0 output=r[3]6 Next 0 4 0 17 Halt 0 0 0 08 Transaction 0 0 17 0 1 usesStmtJournal=09 Integer 1 1 0 0 r[1]=110 Integer 0 2 0 0 r[2]=011 Goto 0 1 0 0sqlite> EXPLAIN QUERY PLAN SELECT CategoryName FROM Category where 1 = 0;QUERY PLAN`--SCAN TABLE Category可以看到类似字节码的输出
似乎 QUERY PLAN 还是会扫描一遍表
不知道 Halt 是对每个 tuple 而言还是对整个查询而言
sqlite> EXPLAIN SELECT CategoryName FROM Category where 1 = 1;addr opcode p1 p2 p3 p4 p5 comment---- ------------- ---- ---- ---- ------------- -- -------------0 Init 0 8 0 0 Start at 81 Ne 1 7 1 80 if r[1]!=r[1] goto 72 OpenRead 0 3 0 2 0 root=3 iDb=0; Category3 Rewind 0 7 0 04 Column 0 1 2 0 r[2]=Category.CategoryName5 ResultRow 2 1 0 0 output=r[2]6 Next 0 4 0 17 Halt 0 0 0 08 Transaction 0 0 17 0 1 usesStmtJournal=09 Integer 1 1 0 0 r[1]=110 Goto 0 1 0 0sqlite> EXPLAIN QUERY PLAN SELECT CategoryName FROM Category where 1 = 1;QUERY PLAN`--SCAN TABLE Category更多的例子见课件和链接
Lecture #15 - Query Planning & Optimization II
Plan Cost Estimation
The DBMS stores internal statistics about tables, attributes, and indexes in its internal catalog.
Different systems update them at different times.
这意味着 Rule-based Query Optimization 可以利用这些信息在 rewriter 阶段就进行优化
在 sqlite3 中,可以输入 ANALYZE 手动进行更新
我们使用统计方法,这里以谓词的选择率为例
先定义一些东西
for a relation R
the number of tuples
the distinct values per attribute
the selection cardinality
比如一个表中有 100 个 tuple,对于某个字段,有 10 个不同的取值,那么对于某个取值的选择率即为 10%
这里假定数据满足均匀分布
为了方便的计算合取和析取,还可以假定不同字段的取值是独立的
这样就可以利用概率论的知识计算各种各样的选择率
然而,现实世界中数据并不一定满足上述特性
我们可以对一个表的每个字段绘制直方图,通常这样做的成本是很高的
为了降低成本,可以将相邻的值合并
除了绘制直方图,也可以通过采样的方式近似计算选择率
Plan Enumeration
接着上面谓词的选择率的例子
我们考虑对查询单张表的请求进行优化
简单来说,有两个关键的方面
- access method → 使用简单的启发式方法
- predicate evaluation ordering → 使用上述的谓词的选择率,尽早过滤掉更多数据
对于查询多张表的请求,可能的查询计划会大大增加
为此有两种方式减少搜索空间
- dynamic programming
相较于查询单张表,我们需要枚举 join 的顺序
为了减少搜索空间,可以只考虑 left-deep join trees
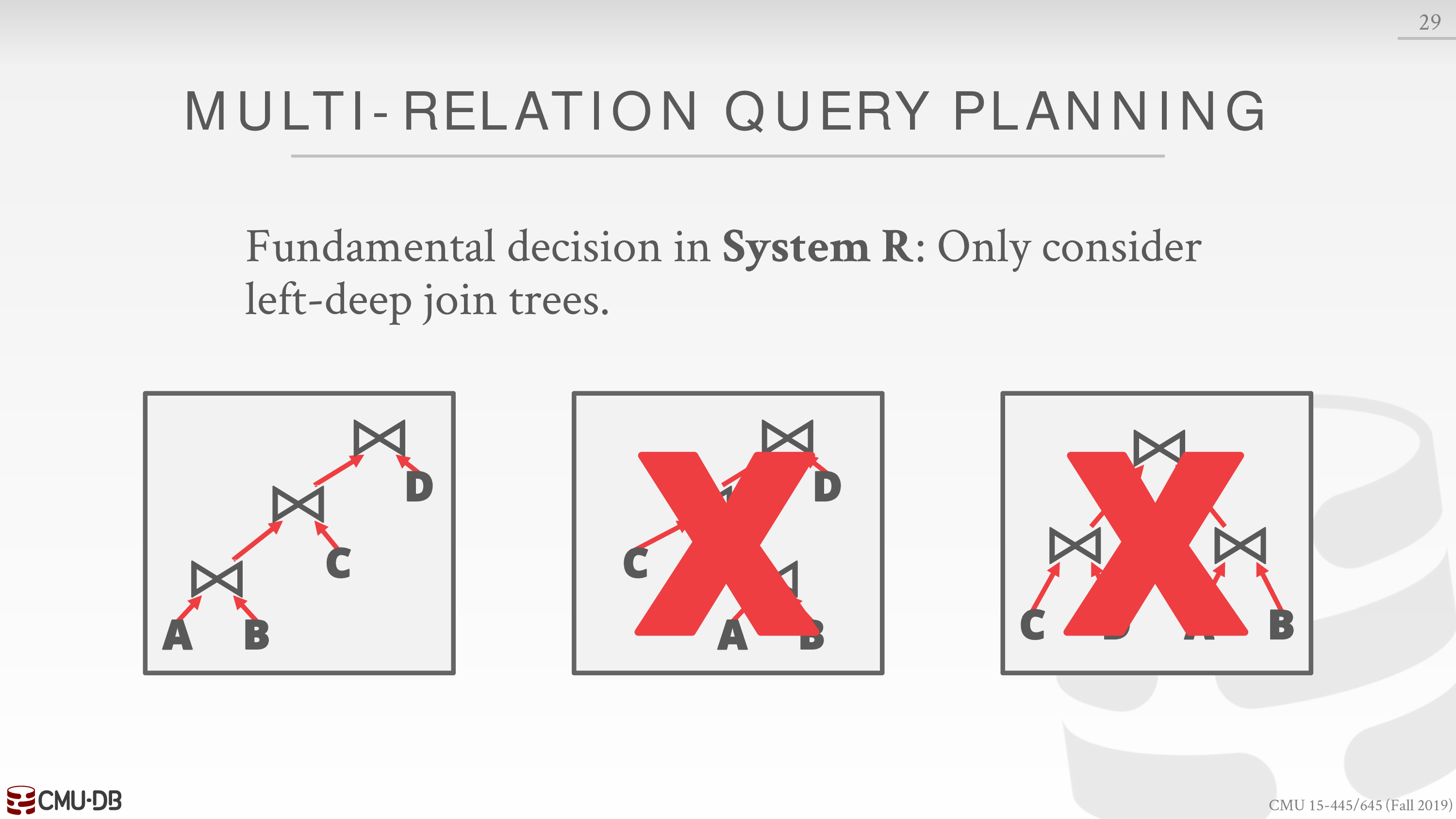
第三种便是 Bushy
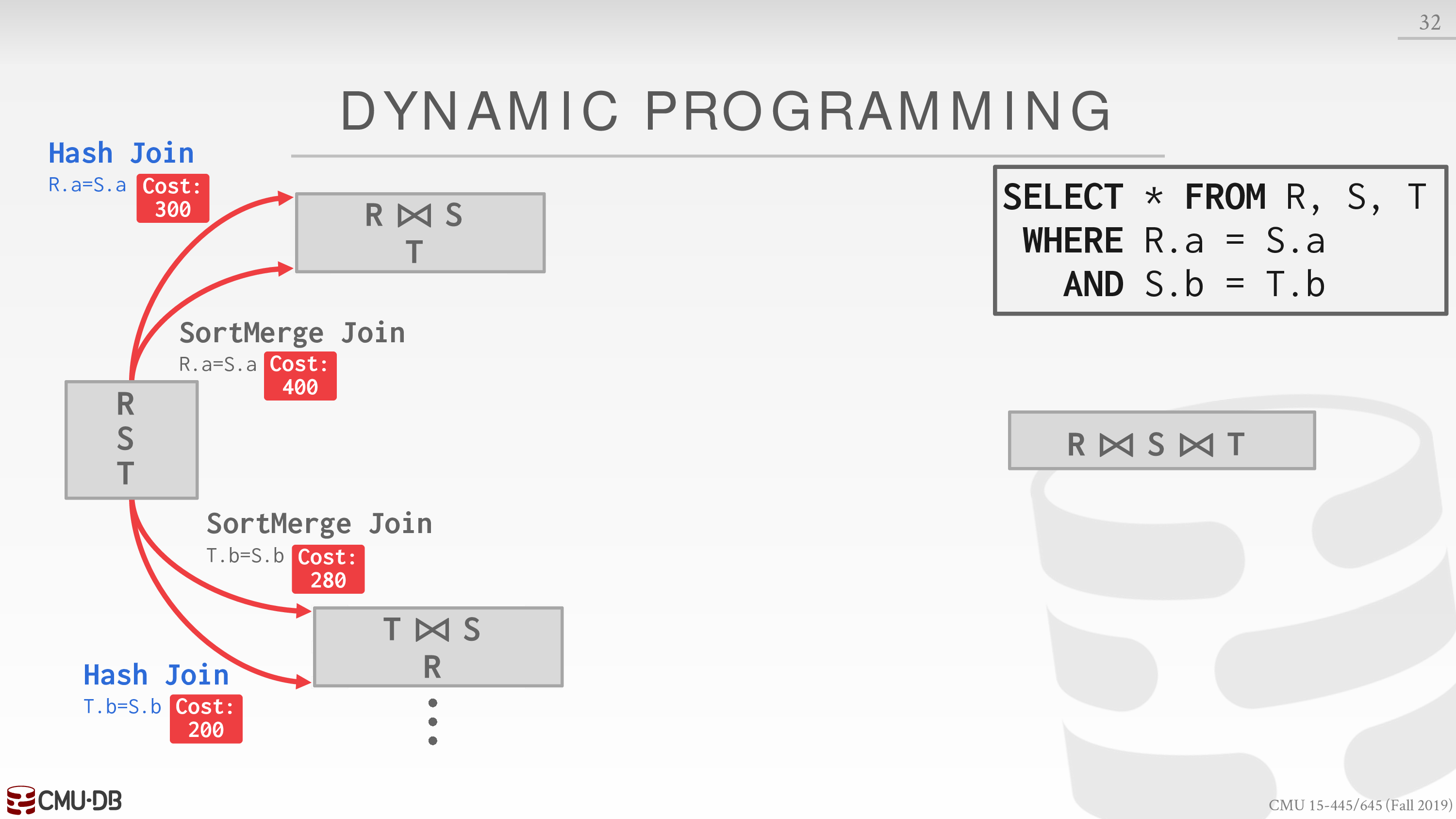
考虑如下的请求
SELECT * FROM R, S, TWHERE R.a = S.aAND S.b = T.b我们先考虑使用某种 join 算法 join 两个表的成本
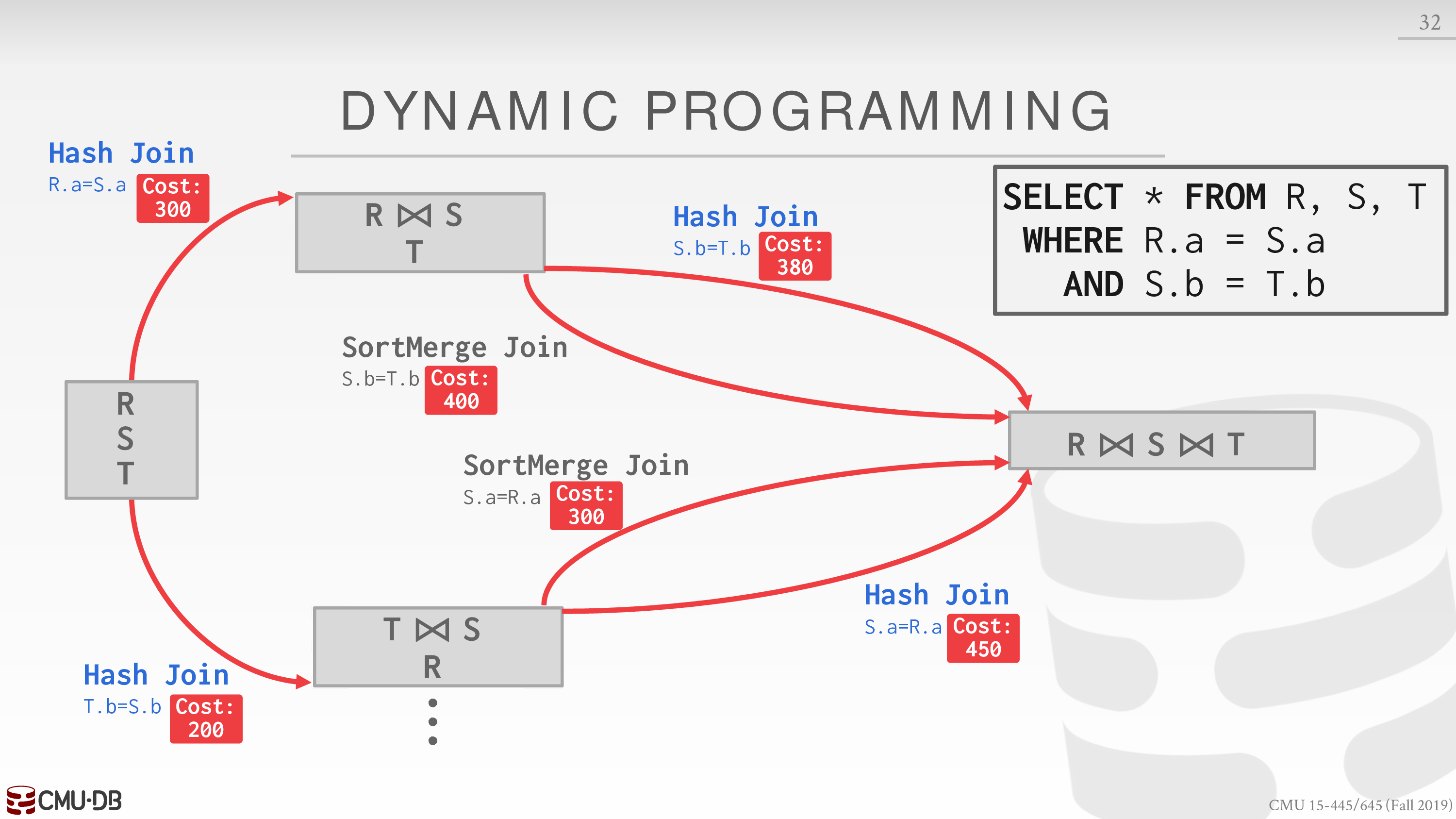
选择每种顺序中成本较低的 join 算法,再考虑 join 另一个表的成本
再选择每种顺序中成本较低的 join 算法
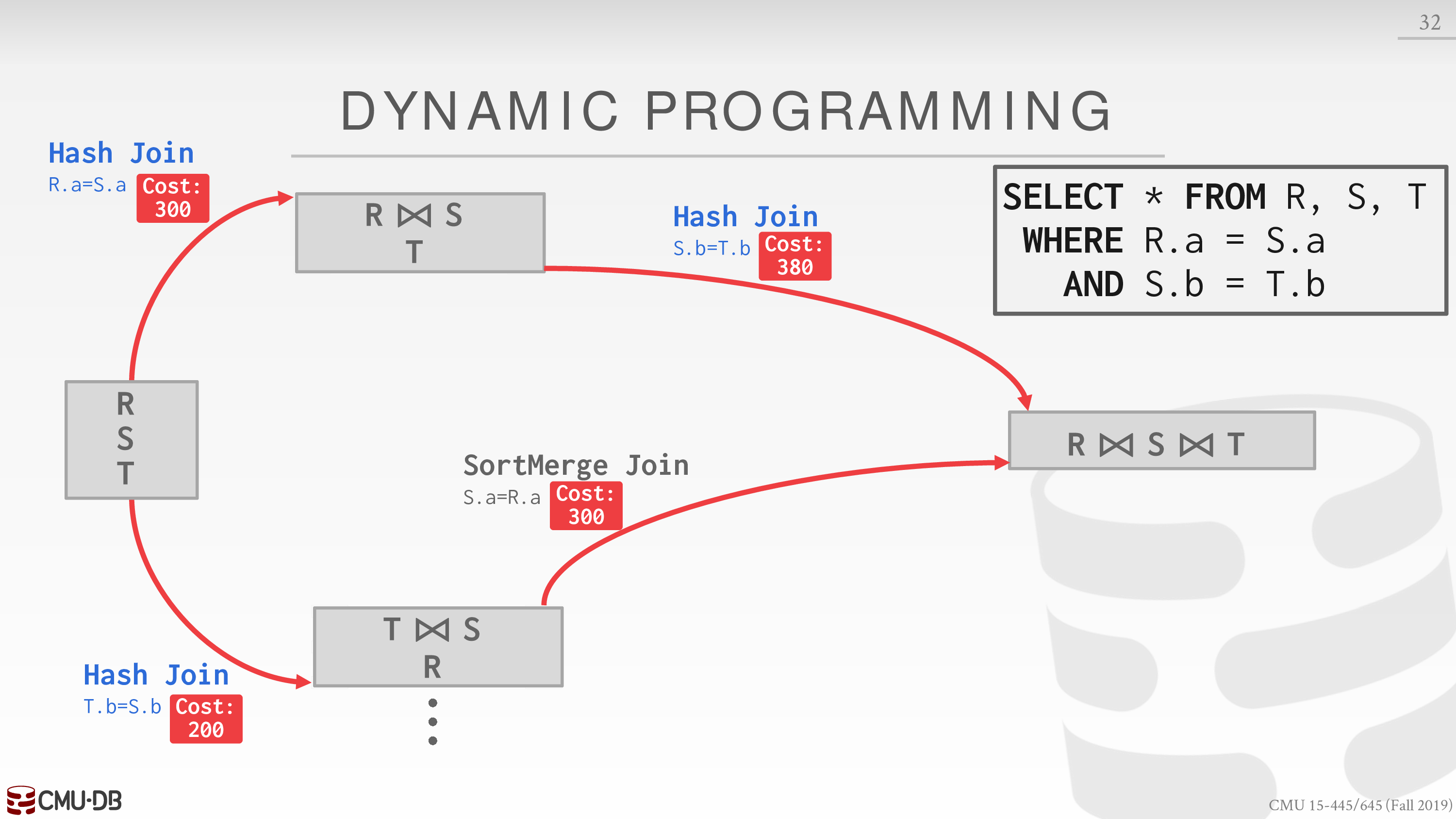
最终选择综合成本最低的方案
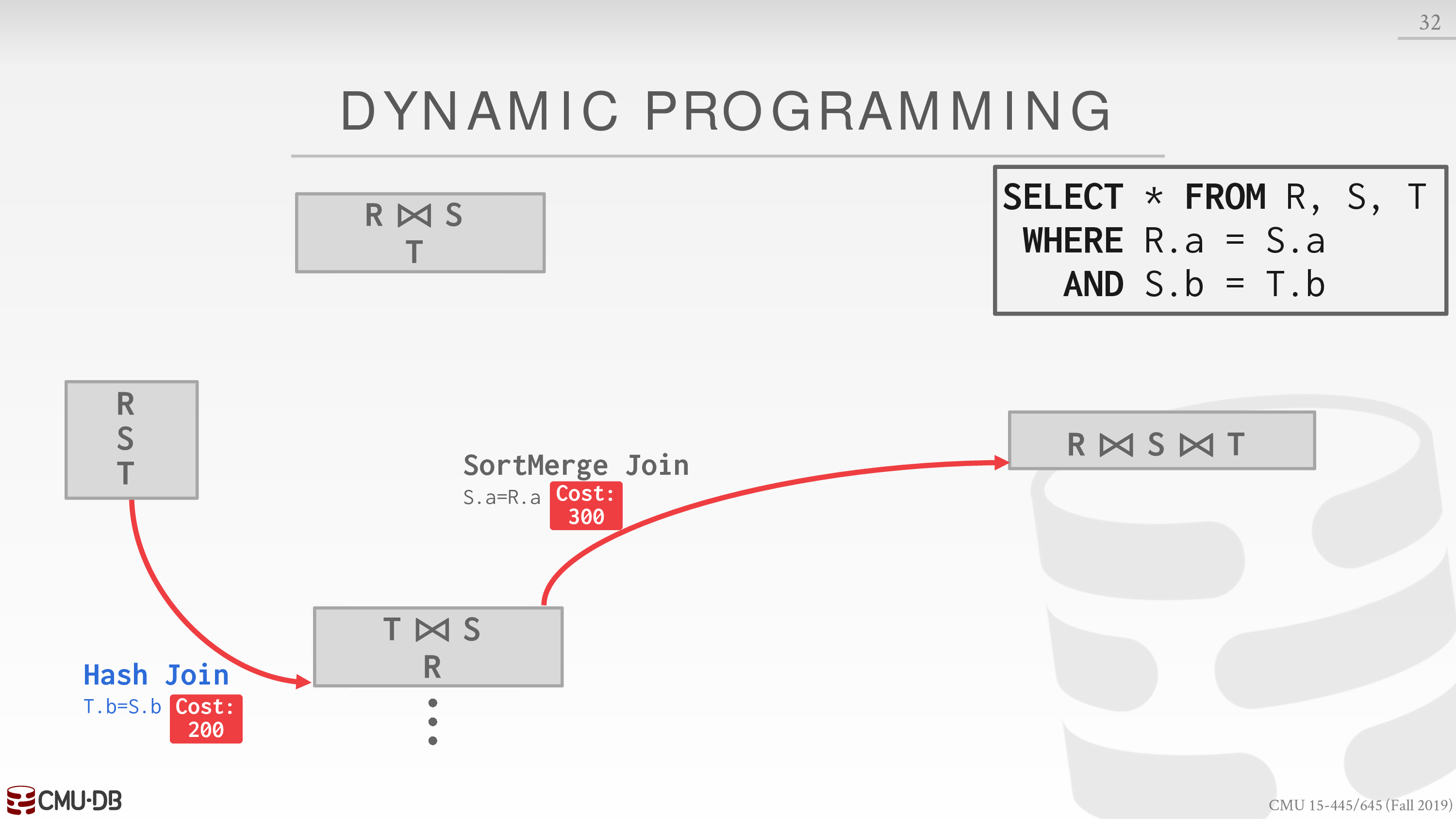
接着再考虑 access method 和 predicate evaluation ordering
- Genetic Query Optimizer (GEQO)
若 join 的表太多,上面的搜索空间仍然很大
Postgres 采用了遗传算法
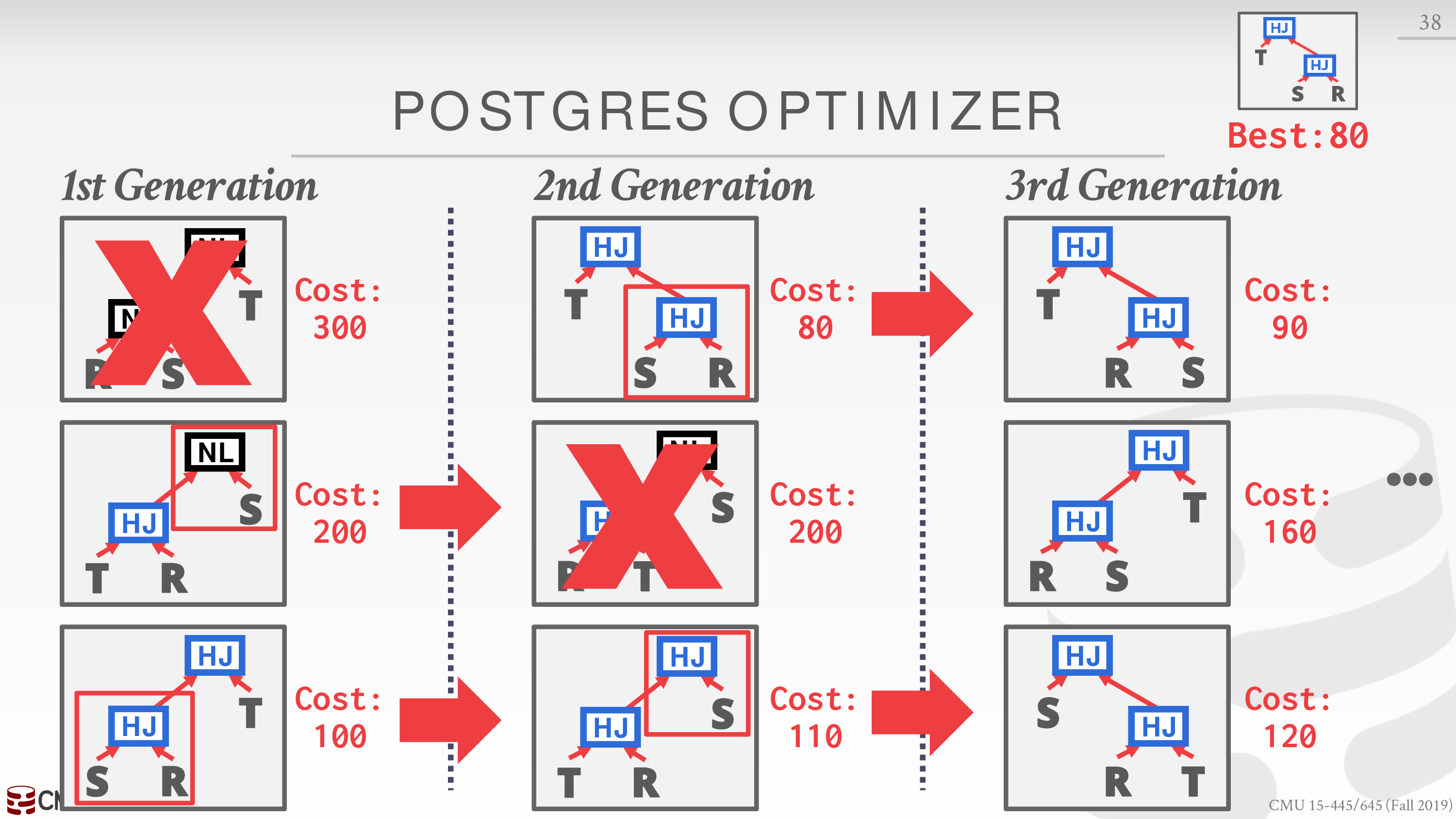
组合成本较低的查询方案
Nested Sub-queries
重写或者分解
- Rewrite to de-correlate and/or flatten them
- Decompose nested query and store result to temporary table
具体的例子见课件
Lecture #16 - Concurrency Control Theory
为了实现一个数据库,我们需要考虑并发控制和恢复
回顾一下层次关系,这两个组件的层次应位于
- Concurrency Control
- Operator Execution
- Access Methods
- Recovery
- Buffer Pool Manager
- Disk Manager
下面是这样考虑的动机

首先我们考虑并发控制,对于关系型数据库而言,基于事务的 ACID 是评判其实现正确性的准则
但对于 NoSQL 或者分布式数据库,就是另一回事了
Transactions
下面给出事务的定义
事务就是一系列的操作,比如 SQL 请求
对于 DBMS 而言,事务具有原子性,即不存在完成了部分事务
比如从我的账户中转账 100 元到另一个账户就是一个事务
当我们需要交错的执行一系列事务时,就需要考虑并发控制
若不考虑,就可能出现数据的不一致性
当然我们没有必要保证临时数据的不一致性,只要在逻辑上看起来数据一致即可
在这一节,我们考虑事务只会读写数据库中的数据,即数据库中的数据集合大小是不变的
由此,我们可以形式化的定义数据库和事务
数据库,一系列的 database object
事务,对 database object 的读或写
在 SQL 中,事务的定义如下
A new txn starts with the BEGIN command.
The txn stops with either COMMIT or ABORT.
也就是说,事务可能被应用程序 abort,也可能被 DBMS abort
ACID
- Atomicity: all or nothing
- Consistency: it looks correct to me
- Isolation: as if alone
- Durability: survive failures
Atomicity
原子性对应了事务不可能会被部分执行
考虑转账的两种可能情形
- DBMS 在执行中 abort 该事务
- DBMS 在执行中 crash 了
为了能够恢复执行前数据库的状态,有两种方法
Logging
DBMS 记录执行事务的日志
保存日志在内存或磁盘中
出现第一种情形时,DBMS 可以直接从内存中恢复数据库的状态
出现第二种情形时,需要分类讨论
- 修改没有写回到磁盘中,当重启 DBMS 时,磁盘中还是原来的状态
- 修改写回到了磁盘中,只要我们在写回磁盘前将日志保存在磁盘中,就可以在重启时恢复原来的状态
因为日志是线性的增长,所以在 IO 性能方面也很好,可以分批写回磁盘
Shadow Paging
DBMS 对修改的 page 创建一个副本,只有事务成功执行完后,才会将指针指向新的 page
相较而言,这种方法性能较差,很少被使用
Consistency
分为两个方面,即数据库一致性和事务一致性
Database Consistency
主要是完整性约束
对于分布式数据库而言更重要一些
Transaction Consistency
数据库执行前一致 + 事务一致 → 数据库执行后一致
对于事务一致而言,是应用程序的责任,DBMS 无法保证
比如应用程序要求选课的人才有数据库系统的账号,但是 DBMS 无法访问选课名单
Isolation
隔离性可以让编写请求代码更加容易,不必考虑并发的情形
为了实现隔离性,我们需要设计并发控制协议,有两种类型
- Pessimistic: Don’t let problems arise in the first place.
- Optimistic: Assume conflicts are rare, deal with them after they happen.
这两种协议在后面的课中会讲
Schedule
下面我们考虑一些基本的内容
为了提高性能,我们需要交错的执行一系列事务
这些事务的排列被称为 schedule
当事务没有交错时,该 schedule 被称为 Serial Schedule
我们需要保证在某种 schedule 下,执行一系列事务后,数据库的所有状态与执行 Serial Schedule 后相同
数据库的状态可能是存款总额
不同的粒度决定了交错的灵活性
那么称这种 schedule 为 Serializable Schedule
Conflict
为了实现 Serializable Schedule,我们需要考虑 conflict
以两个事务的交错为例,只要某一个事务中出现了写,那么就可能出现 conflict
注意到我们目前考虑事务只会读写数据库中的数据
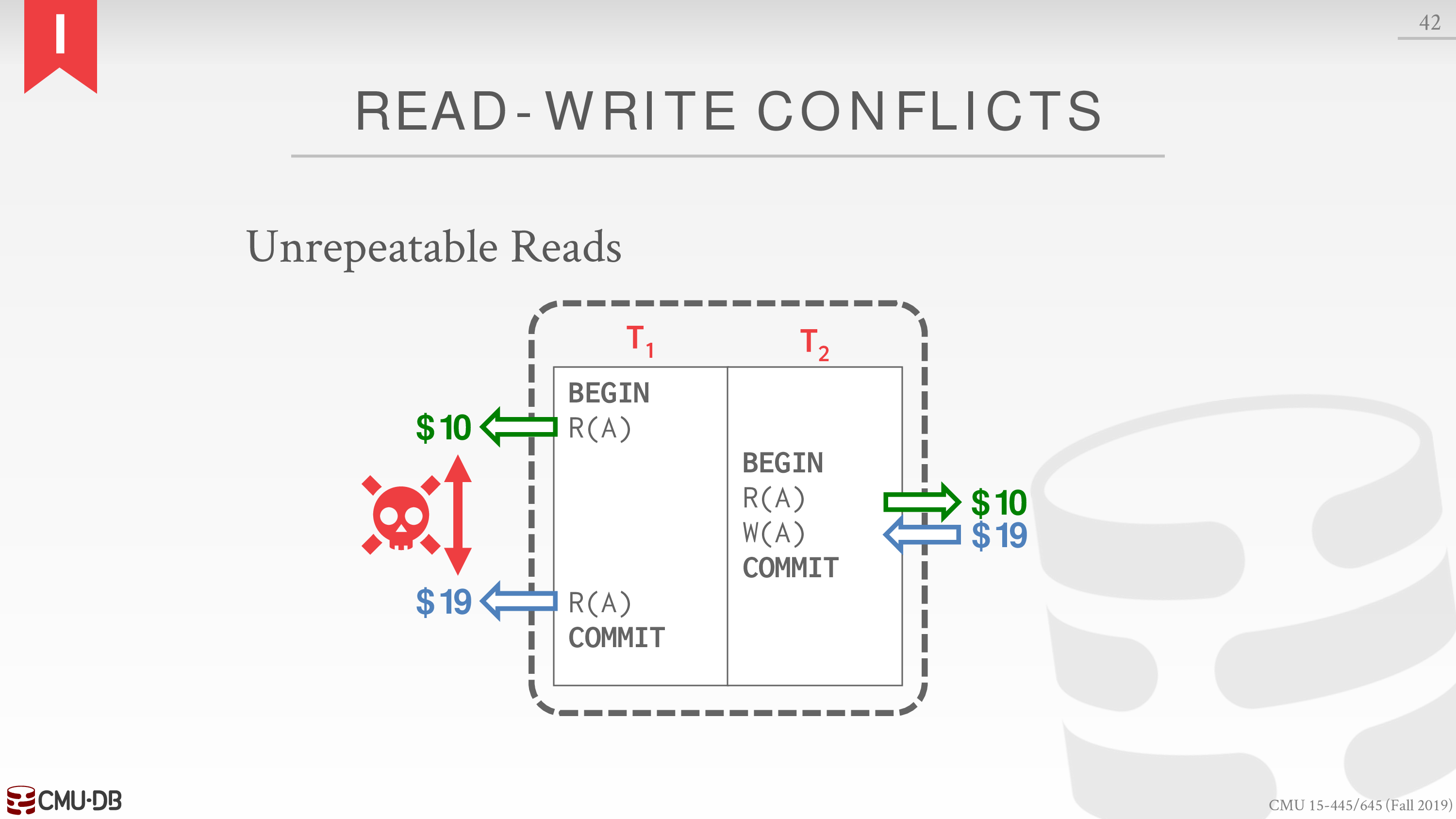
于是 conflict 可以分类为
Read-Write Conflicts (R-W)
Write-Read Conflicts (W-R)
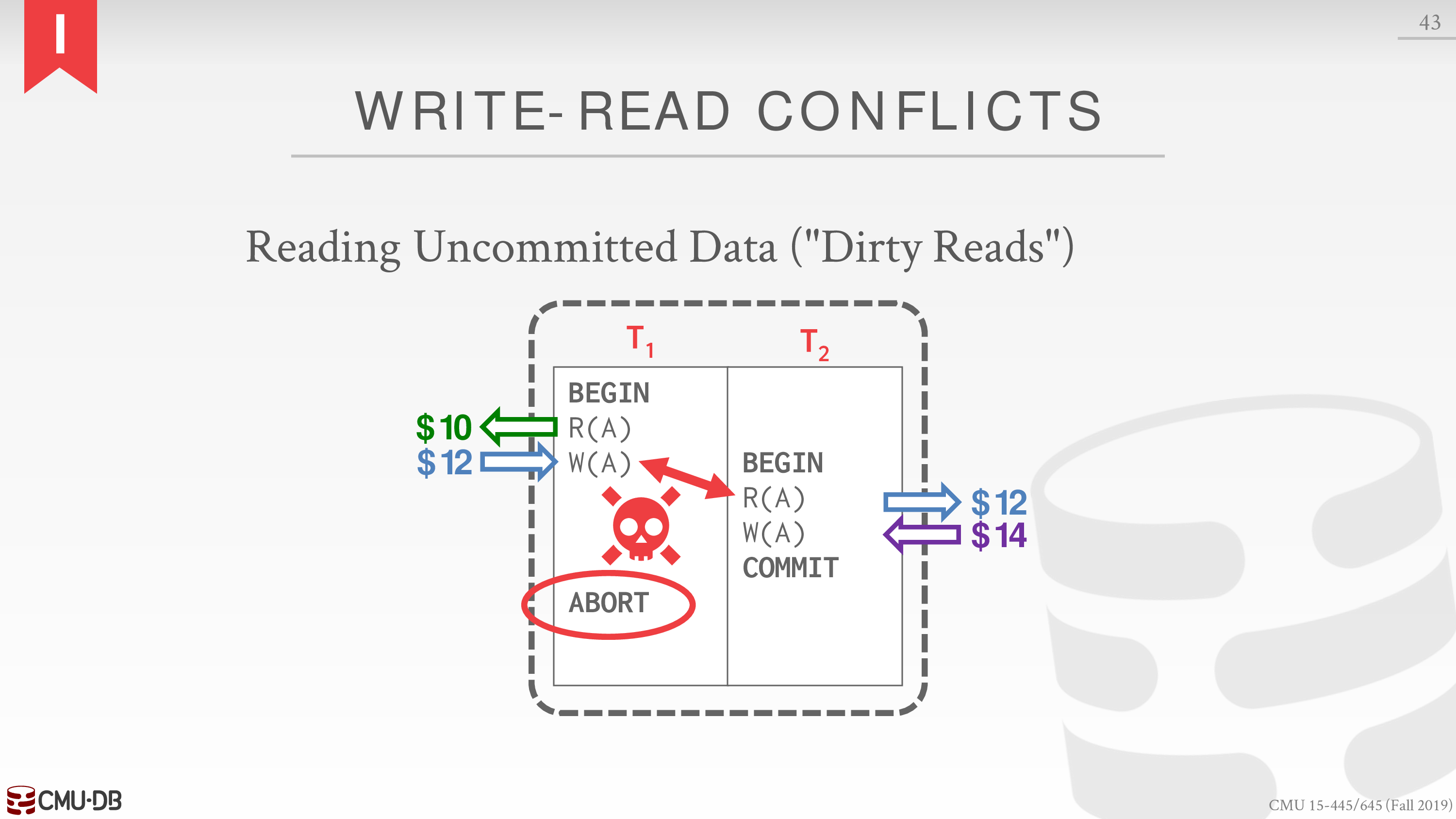
Write-Write Conflicts (W-W)
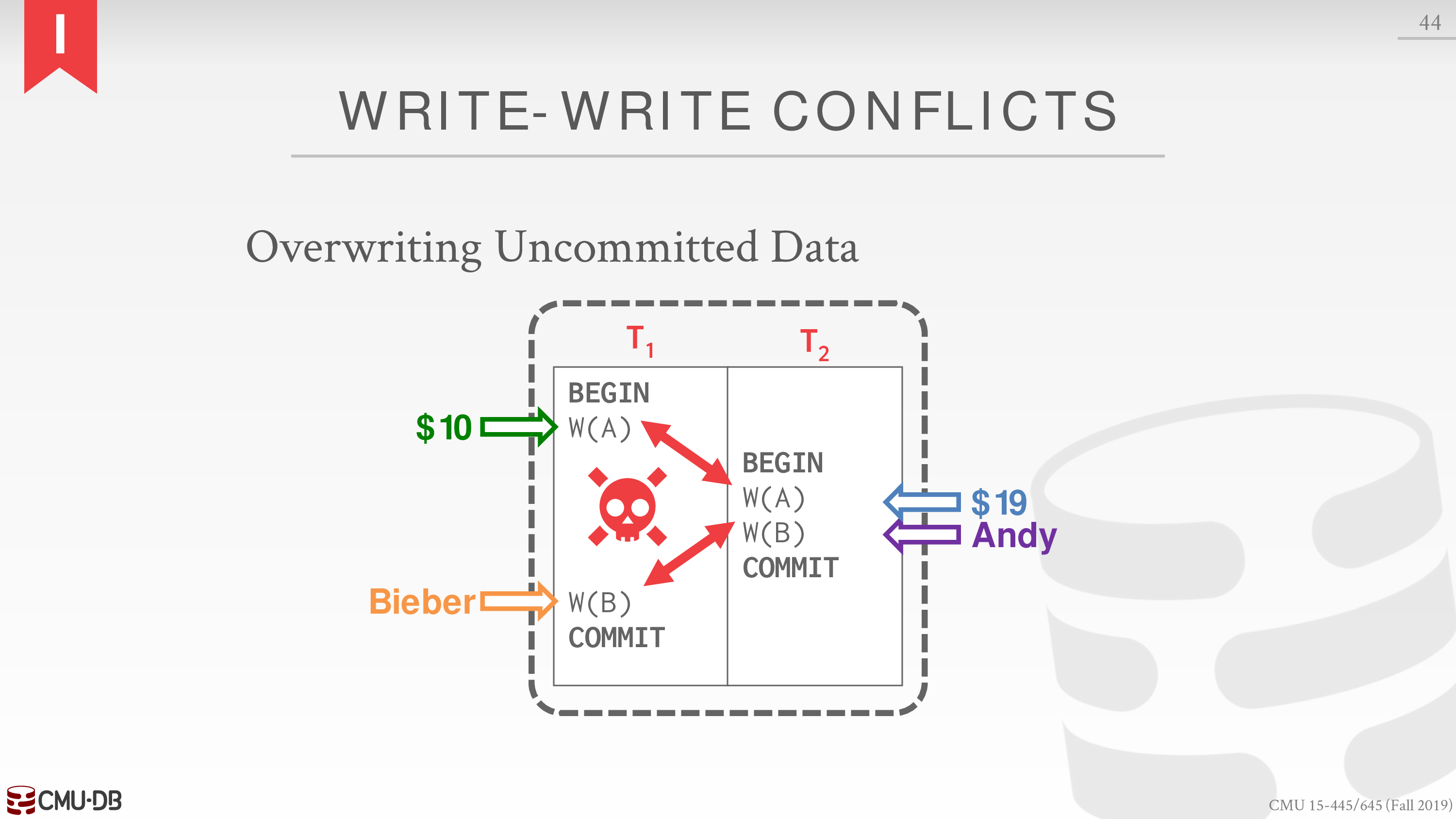
对于 conflict 的判别决定了不同级别的 serializable
意思就是可能某个 schedule 是 serializable 的,但是在判别策略下会被判别为不是 serializable 的
在策略的效率和交错的灵活性之间权衡
主流的 DBMS 都会支持 Conflict Serializable
也就是 every pair of conflicting actions is ordered the same way
通过交换操作执行顺序判别
或者使用 dependency graph / precedence graph 判别
无环则为 conflict serializable
这里有一个例子
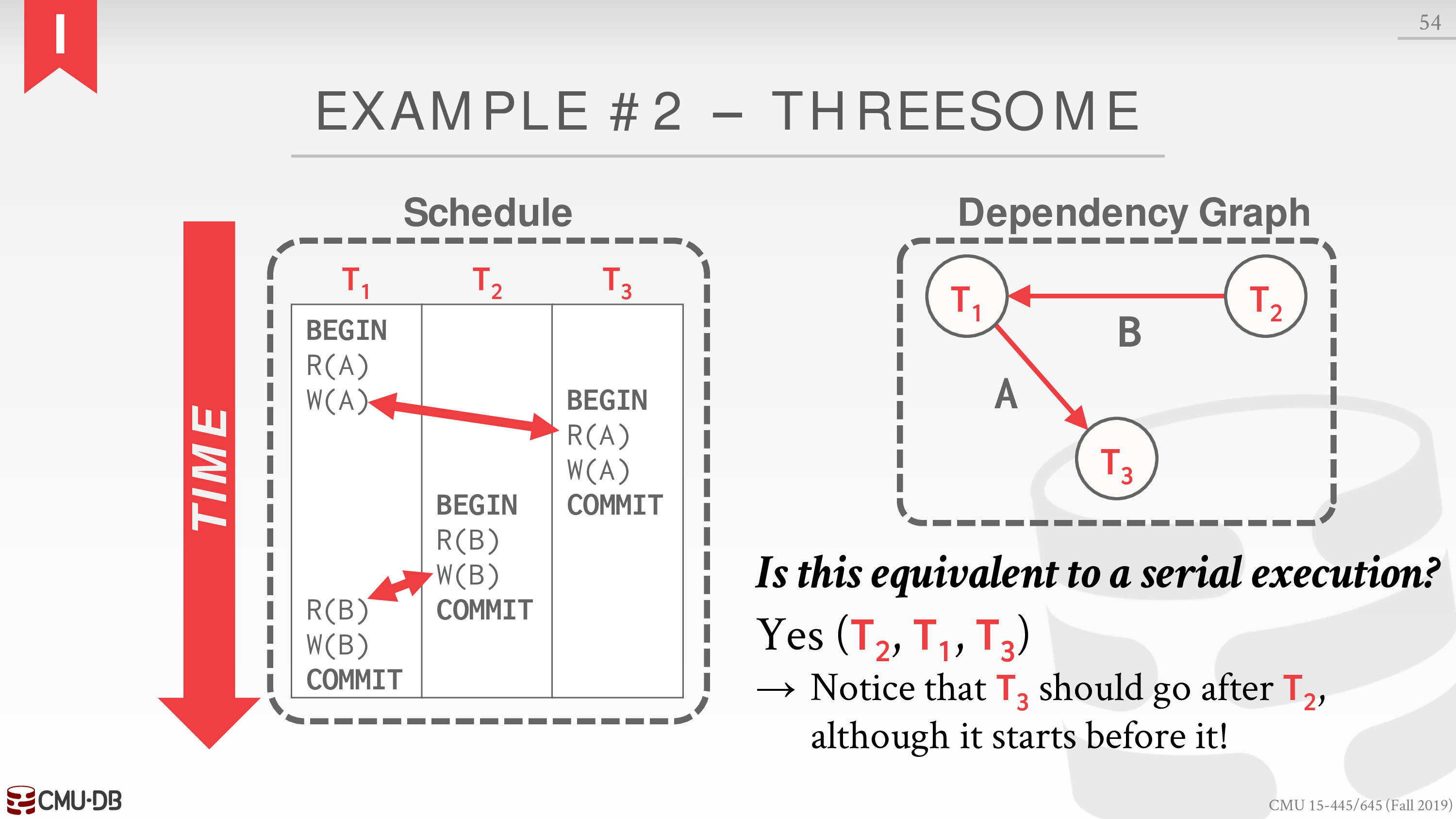
具体内容见课件
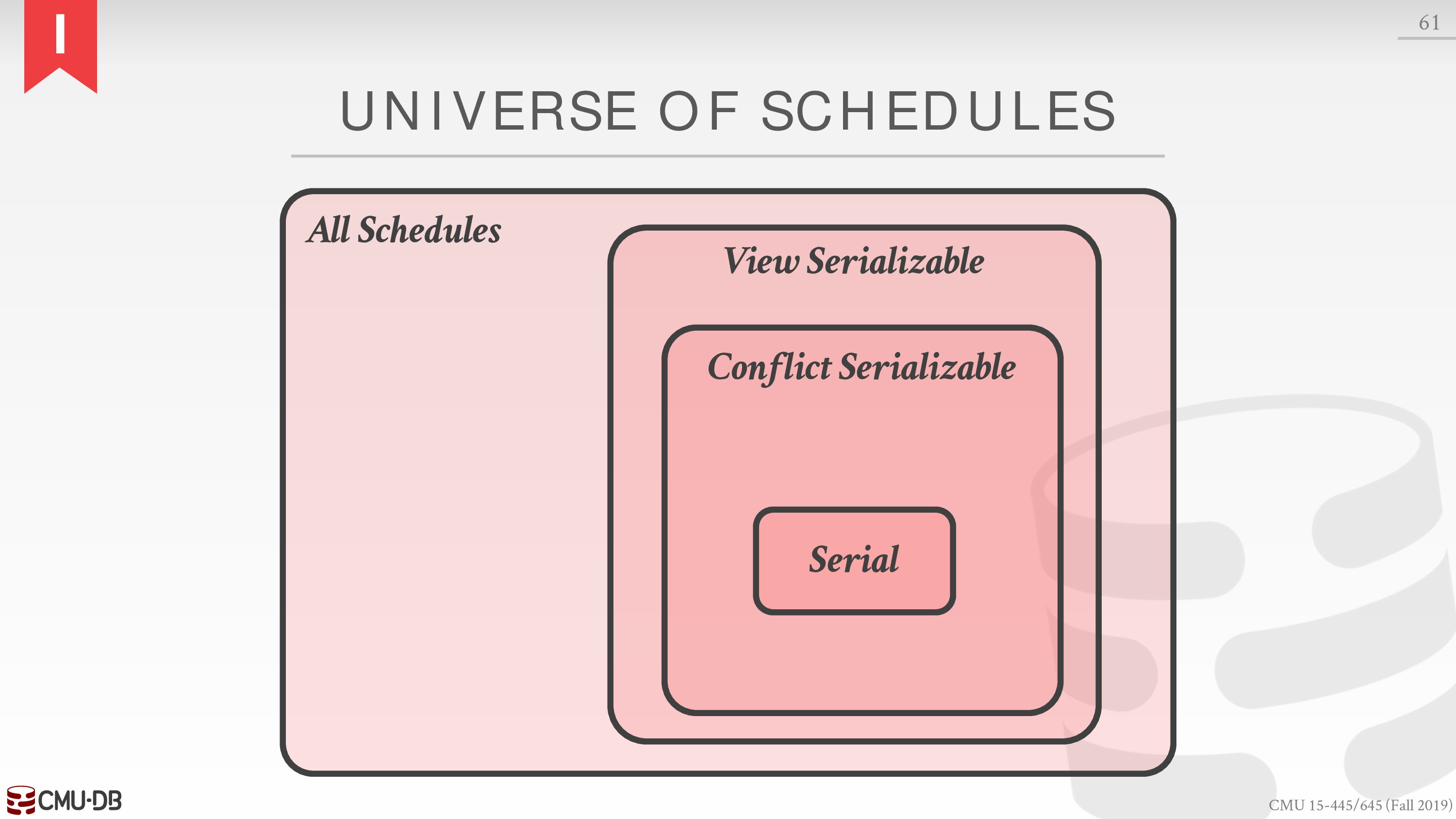
更广义的为 View Serializability
不过需要用户程序提供信息
比如告知 DBMS 多个 write 的实际顺序,这样只要最后一个 write 在 schedule 的最后即可
目前没有 DBMS 能够支持
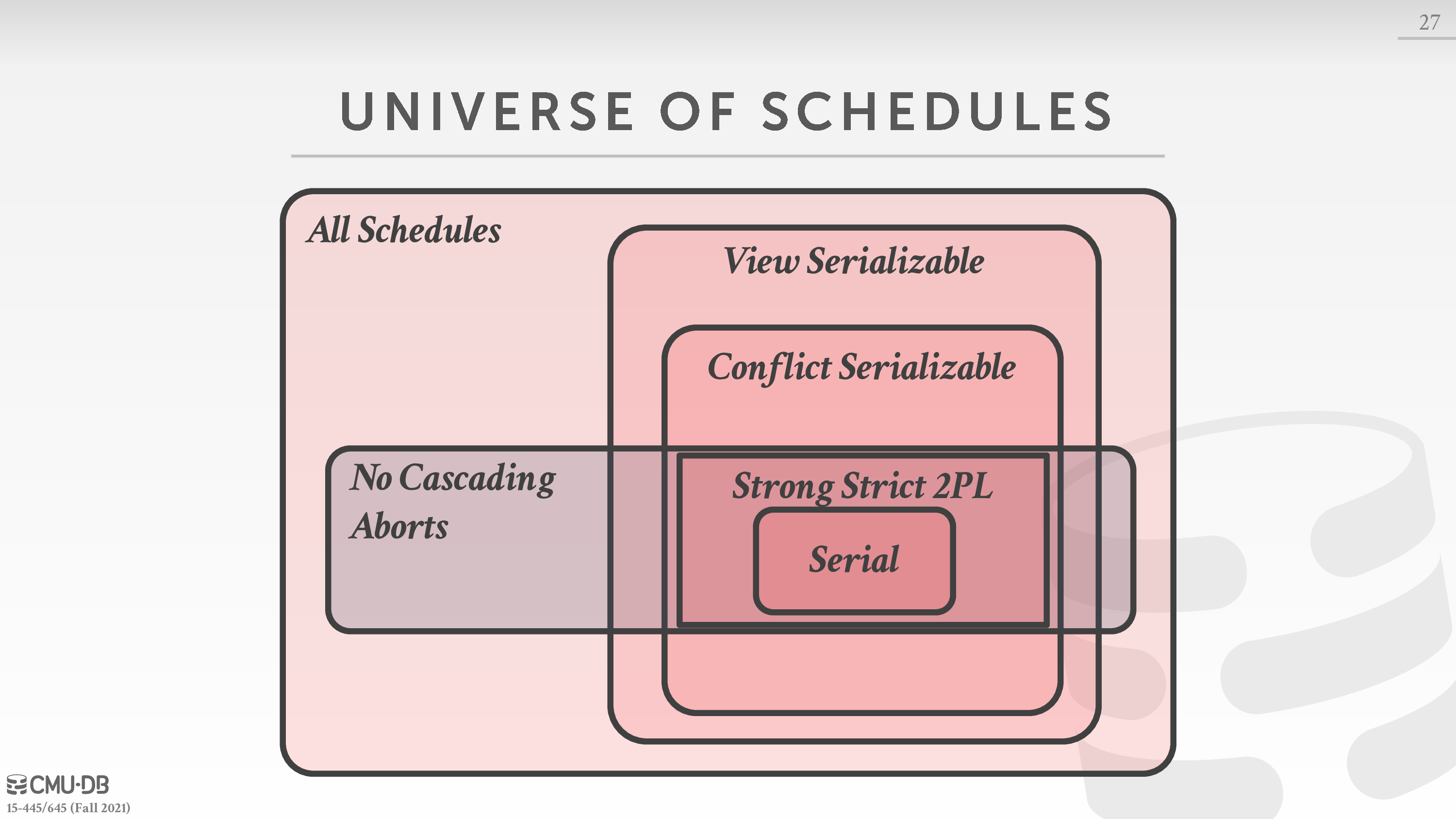
下面给出各种 schedule 的关系
Durability
实现 Atomicity 的两个方法,某种程度上也实现了 Durability
Lecture #17 - Two**-Phase Locking Concurrency Control**
这一节主要内容是:如何通过 Isolation 中悲观的并发控制协议实现事务的交错执行
We need a way to guarantee that all execution schedules are correct (i.e., serializable) without knowing the entire schedule ahead of time.
Solution: Use locks to protect database objects.
Lock

注意 lock 是针对事务而言,保护的是 database object
由于无法提前预知用户程序请求的事务,所以可能会出现死锁情形
lock 类似 latch,有两种类型,shared lock 和 exclusive lock
然而像使用 latch 那样使用 lock,并不能保证 schedule 是 conflict serializable 的,如
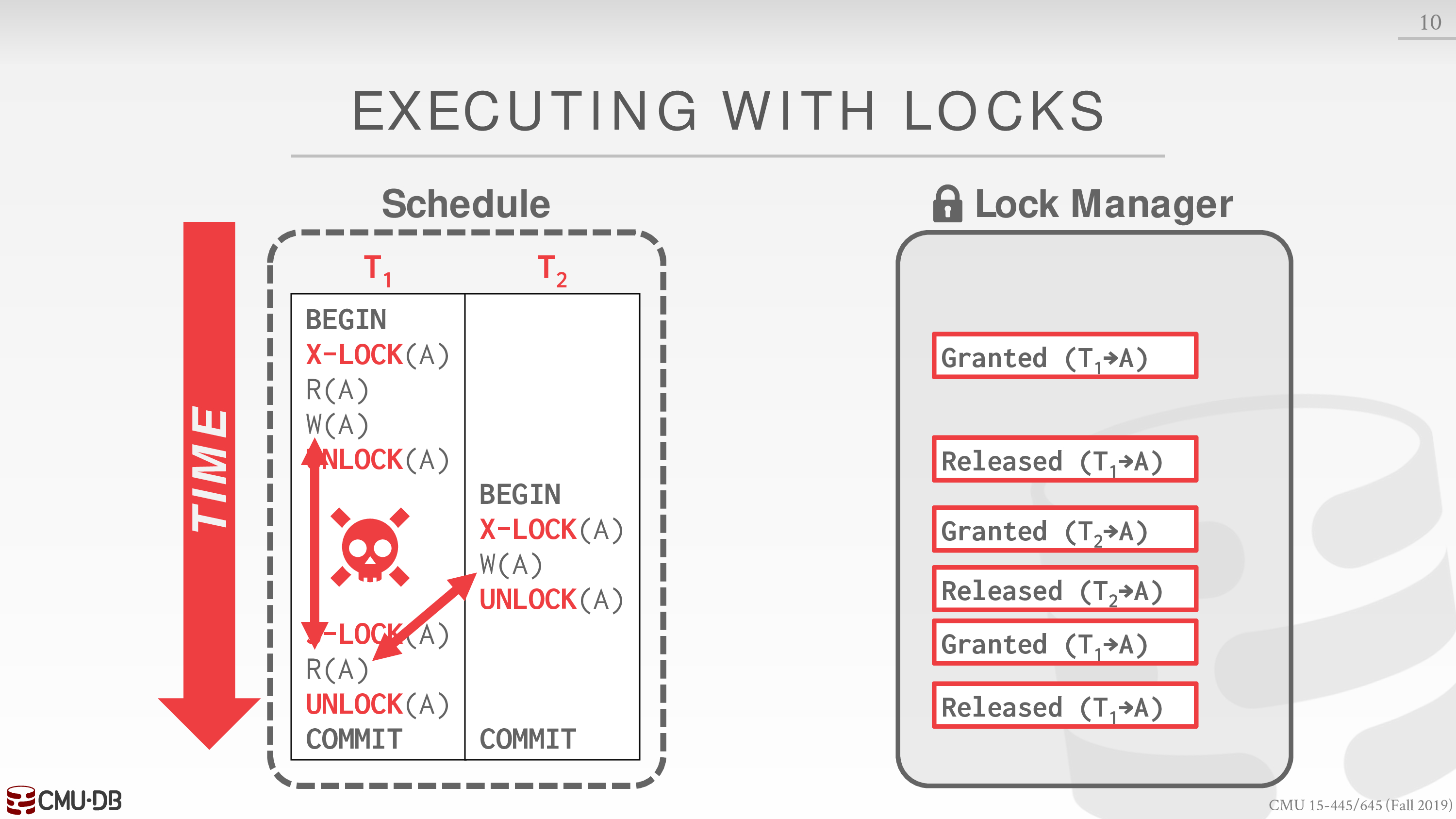
为此我们需要使用 Two-phase locking (2PL)
2PL
- Phase #1: Growing
- Phase #2: Shrinking
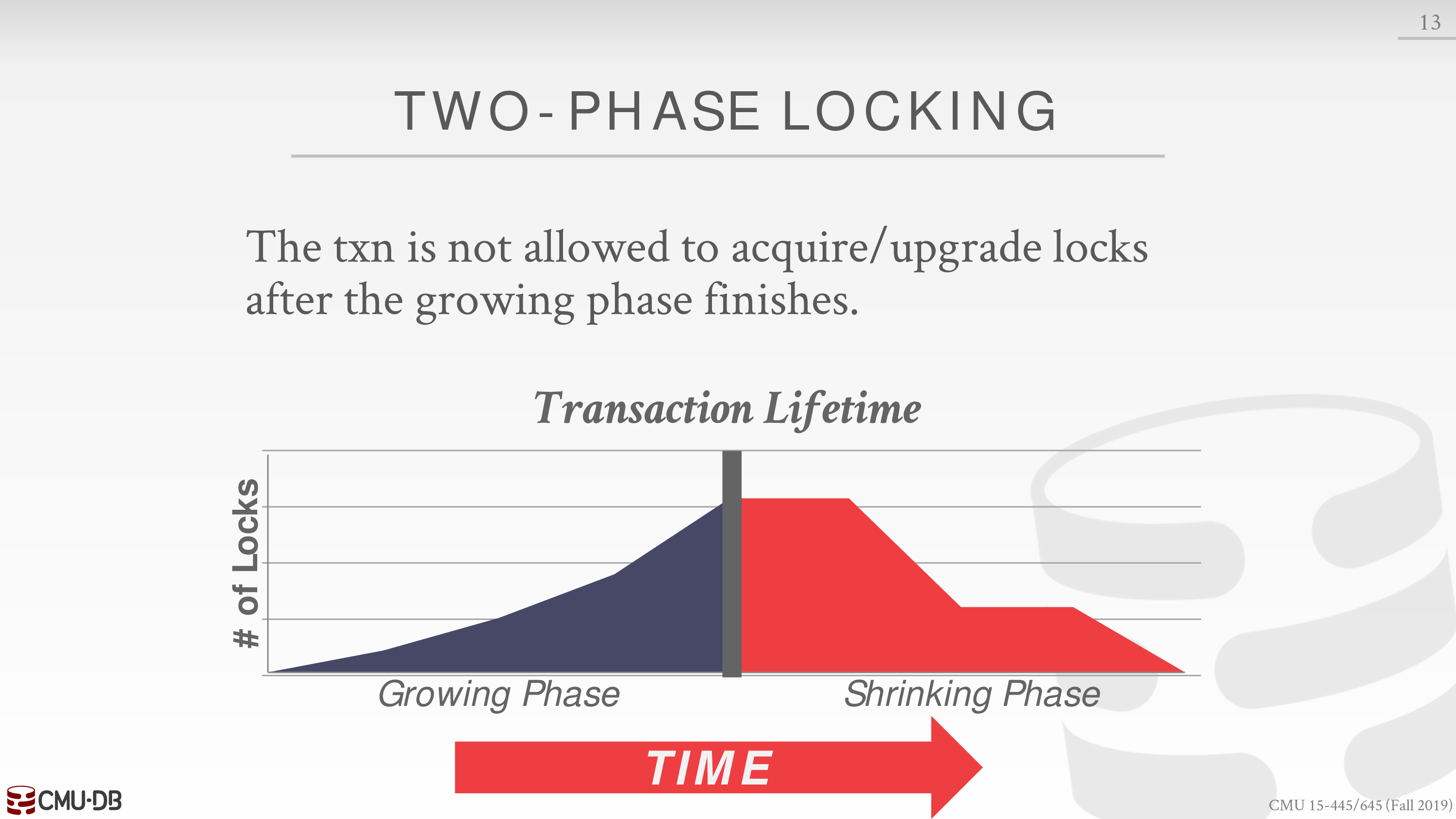
在阶段一后,事务就不能再获得 lock 了
在大多数情形下,使用这种方法能够保证 schedule 是 conflict serializable 的
等价于对应的 dependency graph 是无环的
但对于有些 serializable 的 schedule 而言,并不被 2PL 所允许
比如下面这个例子中涉及了 abort
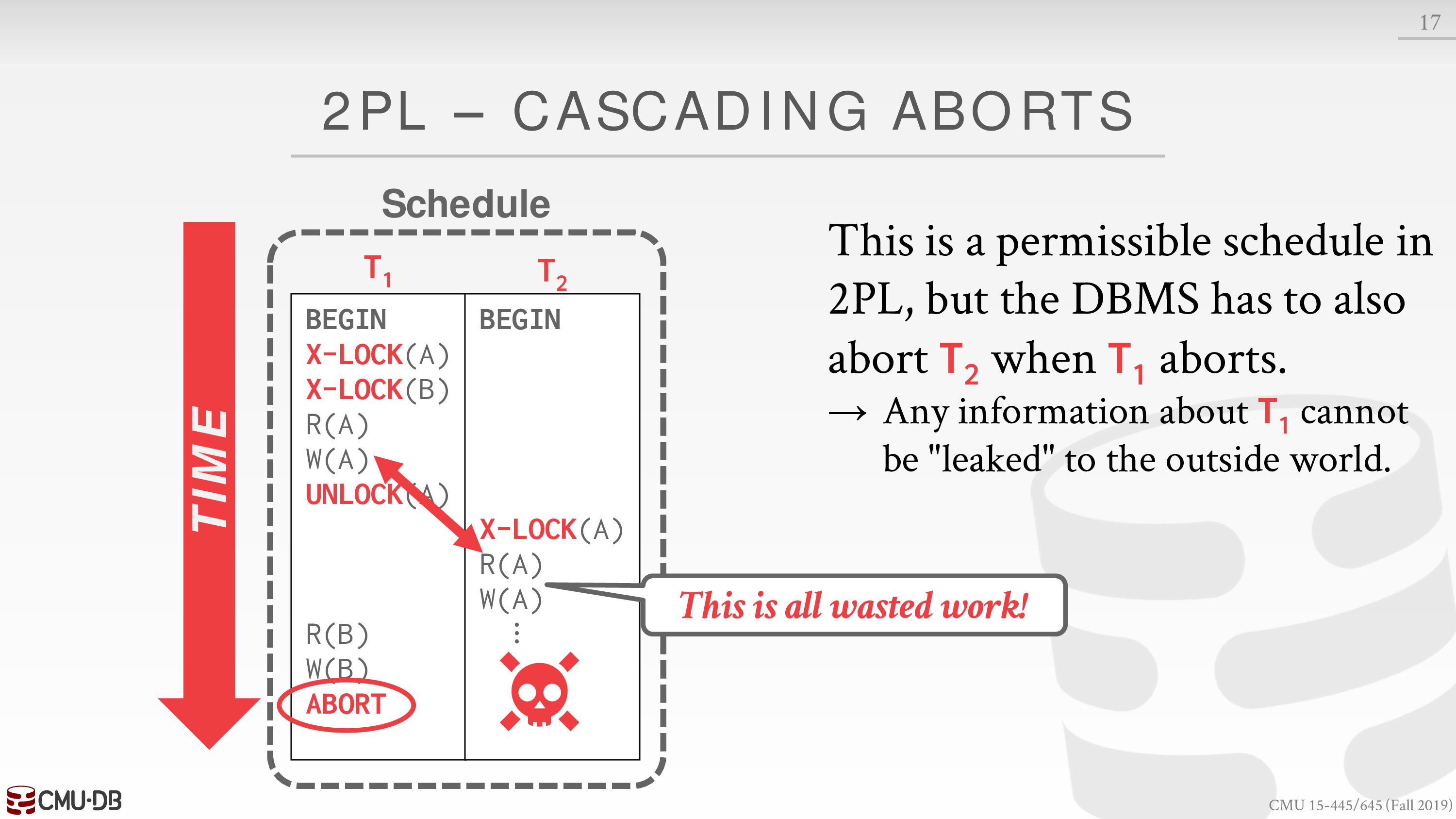
会导致事务连锁的 abort
因为这里事务 T2 读到了 T1 未提交的数据,所以 T2 也需要 abort
如果 T1 没有 abort,这里就没有问题,2PL 仍然可以保证对应的 schedule 是 conflict serializable 的
这被称为 Cascading Aborts
为此我们需要使用 Strong Strict 2PL (aka Rigorous 2PL)
对于 2PL 的总结
- 限制了一些 serializable 的 schedule
- 可能出现脏读,即一个事务读取了另一个事务还未提交后的修改
- 可能出现死锁
Rigorous 2PL
类似 2PL,只不过所有的 locks 在事务提交后才释放
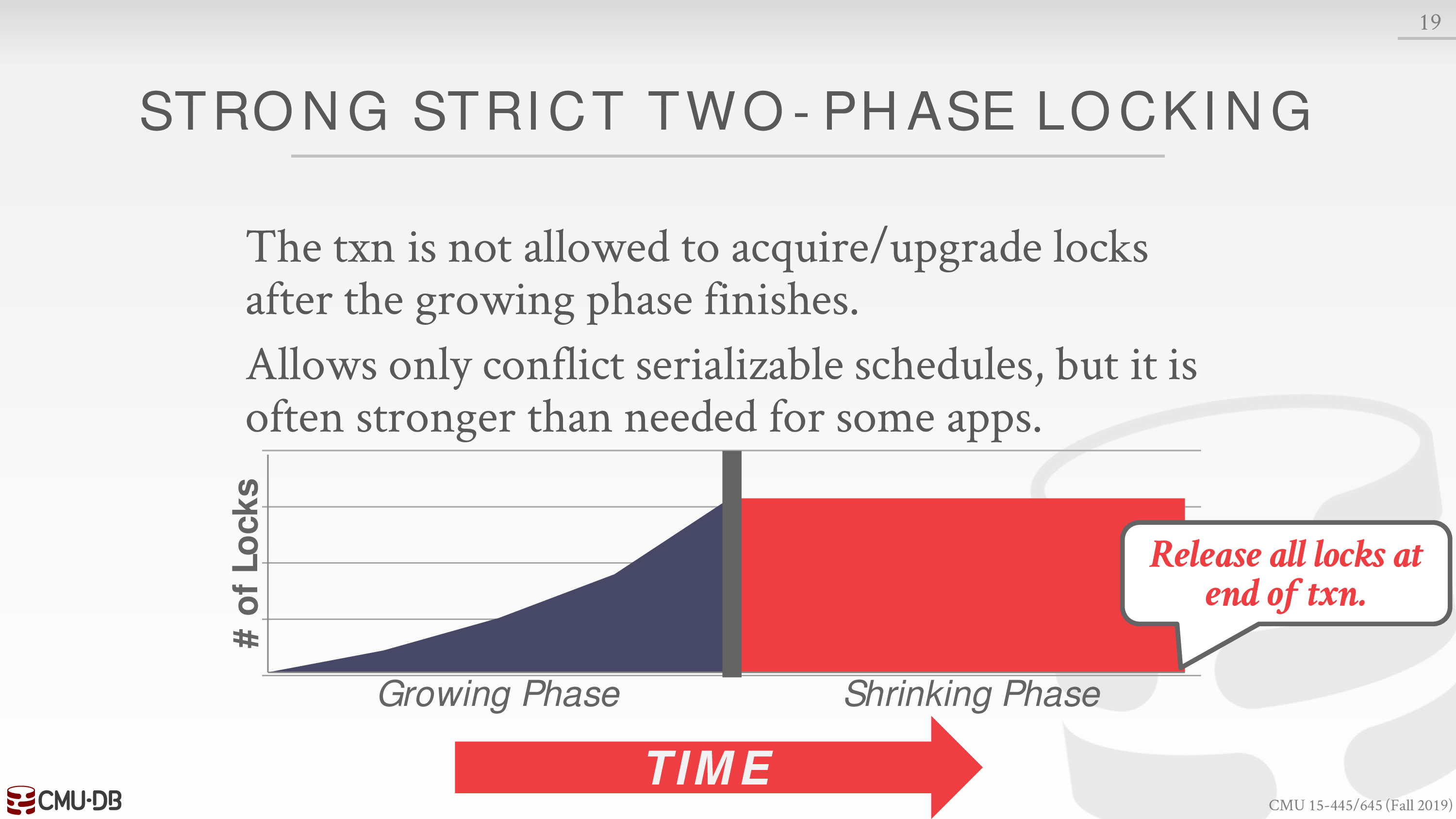
A schedule is strict if a value written by a txn is not read or overwritten by other txns until that txn finishes.
这就保证了不会出现连锁的 abort
并且,事务只需要存储 database object 原来的值即可,不需要考虑连锁的情形
我们需要更新一下各种 schedule 的关系
Deadlock
之前提到,由于无法提前预知用户程序请求的事务,所以可能会出现死锁情形
有两种方法解决死锁情形
Deadlock Detection
消极的策略
创建一个后台线程进行死锁检测
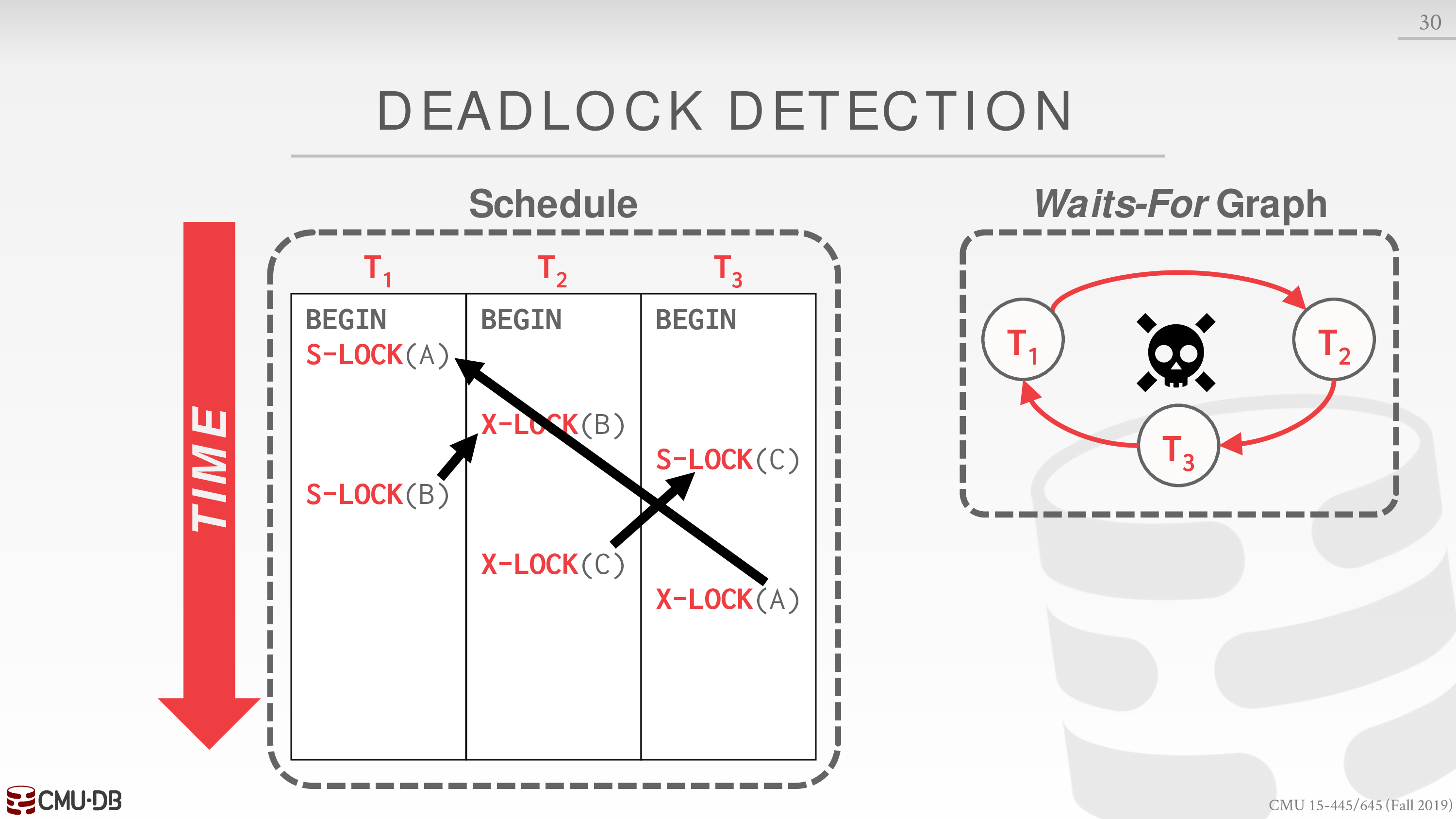
为 schedule 构建 waits-for 图
这里需要考虑死锁检测的频率
- 根据 workload 或其他因素
- 这决定了死锁可能持续的时间
一旦出现环,DBMS 就需要考虑如何解决死锁
Deadlock Handling
这里有一些权衡的因素
- 出现死锁时如何选取 victim
- 比如根据时间戳,事务进行了多少,获取 lock 的数量,选取后需要连锁回滚的事务数量
- 这里不一定使用 Rigorous 2PL,所以可能出现 Cascading Aborts
- 还需要考虑饥饿问题
- 综合各种因素启发式搜索
- 选取 victim 后回滚的长度
- 完全回滚
- 部分回滚,直至解决了死锁
Deadlock Prevention
避免死锁就需要保证 lock 分发的顺序是一致的 (避免循环等待)
一个简单的想法是为每个事务根据时间戳分配一个优先级
事务开始的时间
在出现 lock 的竞争时,根据某种策略分发 lock
Assign priorities based on timestamps: Older Timestamp = Higher Priority
- Wait-Die (“Old Waits for Young”)
If requesting txn has higher priority than holding txn, then requesting txn waits for holding txn. Otherwise requesting txn aborts.
- Wound-Wait (“Young Waits for Old”)
If requesting txn has higher priority than holding txn, then holding txn aborts and releases lock. Otherwise requesting txn waits.
下面看一个例子
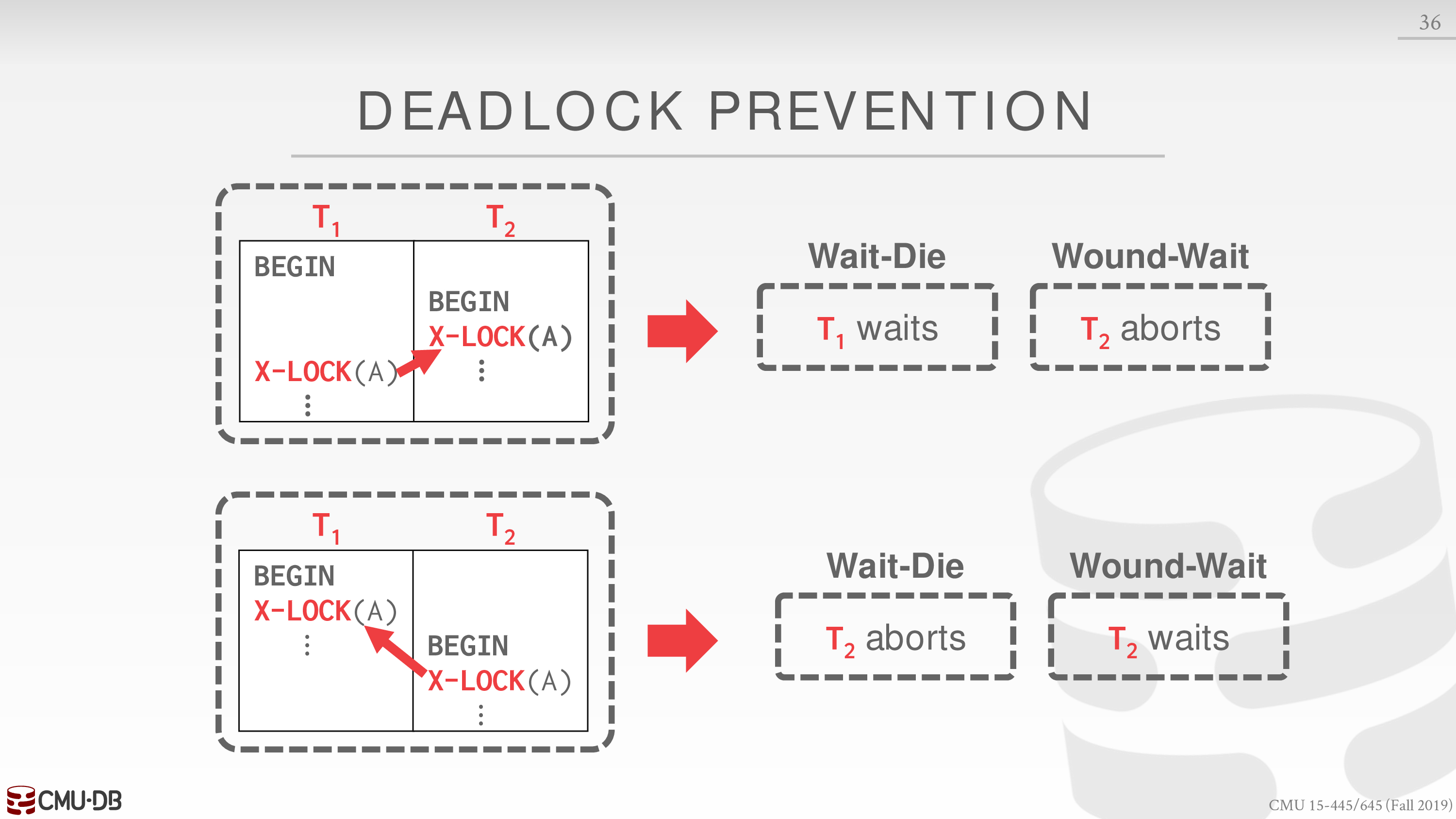
1 优先级比 2 高
第一种情形下
- Wait-Die 中 1 请求 2,1 等待
- Wound-Wait 中 1 请求 2,2 终止
第二种情形下
- Wait-Die 中 2 请求 1,2 终止
- Wound-Wait 中 2 请求 1,2 等待
注意当事务重启时,其优先级仍为原来的优先级,否则可能出现饥饿现象
总结
- Wait-Die 若老索新,老等,否则新死
- Wound-Wait 若老索新,新死,否则新等
Lock Granularities
注意到在之前的例子中,每个 database object 都拥有一个 lock
这样做 lock manager 可能需要维护大量的 lock
对于每个事务而言,应该尽可能拥有较少的 lock
由于 database object 的组织是层次性的,比如 table 中有 tuple,tuple 中有 attr
这就需要将 lock 也层次性组织起来
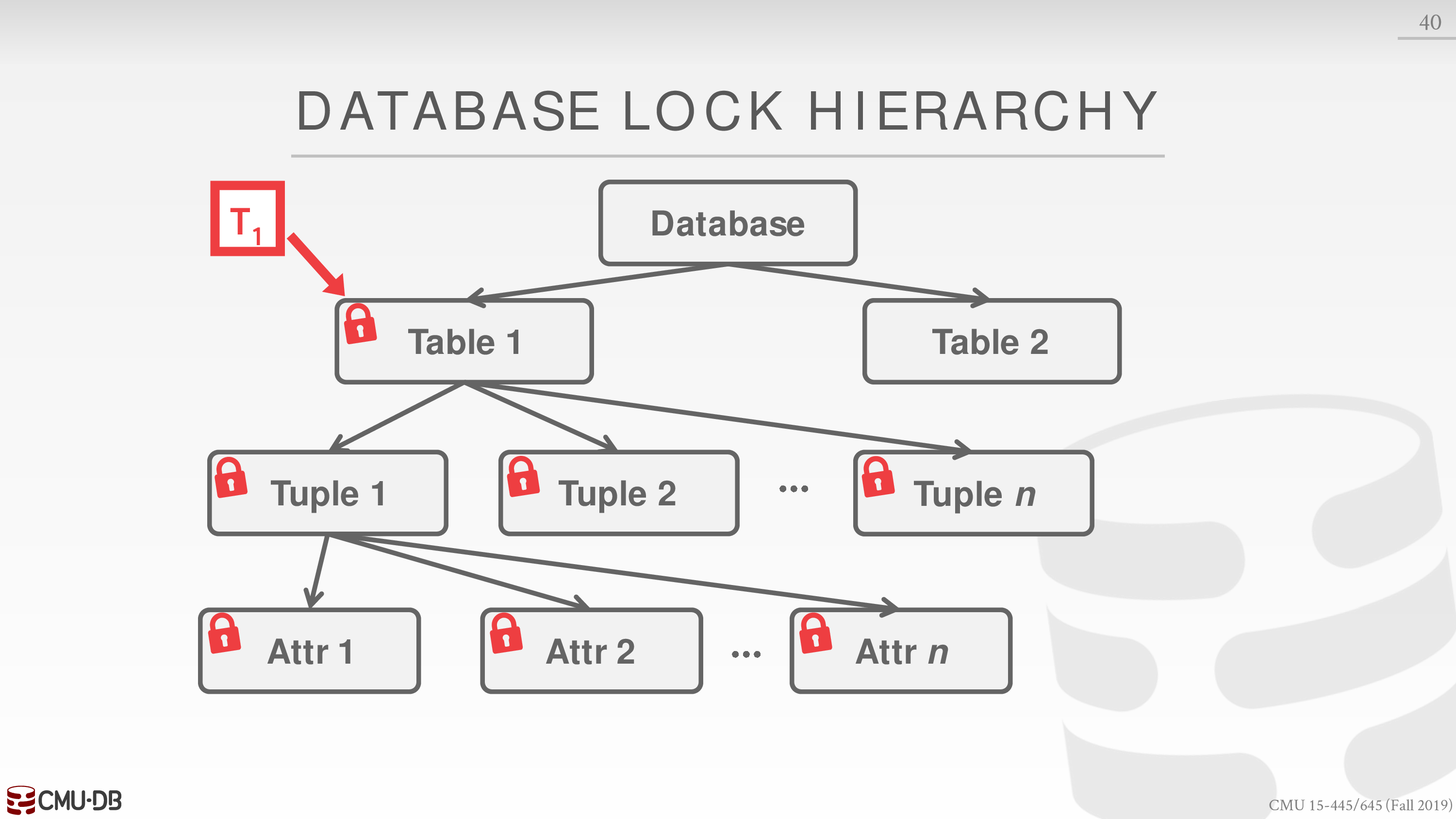
比如事务显式获得了 table1 的 lock,也实际上隐式获得了 table1 里面 tuple 和 attr 的 lock
为了更好的表达这种关系,我们引入 intention lock,分为下面三种
- Intention-Shared (IS)
子节点隐式为 shared locks.
- Intention-Exclusive (IX)
子节点隐式为 exclusive locks.
- Shared+Intention-Exclusive (SIX)
自身显式为 shared lock,子节点隐式为 exclusive locks.
五种 lock 的相容性如下
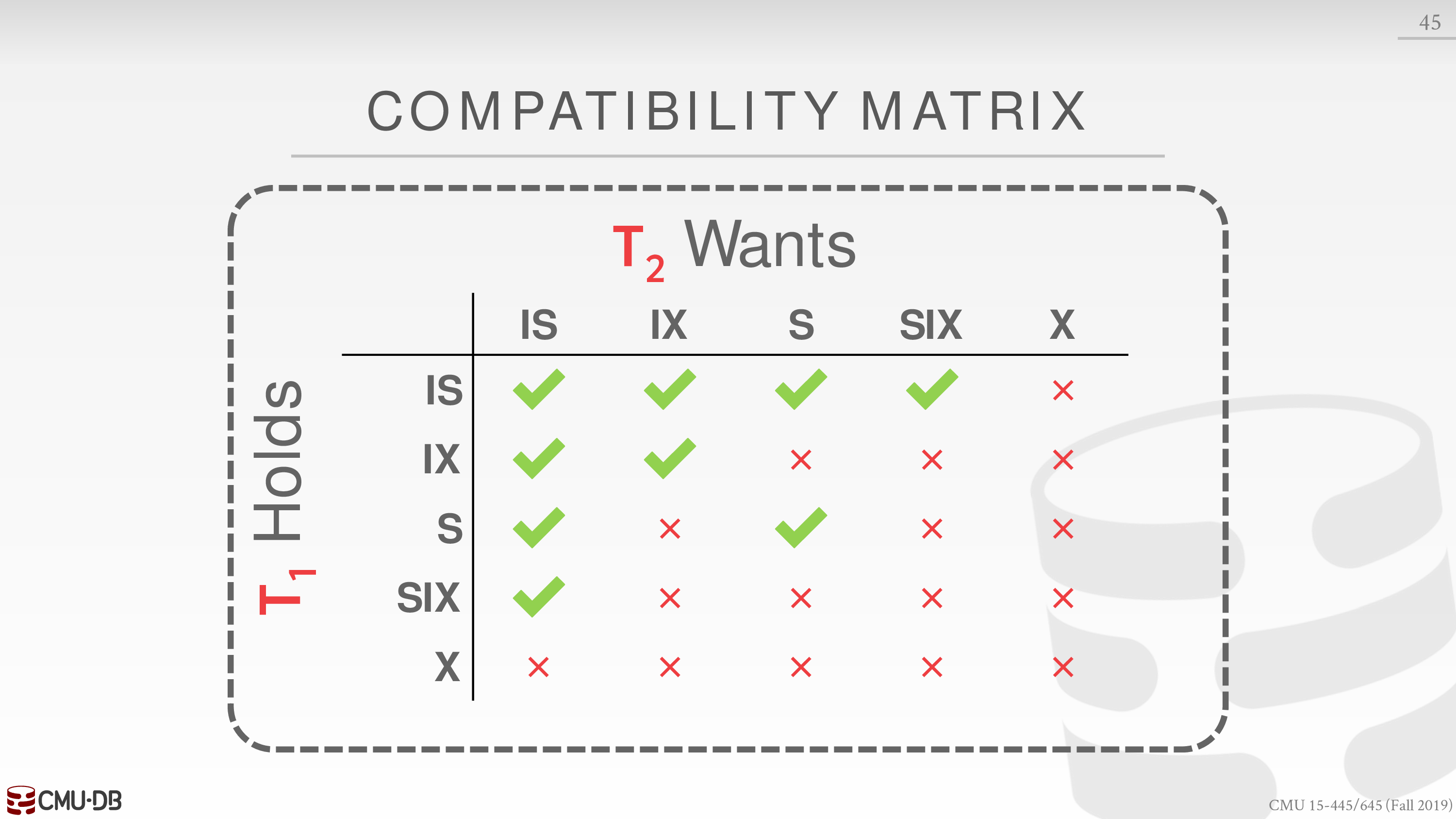
新的 locking 协议如下
- Each txn obtains appropriate lock at highest level of the database hierarchy.
- To get S or IS lock on a node, the txn must hold at least IS on parent node.
- To get X, IX, or SIX on a node, must hold at least IX on parent node.
这样提高了并发性,减少了加锁和解锁的开销
另外锁的升级也可以减少这种开销,比如将 S 原地升级为 X
具体的例子见课件
对于用户程序而言,可以在 SQL 语句中添加一些内容,从而提示 DBMS 更好的进行并发控制
不过这不是 SQL 标准中的一部分
比如
- Explicitly locks a table.
- Perform a select and then sets an exclusive lock on the matching tuples.
具体的例子见课件
NOTE CONTINUED
下述内容使用 2021 fall 的 schedule
这里有一系列的中文讲解视频
Timestamp Ordering Concurrency Control
这一节主要内容是:如何通过 Isolation 中乐观的并发控制协议实现事务的交错执行
其核心思想是利用时间戳决定事务在串行化下的执行顺序
例如对于事务 ,若 ,那么 DBMS 需要保证在串行化下事务 在 之前发生
对于时间戳的实现,有如下一些选择
- System Clock
- Logical Counter
- Hybrid
Basic Timestamp Ordering (T/O) Protocol
事务对 database object 的读写不需要加锁
每一个 database object 都会存在对应的两个时间戳
记录了最近的一个执行读写操作的事务对应的时间戳
对于事务 的每个读写操作,都会检查该操作是否违反某种协议,该协议描述如下
- 对于读操作
若 ,说明事务 试图读取 未来的值,于是事务 abort 并 restart 重新获取时间戳
否则,更新 ,执行读操作,拷贝 的值到事务的 workspace,以实现 repeatable reads
- 对于写操作
若 ,事务 abort 并 restart 重新获取时间戳
否则,更新 ,并执行写操作,并拷贝 的值到事务的 workspace,以实现 repeatable reads
Example
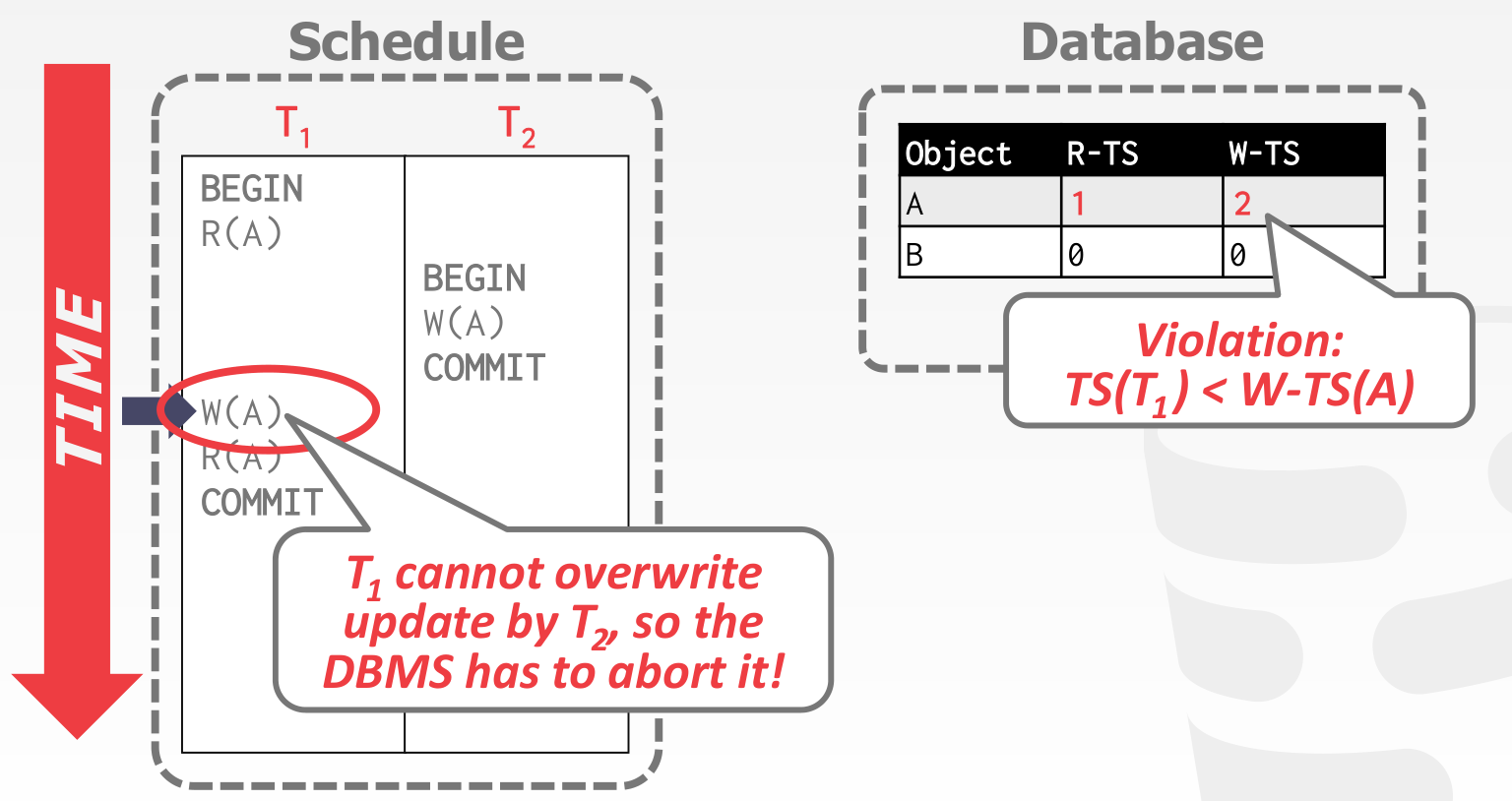
在这个例子中,事务 的时间戳为 1,事务 的时间戳为 2
事务 读 ,更新
事务 写 ,更新
然后事务 写 ,违反上述协议,所以事务 abort 并 restart 重新获取时间戳为 3
Thomas Write Rule
然而,在串行化下事务 先于事务 发生并不会发生 conflict,考虑优化这种情形,即 Thomas Write Rule

Discussion
对于 BASIC T/O,有如下一些讨论
- 不会出现死锁
- 较长的事务易饥饿
- 拷贝 的值到事务的 workspace 会产生开销
- 所允许的 schedules 是不可恢复的
A schedule is recoverable if txns commit only after all txns whose changes they read, commit.
下面举一个例子
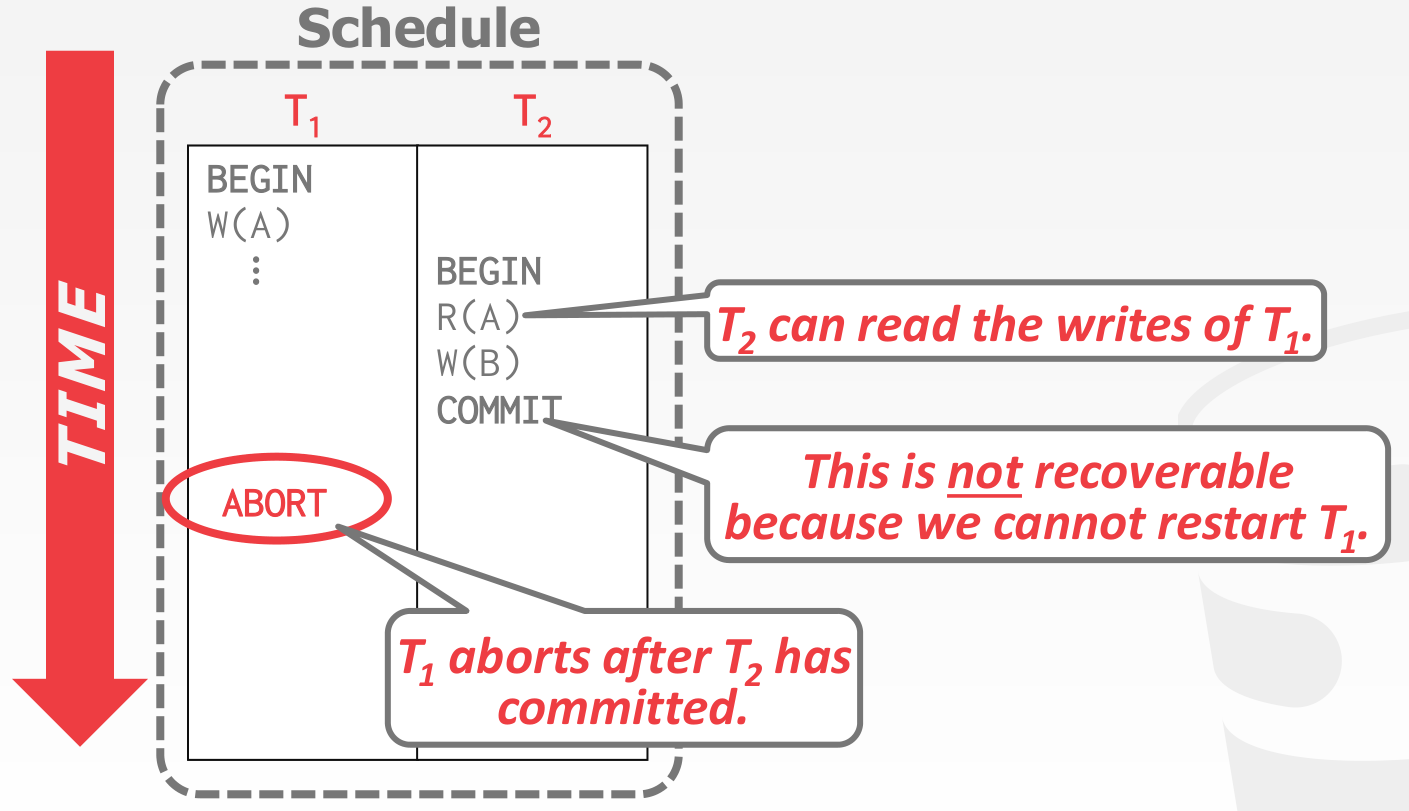
BASIC T/O 允许上述 schedule,由于事务 abort 了,事务 无法读取事务 所写入的值
Optimistic Concurrency Control (OCC)
命名有些误导,仍然属于 Timestamp 的范畴
主要思路是,DBMS 会为每个事务创建一个 workspace
- 类似 BASIC T/O,读操作会拷贝 的值到事务的 workspace 中
- 而写操作不是写在 DB 中,而是写在事务的 workspace 中
OCC 分为三个阶段
- Read Phase: Track the read/write sets of txns and store their writes in a private workspace.
- Validation Phase: When a txn commits, check whether it conflicts with other txns.
- Write Phase: If validation succeeds, apply private changes to database. Otherwise abort and restart the txn.
事务的时间戳由 commit (the beginning of the validation phase) 的时刻决定
通常仅允许一个事务处于 Write Phase
我们主要关注 Validation Phase,有两种方案
Validation Phase
Backward Validation
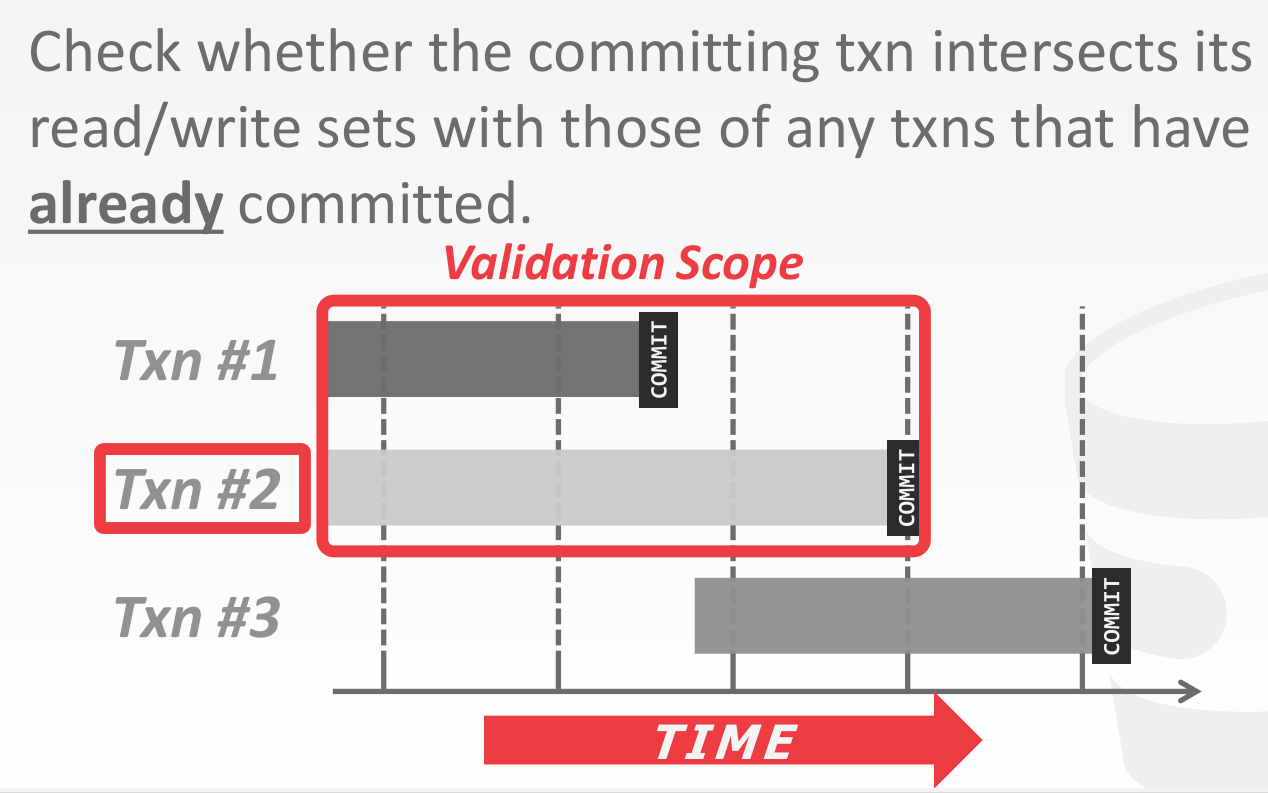
当出现 conflicts,只能 abort 并 restart 自身,因为 old txns 已经 commit 了
Forward Validation
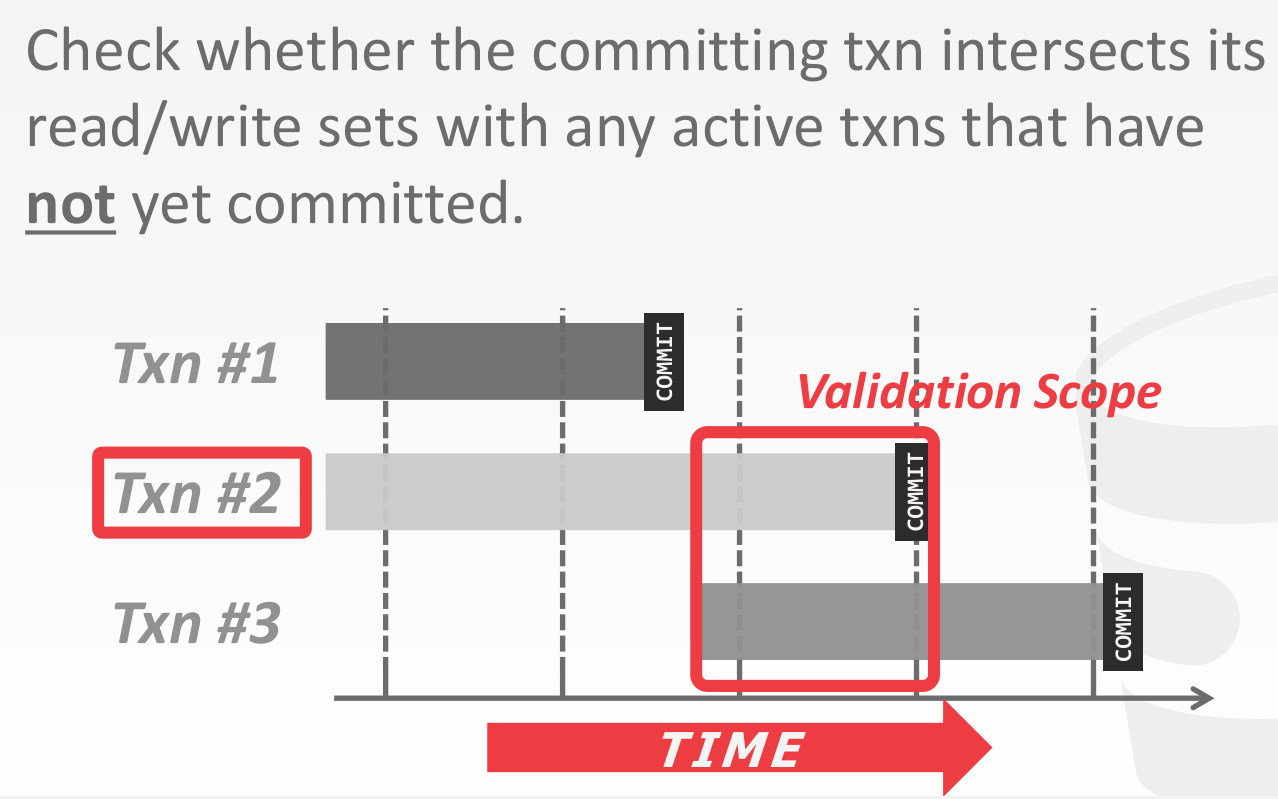
当出现 conflicts,可以考虑 abort 并 restart 自身,也可以考虑 abort 并 restart new txns
若 ,有下述三种情形
- completes all three phases before begins.
即完全串行
- completes before starts its Write phase, and does not write to any object read by .
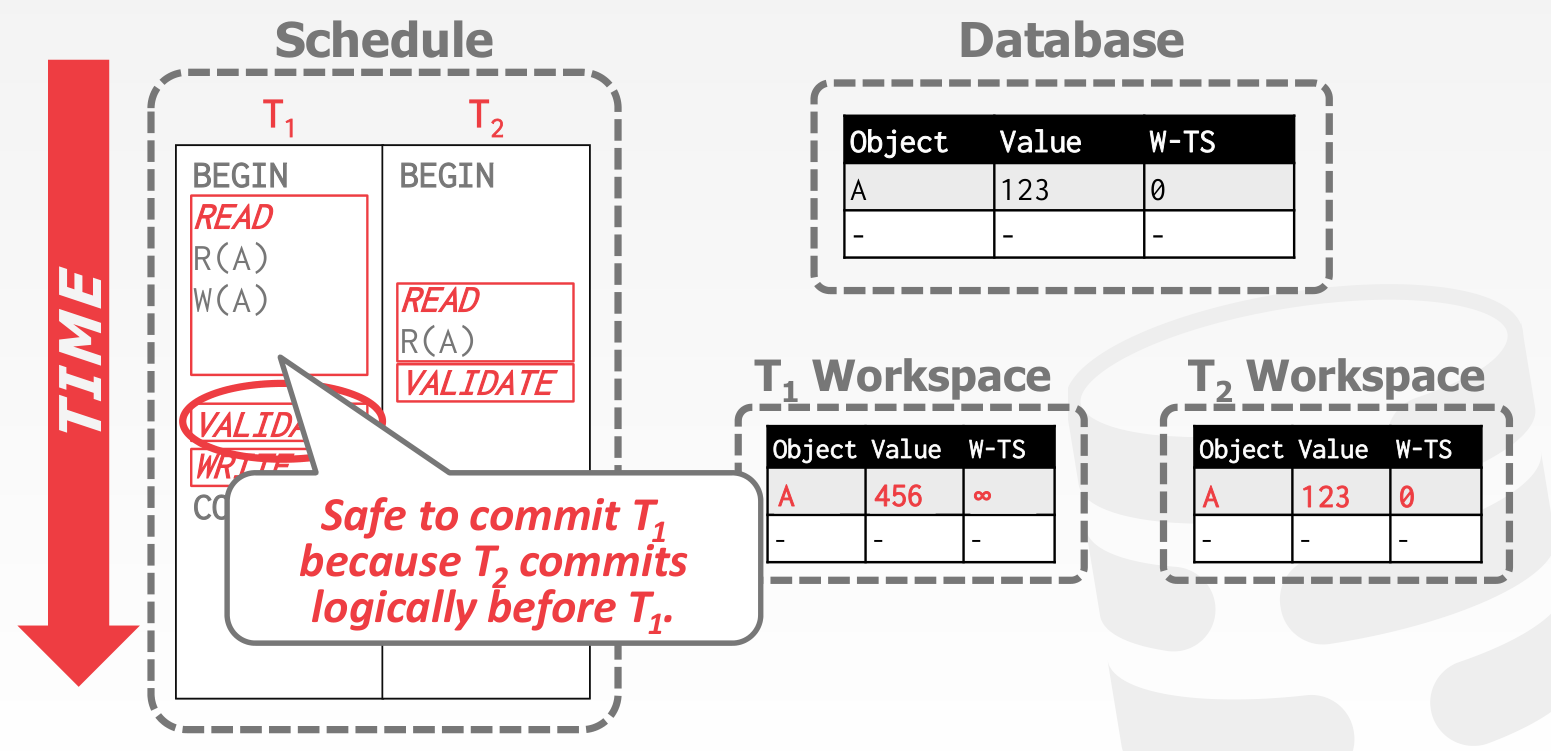
- completes its Read phase before completes its Read phase, and does not write to any object that is either read or written by .
Discussion
当事务间的 conflicts 较少时,OCC 的性能会很好,例如下述场景
- All txns are read-only (ideal).
- Txns access disjoint subsets of data.
OCC 同样存在一些问题
- 拷贝 的值到事务的 workspace 会产生开销
- validation phase 和 write phase 的瓶颈
- aborts are more wasteful than in 2PL because they only occur after a txn has already executed
Isolation Levels
Phantom Reads
截至目前为止,我们仅考虑了 update 这一种写操作,当引入 create 和 delete 写操作,就可能产生 Phantom Reads 问题,例如
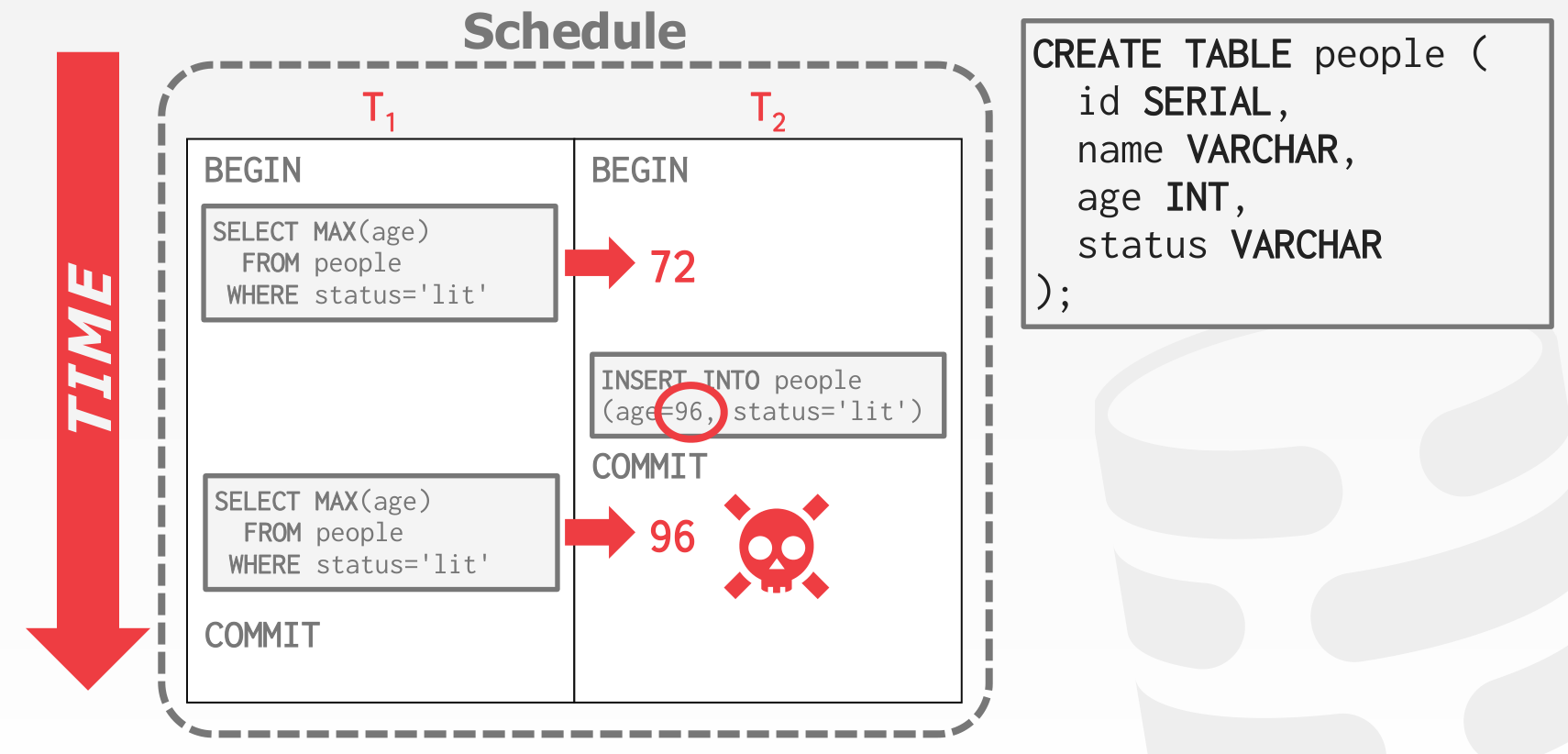
这是因为 conflict serializability 仅能保证对当前固定的 database objects 的读写操作是满足 serializability 的,当 database objects 的数量发生了变化,就会出现问题
有下述几种方案能够解决 Phantom Reads 问题
- Re-Execute Scans
Upon commit, re-execute just the scan portion of each query and check whether it generates the same result.
重新执行一遍比较结果,性能下降
- Predicate Locking
Shared lock on the predicate in a WHERE clause of a SELECT query.
Exclusive lock on the predicate in a WHERE clause of any UPDATE, INSERT, or DELETE query.
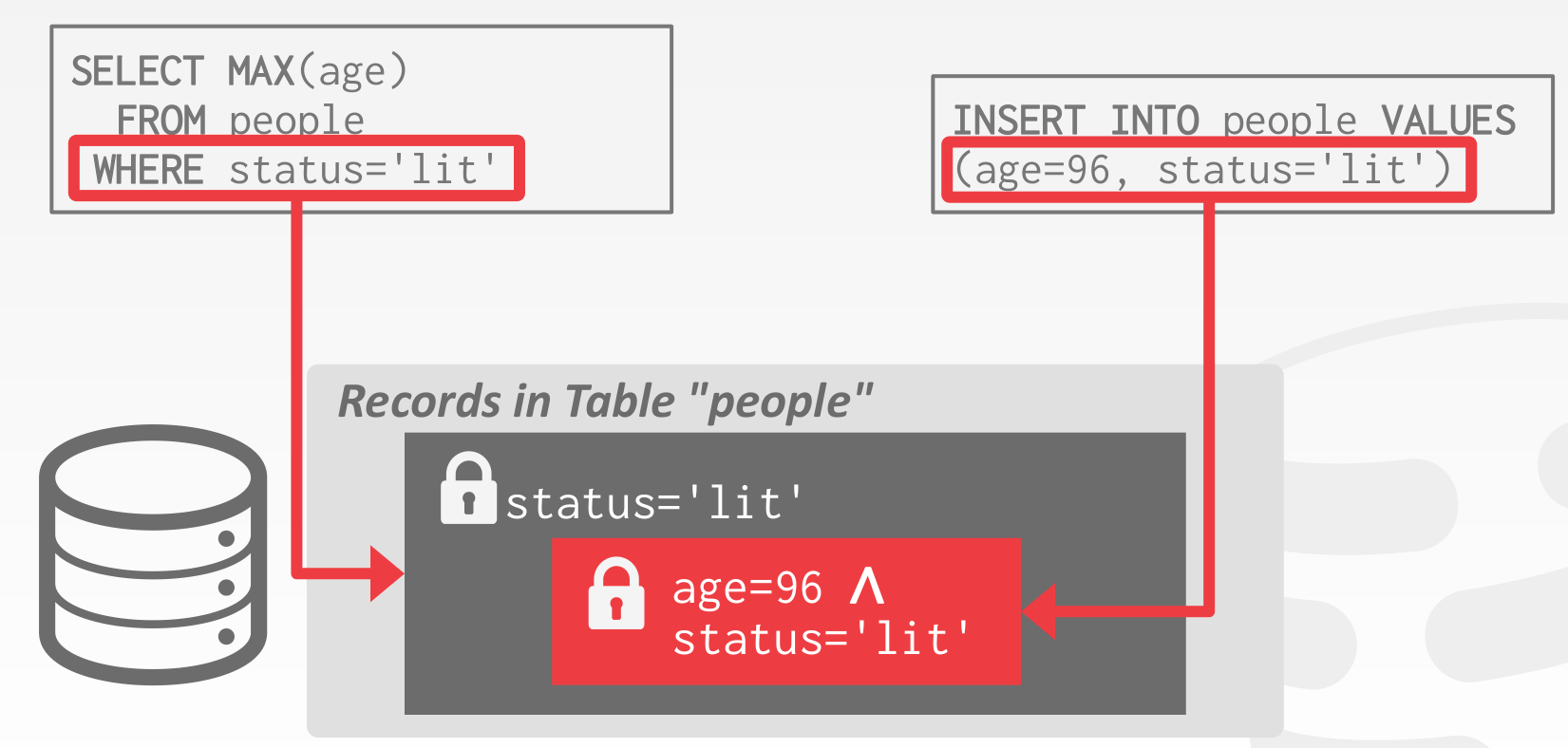
可以参考 https://github.com/Vonng/ddia/blob/master/ch7.md#%E8%B0%93%E8%AF%8D%E9%94%81
- Index Locking
可以参考 https://github.com/Vonng/ddia/blob/master/ch7.md#%E7%B4%A2%E5%BC%95%E8%8C%83%E5%9B%B4%E9%94%81
- Materializing Conflicts
可以参考 https://github.com/Vonng/ddia/blob/master/ch7.md#%E7%89%A9%E5%8C%96%E5%86%B2%E7%AA%81
Isolation Levels
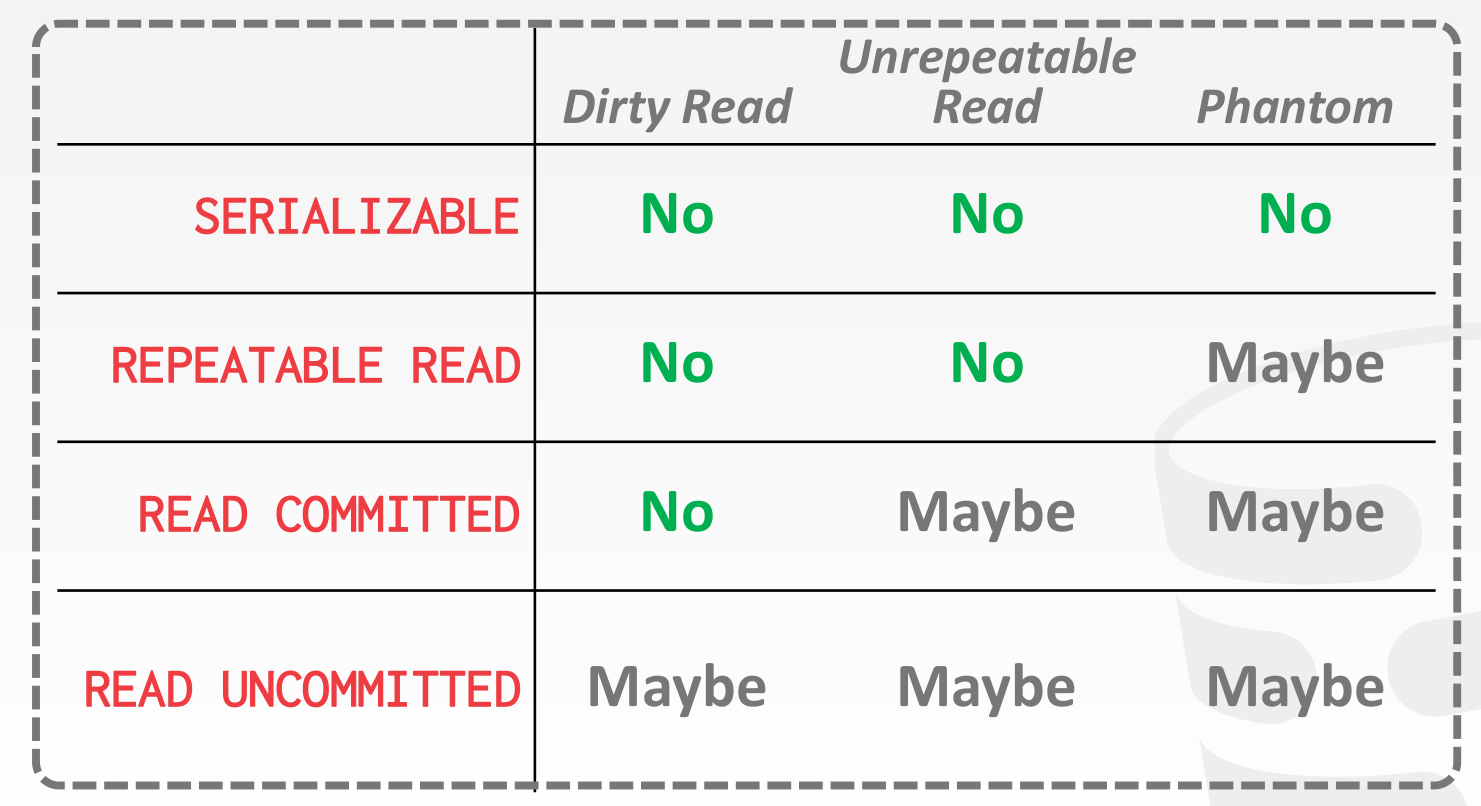
使用悲观的并发控制协议实现
- SERIALIZABLE: Obtain all locks first; plus index locks, plus strict 2PL.
- REPEATABLE READS: Same as above, but no index locks.
- READ COMMITTED: Same as above, but S locks are released immediately.
- READ UNCOMMITTED: Same as above, but allows dirty reads (no S locks).
通常情况下 DBMS 默认的 isolation level 并不是 SERIALIZABLE,因而业务程序员在使用 DBMS 时存在一定的心智负担
SQL-92 中可以设定事务的 isolation level
SET TRANSACTION ISOLATION LEVEL <isolation-level>;BEGIN TRANSACTION ISOLATION LEVEL <isolation-level>;SQL-92 也提供了 access mode,可以让 DBMS 优化 lock 或者 validate 的过程
SET TRANSACTION <access-mode>;BEGIN TRANSACTION <access-mode>;其中
- READ WRITE (Default)
- READ ONLY
Multi-Version Concurrency Control (MVCC)
The DBMS maintains multiple physical versions of a single logical object in the database:
- When a txn writes to an object, the DBMS creates a new version of that object.
- When a txn reads an object, it reads the newest version that existed when the txn started.
从性能的角度来看,快照隔离的一个关键原则是:读不阻塞写,写不阻塞读。这允许数据库在处理一致性快照上的长时间查询时,可以正常地同时处理写入操作,且两者间没有任何锁争用。
这里有一个例子
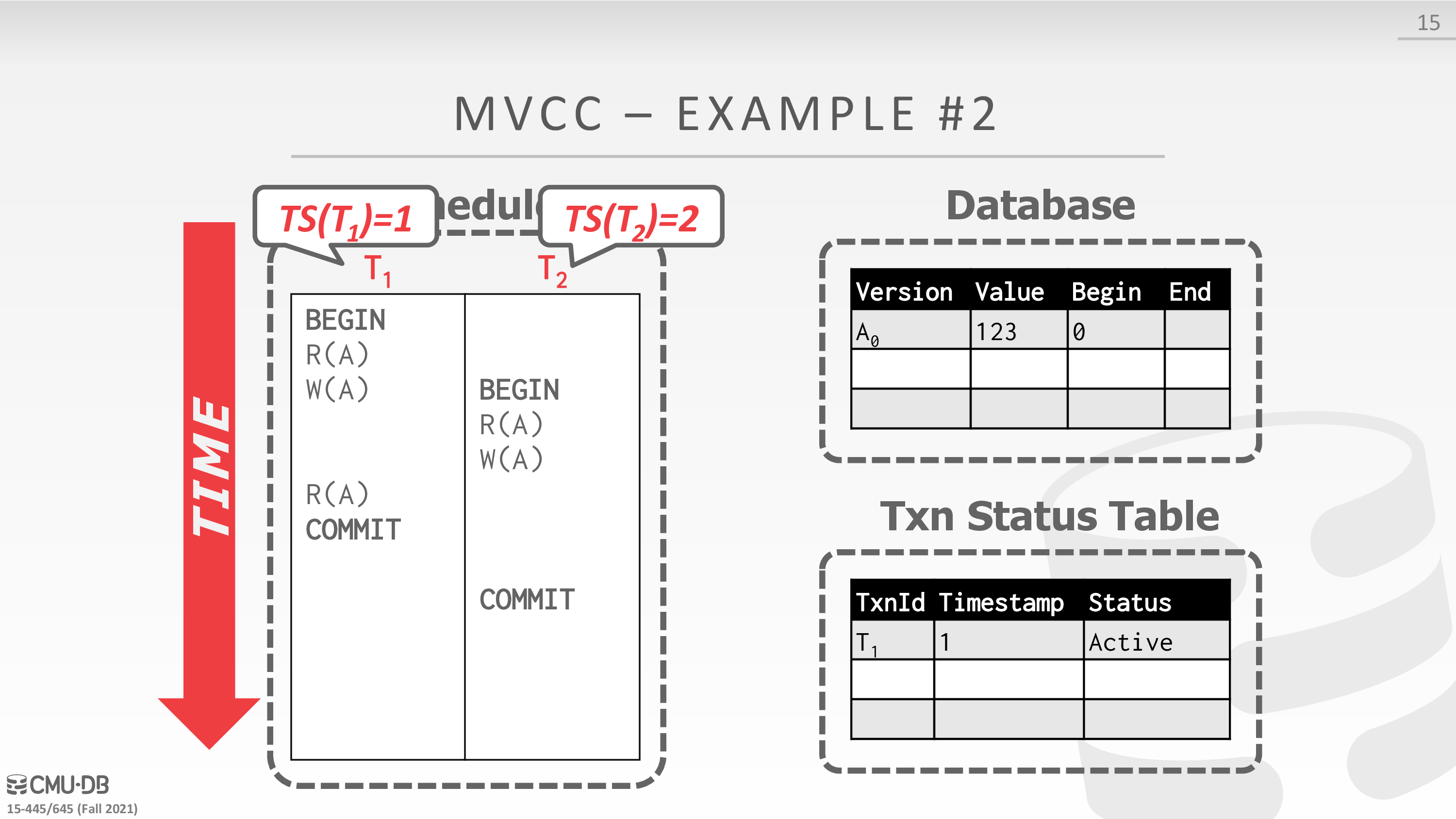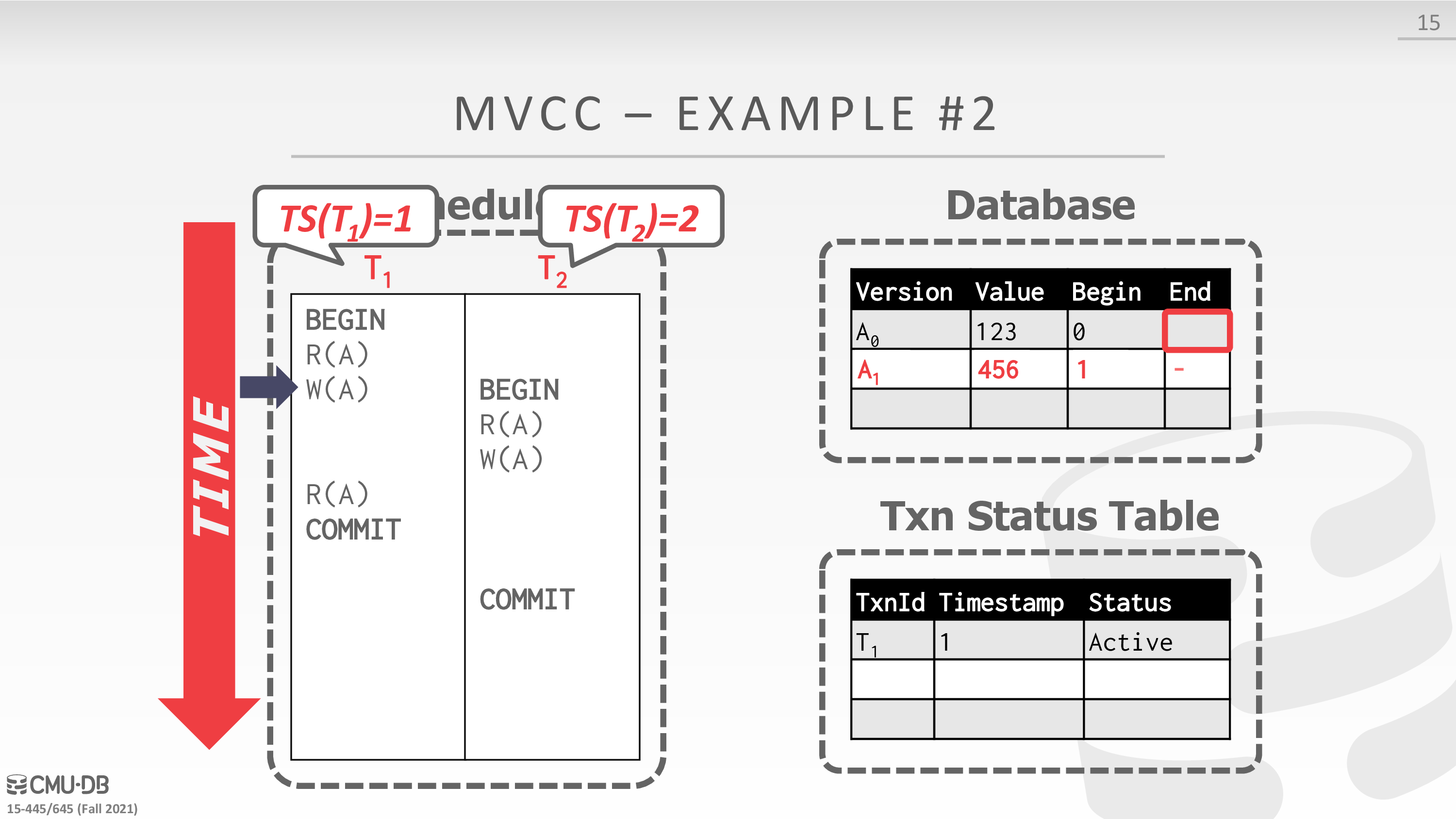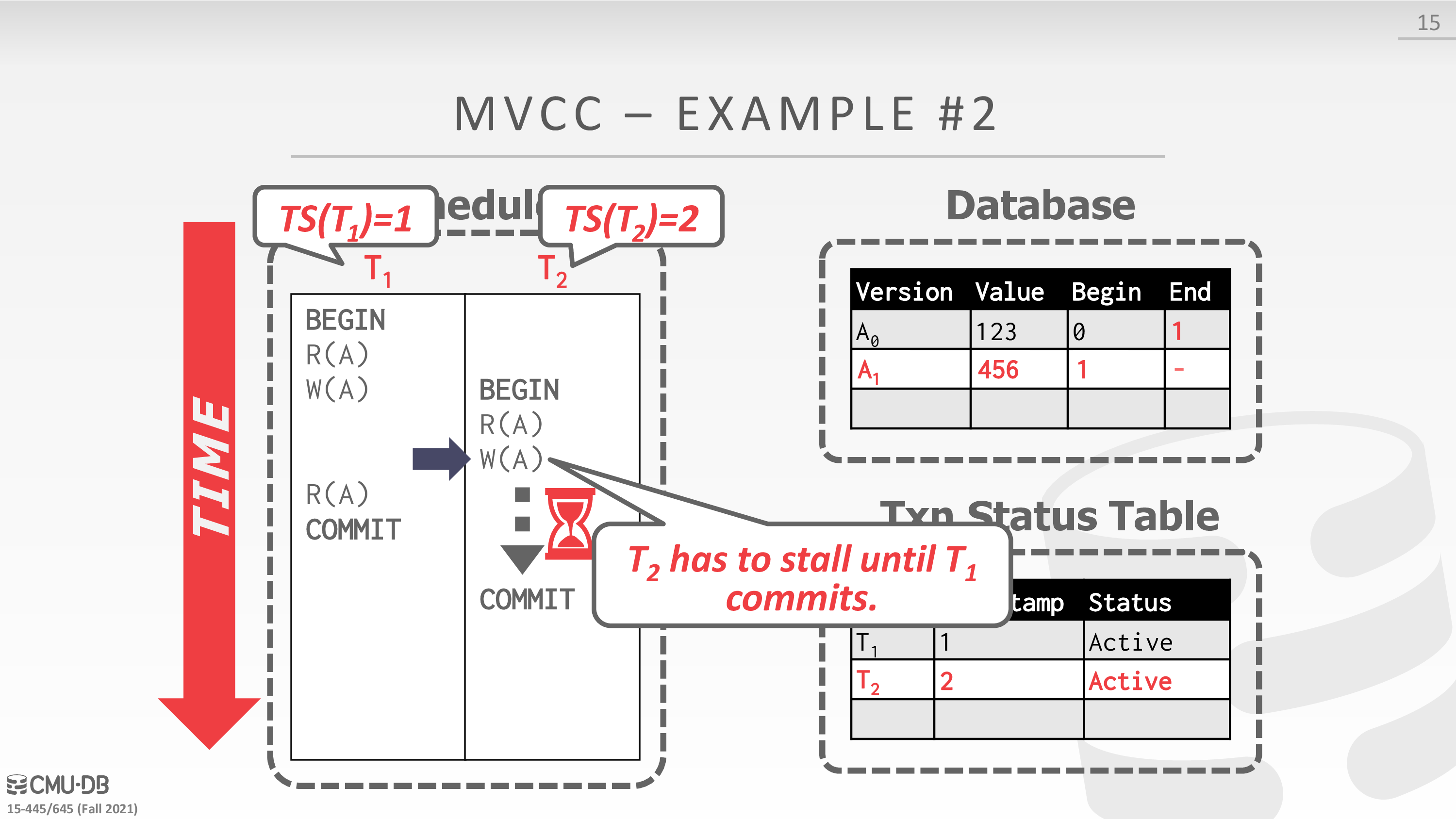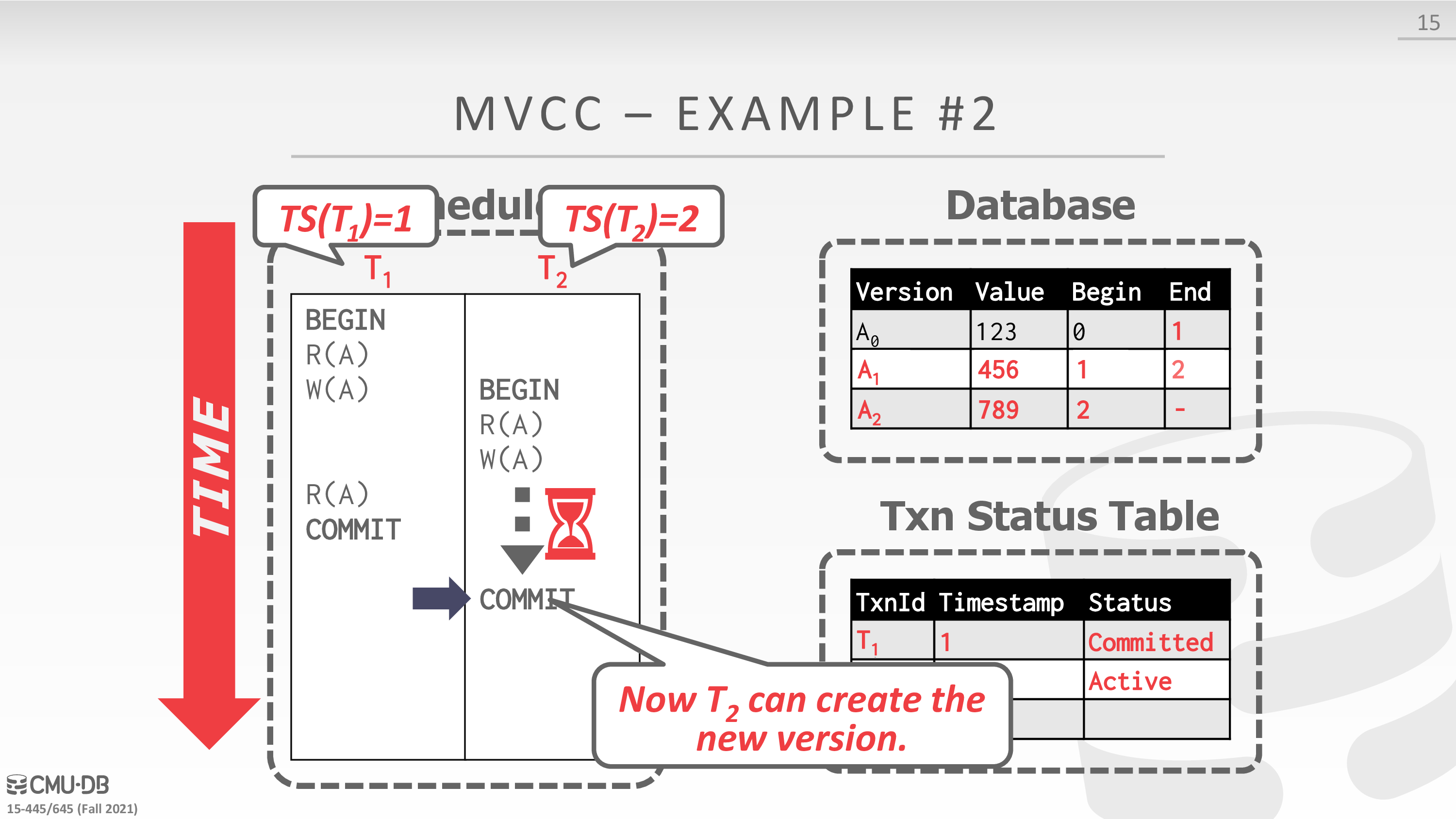
Concurrency Control Protocol
通常 MVCC 需要与其他的并发控制协议结合,如
- MV-2PL
- MV-TO
- MV-OCC
Version Storage
需要通过某种数据结构保存 database object 的历史信息
Append-Only Storage
使用链表维护
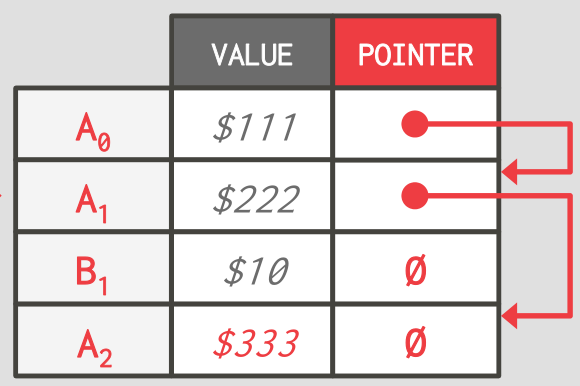
上述例子的顺序是 Oldest-to-Newest (O2N),这样便于 append,但是 look up 最新的版本会比较困难
类似存在 Newest-to-Oldest (N2O) 的顺序,在这种顺序下,append 的时候需要更新对应的索引,后面会有进一步的讨论
Time-Travel Storage
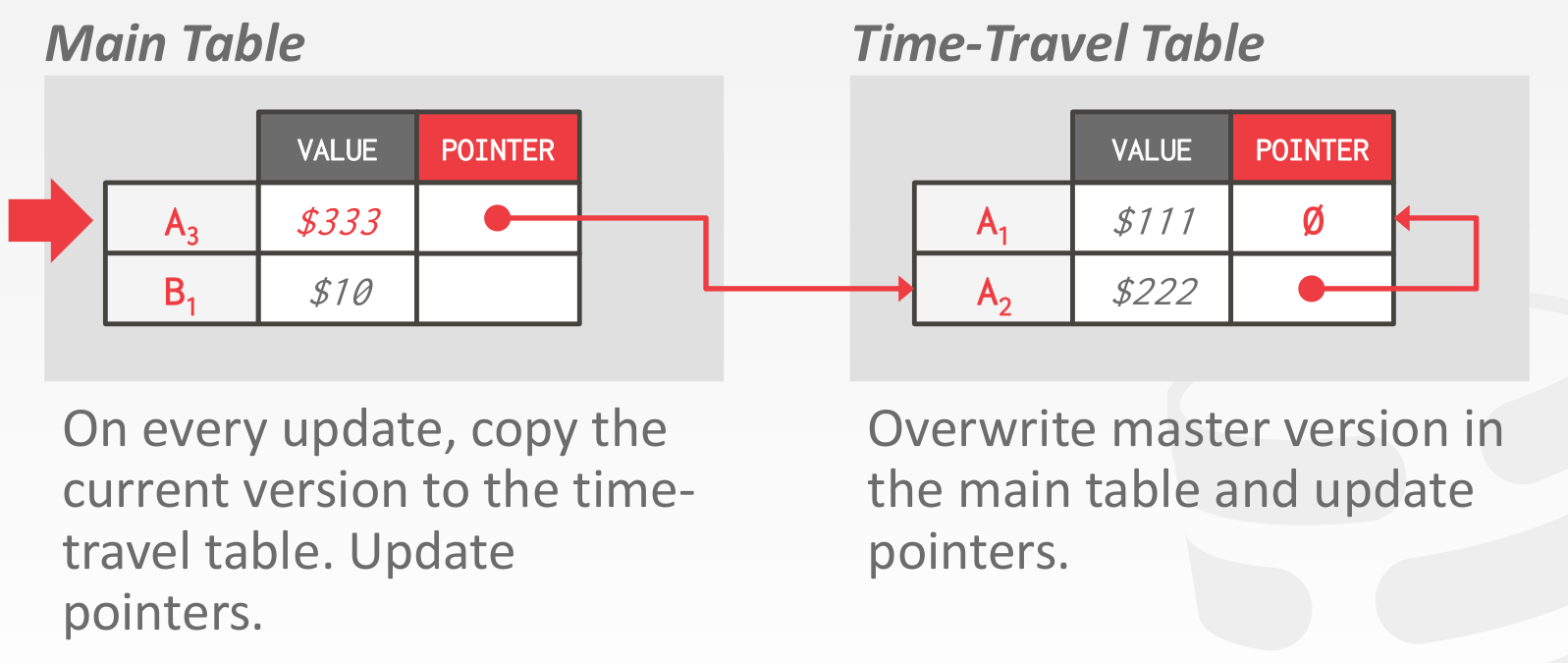
主表中 object 的个数不变,历史信息存储在额外的表中
Delta Storage
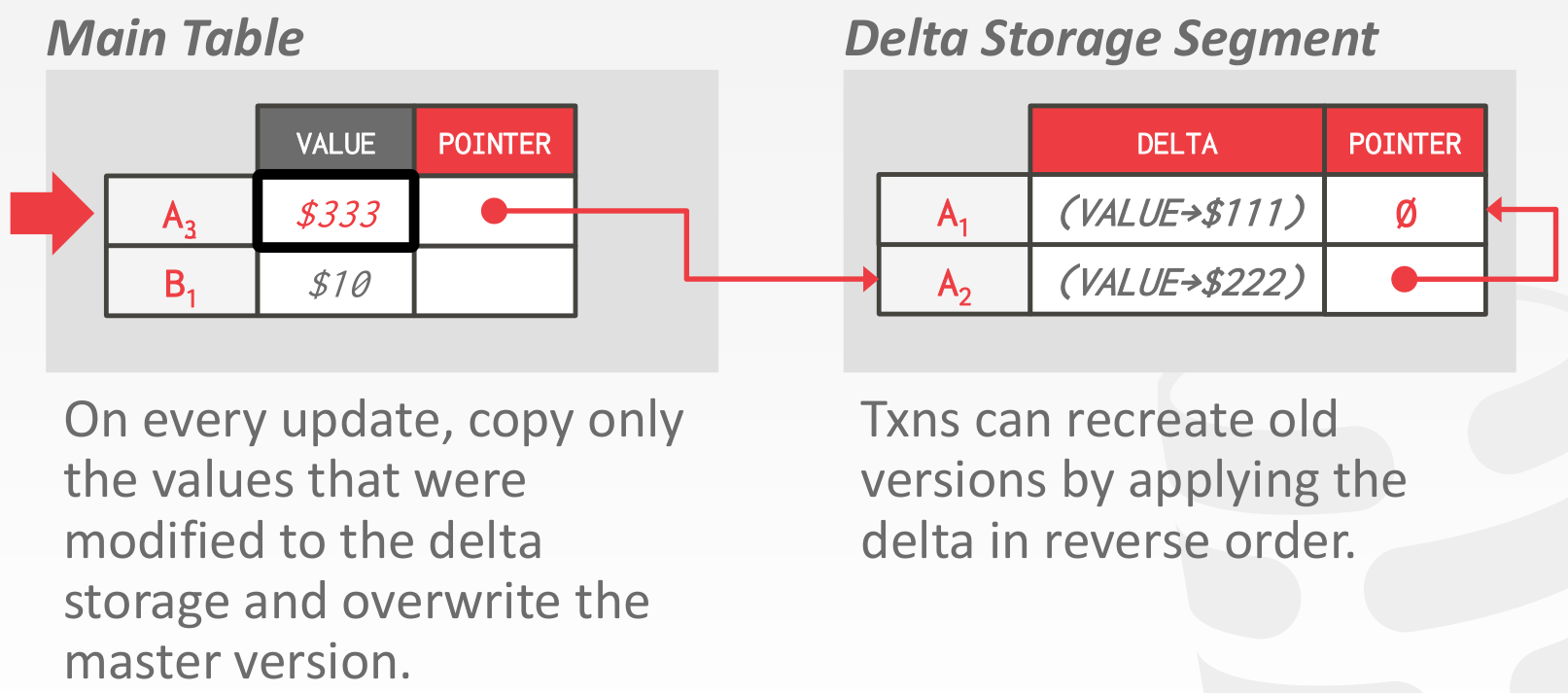
类似 Time-Travel Storage,不过只存储变化的部分,例如某个 tuple 其中的一列信息
Garbage Collection
The DBMS needs to remove reclaimable physical versions from the database over time.
- No active txn in the DBMS can “see” that version (snapshot isolation).
- The version was created by an aborted txn.
Tuple-level
Background Vacuuming
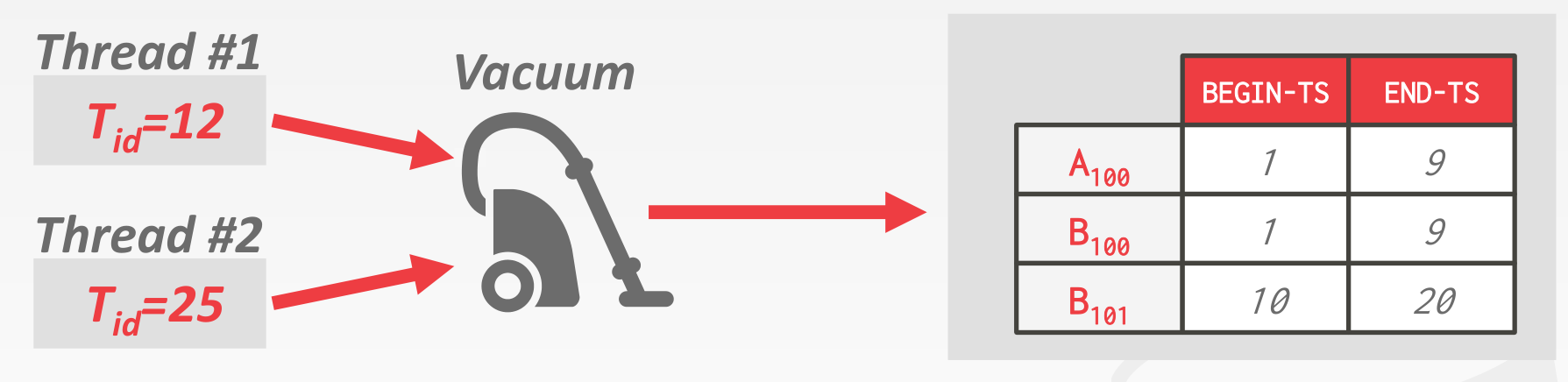
一个额外的线程间隔的获取当前 txn threads 的信息,然后扫描全表 (被修改的部分),清理掉不会被访问的数据
此处 会被清理掉
Cooperative Cleaning

仅适用于 N2O 存储,txn thread 在读取 object 的时候,顺便清理掉过时的数据
需要结合 txn status table 的信息
Transaction-level
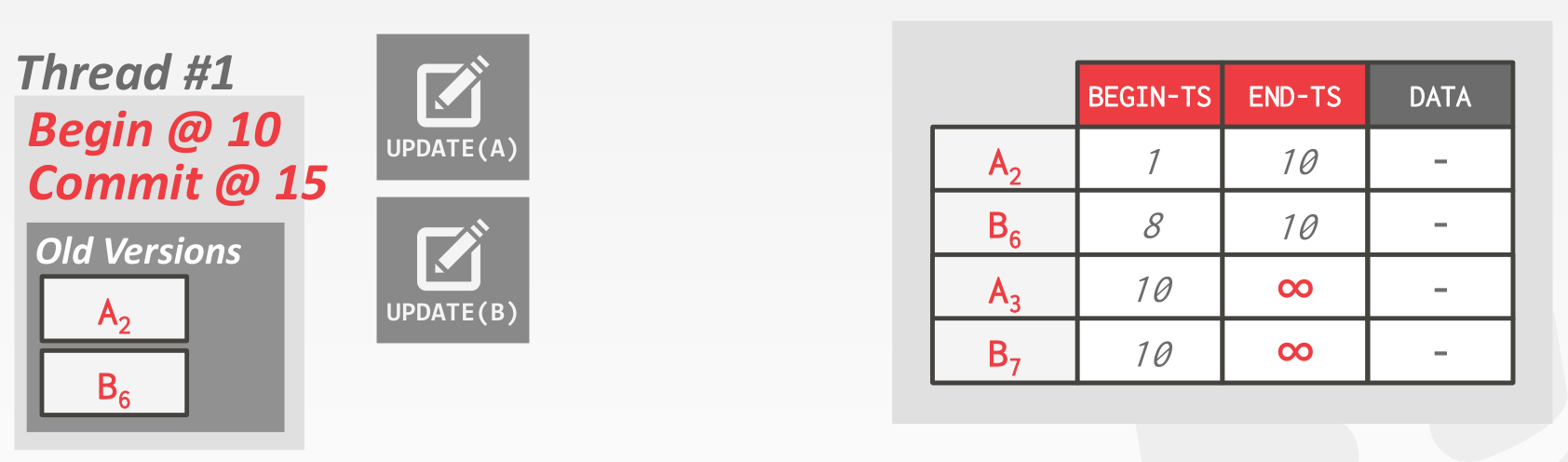
以 txn 为单位,txn 提交后,清理掉本次 txn 中过时的数据
仍然需要结合 txn status table 的信息
Index Management
Primary key indexes point to version chain head.
Secondary indexes are more complicated:
- Logical Pointers
- Primary Key
- Tuple Id
- Physical Pointers
具体见课件
Deletes
- Deleted Flag
- Tombstone Tuple
具体见课件
Database Logging
Failure Classification
- Transaction Failures
- Logical Errors (integrity constraint violation)
- Internal State Errors (deadlock)
- System Failures
- Software Failure (DBMS, OS)
- Hardware Failure (power off)
- Fail-stop Assumption: Non-volatile storage contents are assumed to not be corrupted by system crash.
- Storage Media Failures
- Non-Repairable Hardware Failure
- No DBMS can recover from this! Database must be restored from archived version.
Undo & Redo
- Undo: The process of removing the effects of an incomplete or aborted txn.
- Redo: The process of re-instating the effects of a committed txn for durability.
Buffer Pool Policies
所有 Page 驻留内存时都会由 Buffer Pool 来统一管理,它们会被放在 Buffe Pool 的一个个 Frame 中。我们可以理解为一个 Page 有内存和磁盘两个副本,由于磁盘 IO 巨慢无比,很多更新操作出于性能考虑只会更新内存中的副本。如果对某个 Page 的更新已经反映到内存中的副本上,尚未反映到磁盘上的副本上,我们就说这个 Page 是 Dirty Page。由于内存是易失的,为了保证数据不丢失,Dirty Page 必须在某个时刻刷到磁盘上去。
那么问题来了,应该何时将这些 Dirty Page 刷盘?如果这些 Dirty Page 上有未提交事务的改动,能将它们刷盘吗?
回答这个问题需要引出 Buffer Pool 的不同策略:
- STEAL:允许将未提交事务的改动刷盘。
- NO-STEAL:与 STEAL 相反。
- FORCE:必须在事务提交时把该事务的所有改动刷盘。
- NO-FORCE:与 FORCE 相反。
Buffer Pool 可以在 STEAL 和 NO-STEAL 中二选一,然后在 FORCE 和 NO-FORCE 中二选一,组成自己的策略。

上图是笔者从 Runtime 性能和 Recovery 性能两个维度对 Buffer Pool 不同策略的分析。
首先是 Runtime 性能,结论是 STEAL/NO-FORCE 的策略最快,NO-STEAL/FORCE 的策略最慢。这是因为 STEAL 的策略能让我们很快地(因为刷某个 Dirty Page 不需要等待更新了它的所有事务提交)把 Dirty Page 刷盘,腾出 Buffer Pool 空间给其他 Page 用;NO-FORCE 的策略不要求事务提交时同步刷盘,而是由 Buffer Pool 来定期或者按需刷盘,这种做法大大减少了刷盘的次数(因为很可能会有很多事务改了同一个 Page,最终刷一次盘就给搞定了)。总的来说,STEAL/NO-FORCE 的策略,减小了单个事务的 Latency,提升了整个系统的 Throughput,是看中 Runtime 性能的系统的上上之选。
其次是 Recovery 性能,结论是 NO-STEAL/FORCE 的策略最快,STEAL/NO-FORCE 的策略最慢。**这是因为 NO-STEAL 的策略保证了磁盘上的任何 Page 都不含未提交事务的改动,不需要考虑未提交事务的 Undo。FORCE 的策略保证了所有已提交事务的改动都已经反映到了磁盘上,不需要考虑已提交事务的 Redo。**所以,NO-STEAL/FORCE 策略让我们在 Recovery 阶段不需要做任何事情,速度快得飞起,这个策略是看中 Recovery 性能的系统的上上之选。
NO-STEAL + FORCE 策略存在一个严重的问题,即 cannot support write sets that exceed the amount of physical memory available,这是因为一个事务的修改必须完整的反映到 buffer pool 之后才能整体刷盘
因为大多数数据库都更看重 Runtime 性能,所以 STEAL/NO-FORCE 策略「大行其道」。
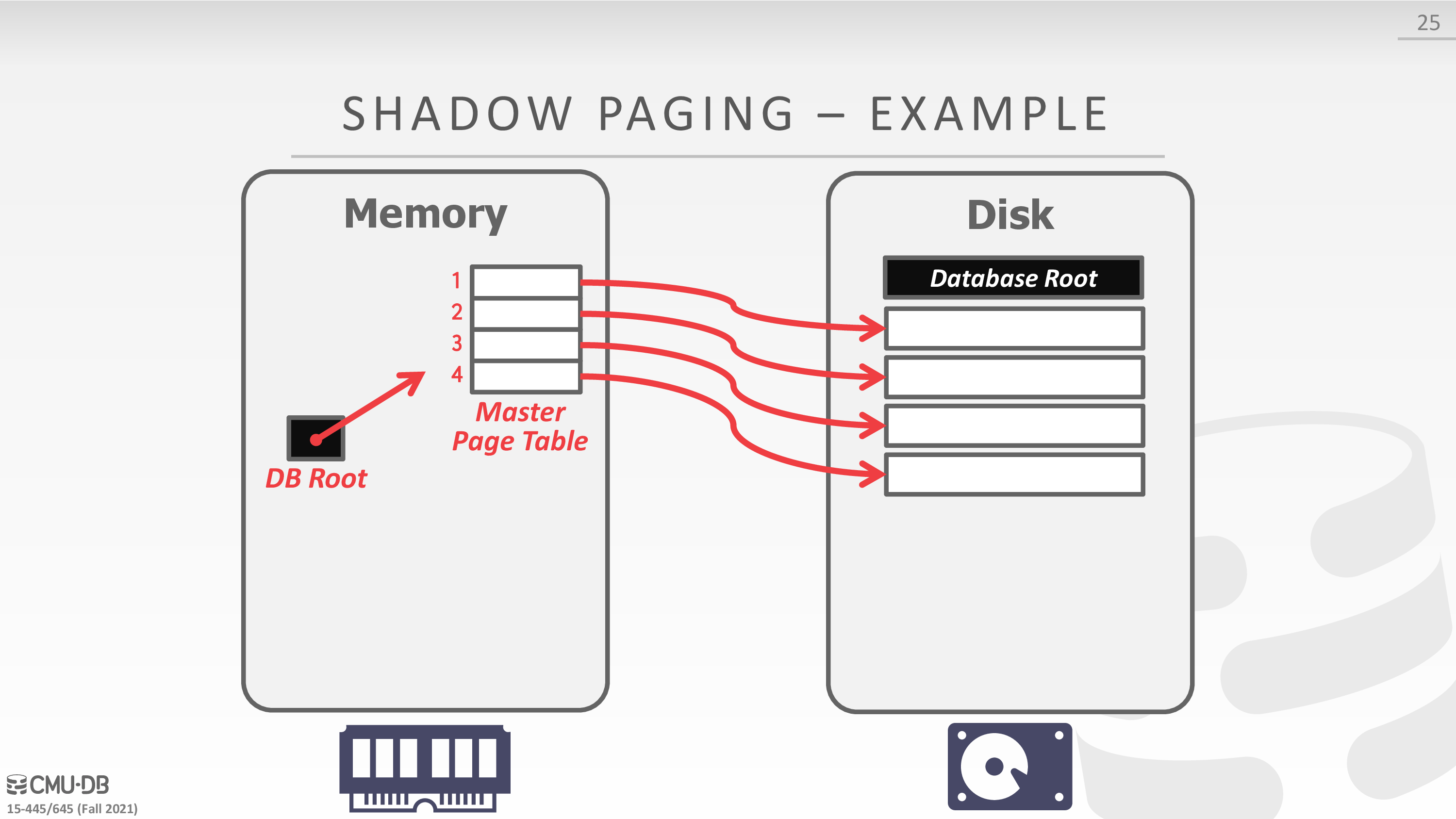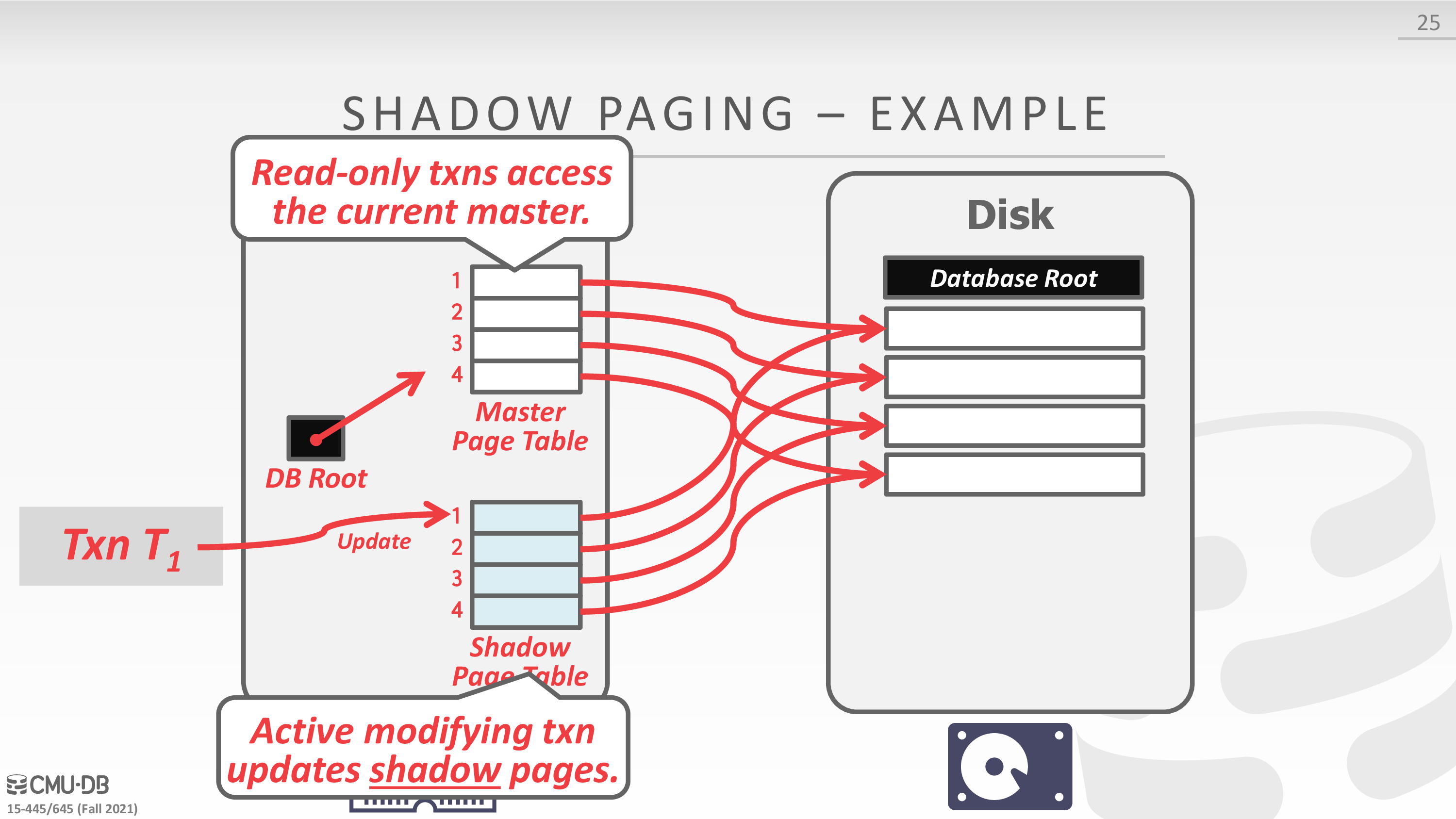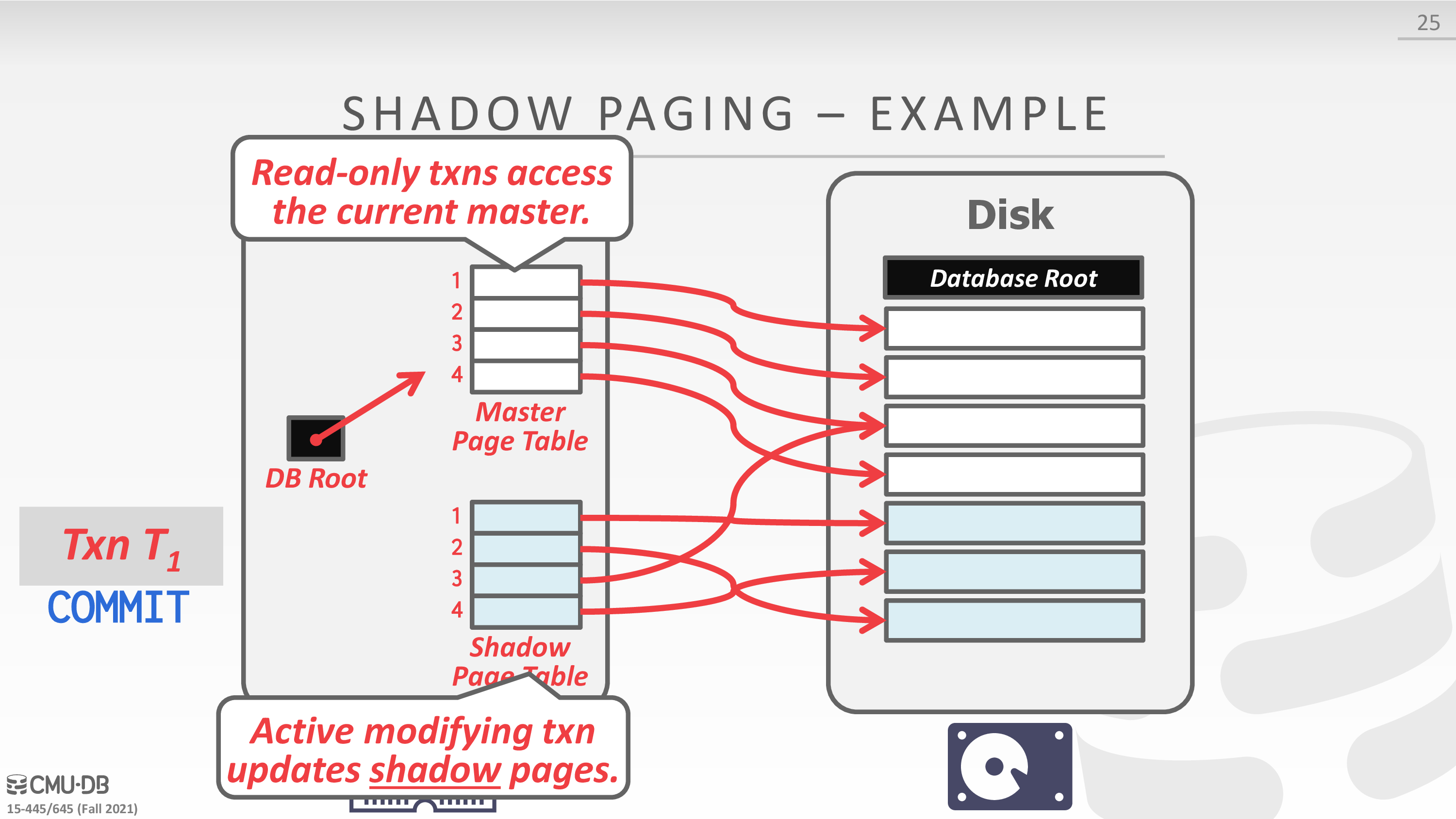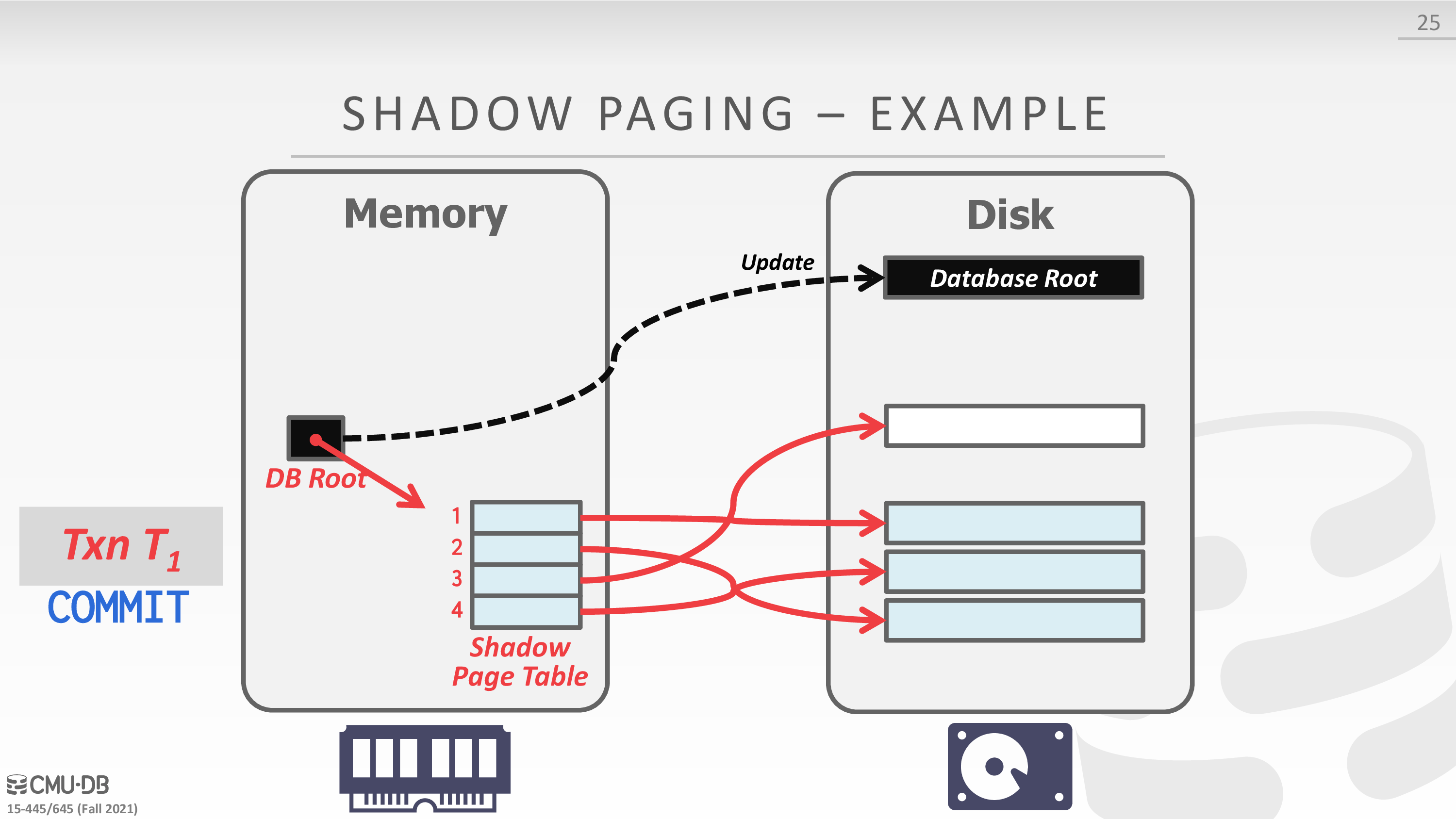
Shadow Paging
之前 ACID 的时候提过
-
Buffer Pool Policy: NO-STEAL + FORCE
-
Maintain two separate copies of the database:
- Master: Contains only changes from committed txns.
- Shadow: Temporary database with changes made from uncommitted txns.
-
Txns only make updates in the shadow copy.
-
When a txn commits, atomically switch the shadow to become the new master.
-
Undo & Redo:
- Undo: Remove the shadow pages. Leave the master and the DB root pointer alone.
- Redo: Not needed at all.
-
Disadvantages:
- Copying the entire page table is expensive.
- Commit overhead is high.
下面是一个例子
Write-Ahead Log
- Buffer Pool Policy: STEAL + NO-FORCE
- Maintain a log file separate from data files that contains the changes that txns make to database.
- Assume that the log is on stable storage.
- DBMS must write to disk the log file records that correspond to changes made to a database object before it can flush that object to disk.
- Protocol: Each log entry contains information about the change to a single object:
- Transaction Id
- Object Id
- Before Value (UNDO)
- 实际上 undo log 也可以用于实现 mvcc
- After Value (REDO)
下面是一个例子
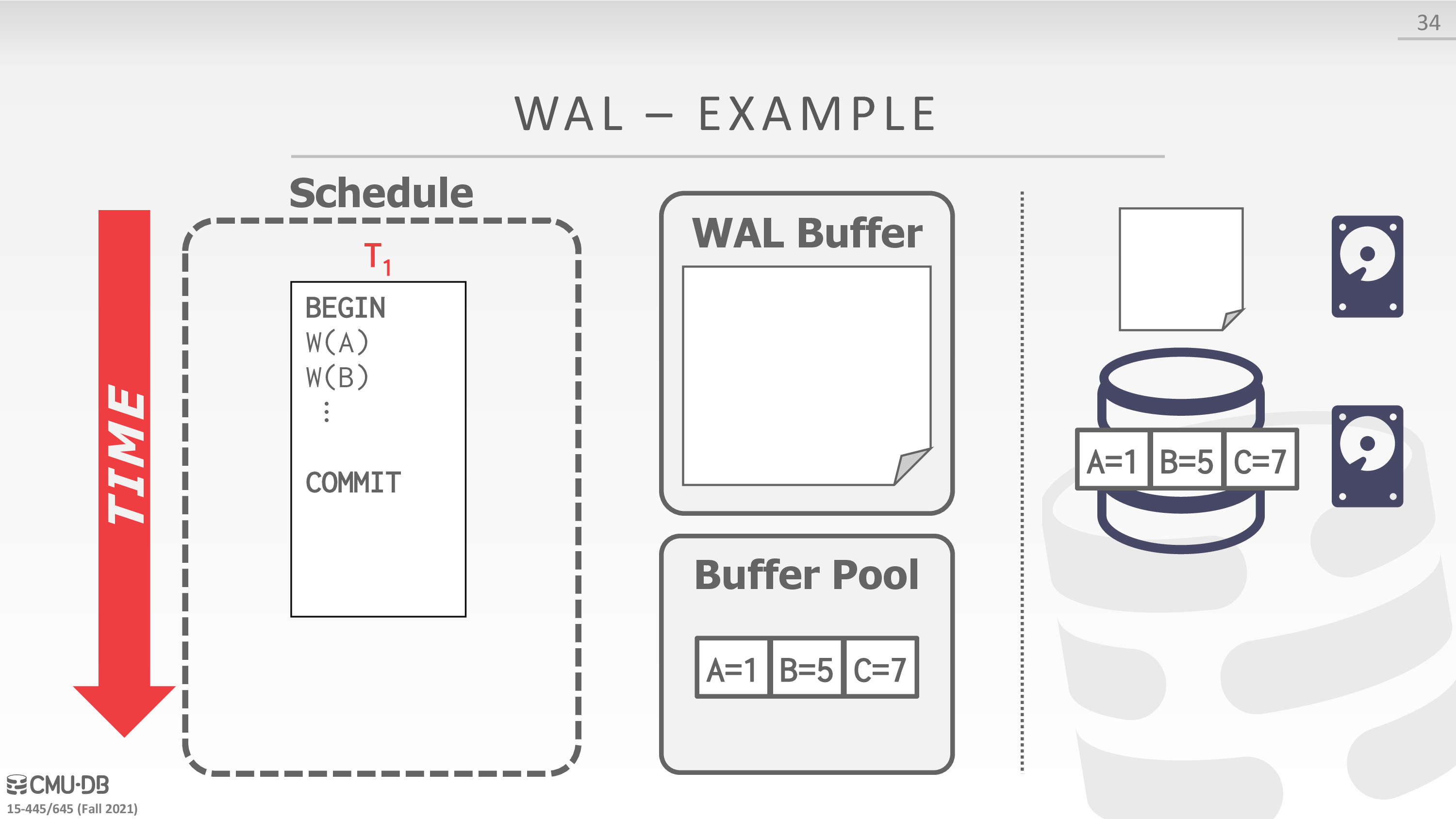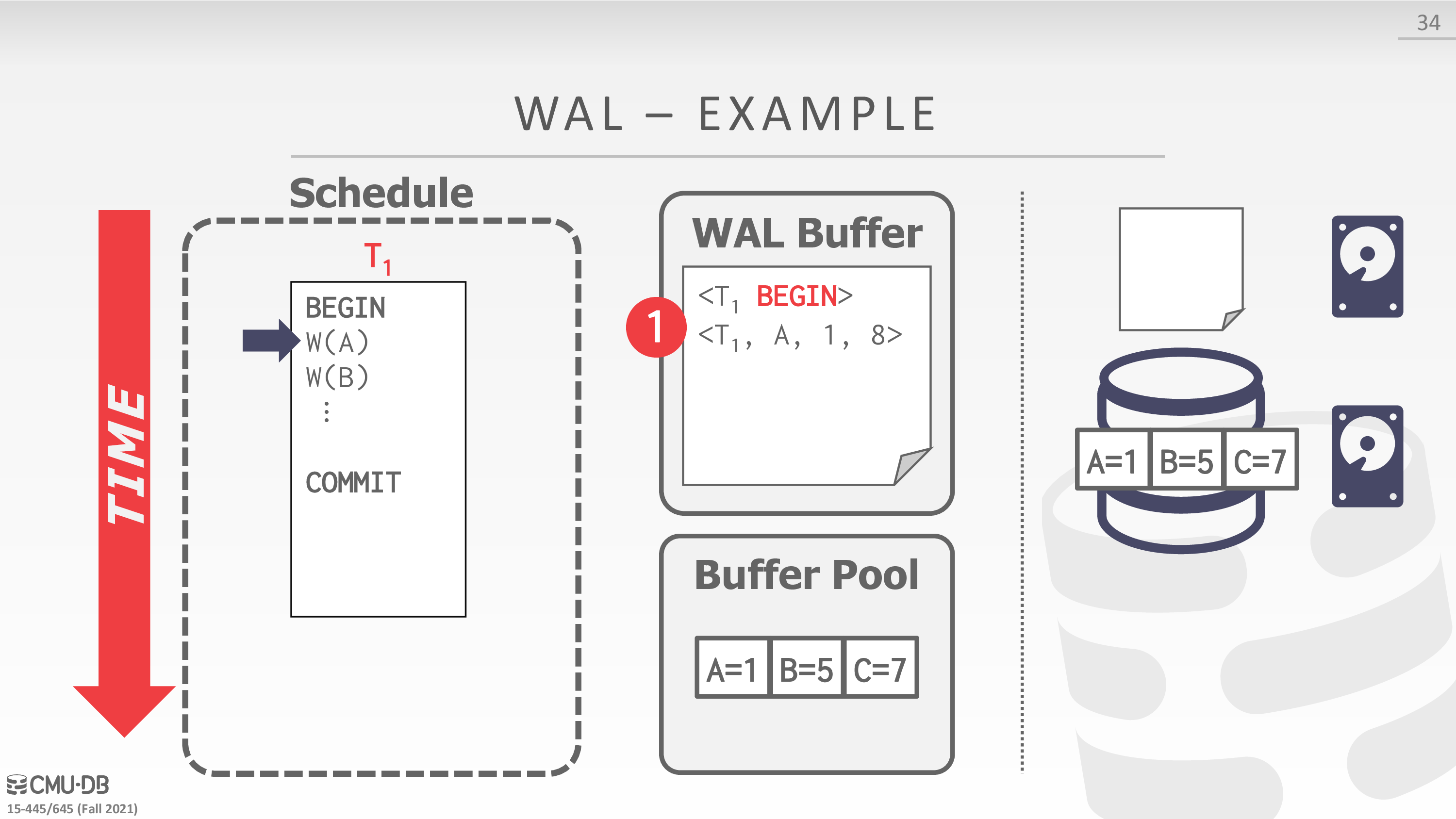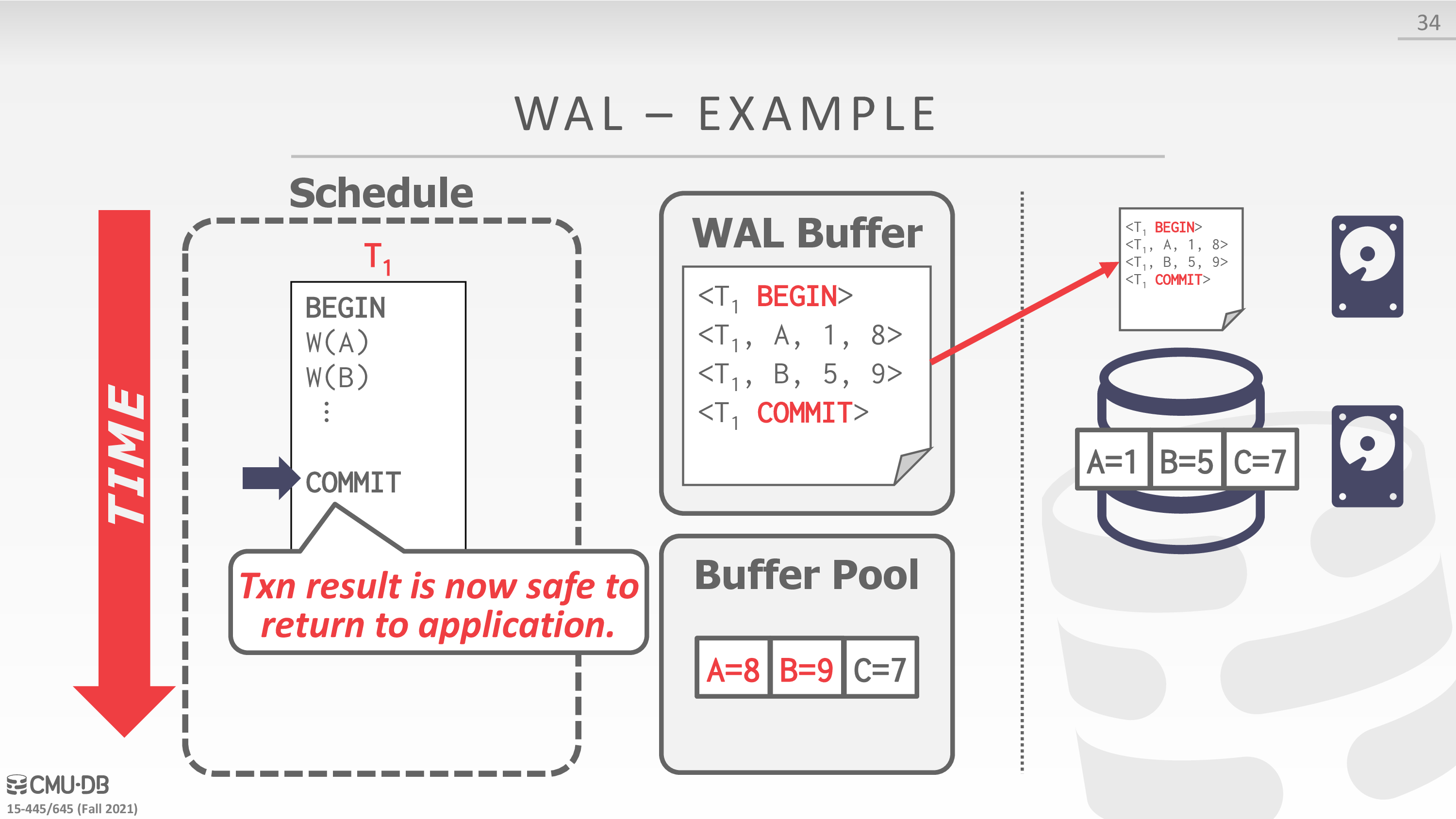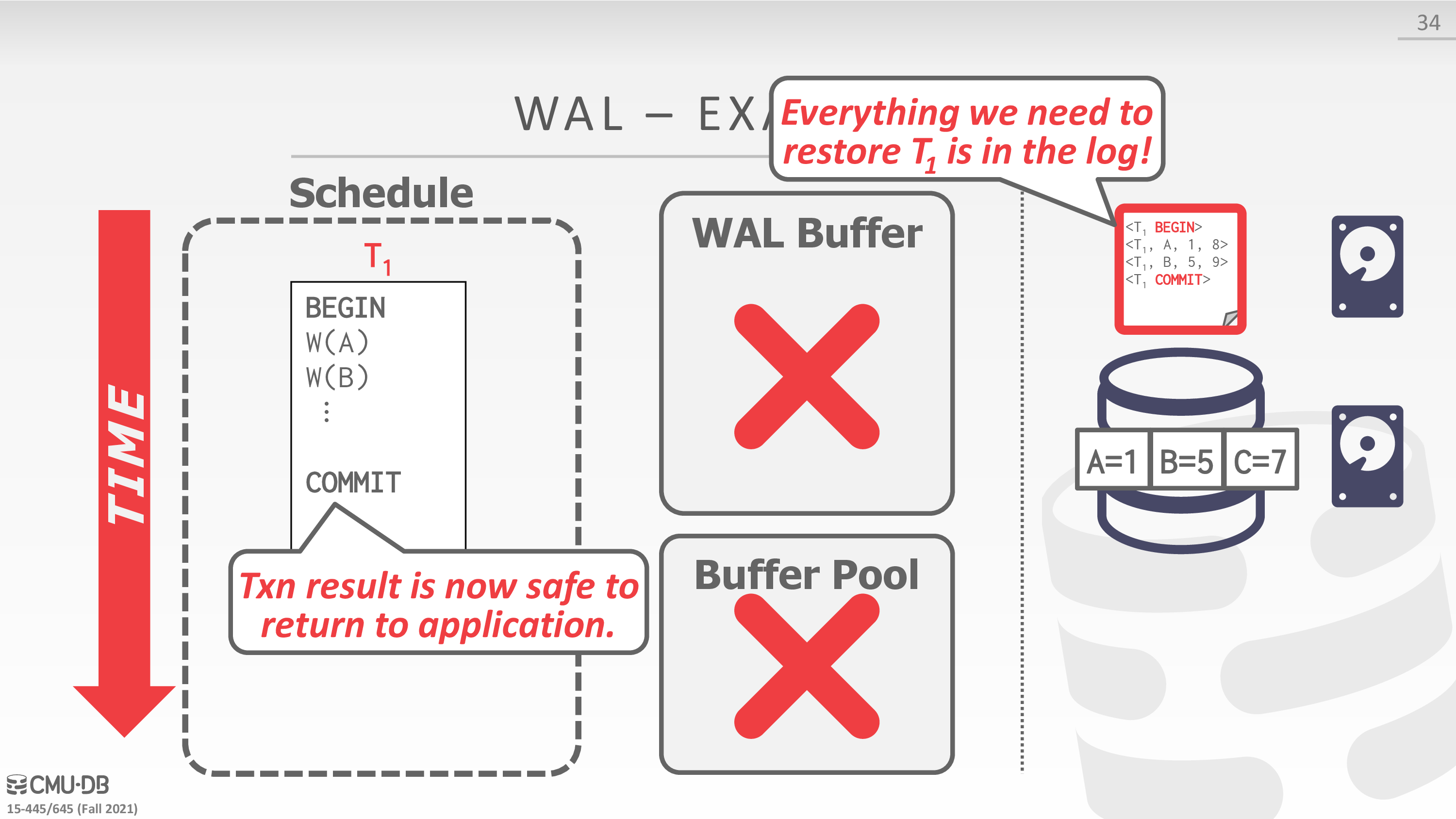
在实现中,可以考虑 group commit,即一个 txn 将要 commit 时,等待其余 txns commit,从而将 wal buffer 一起刷盘
当然等待时间需要设定一个上限
Logging Schemes
- Physical Logging
- Record the changes made to a specific location in the database
- Example: git diff
- Logical Logging
- Record the high-level operations executed by txns
- Example: The UPDATE, DELETE, and INSERT queries invoked by a txn
上述两种方案均存在一定的问题
- 物理日志会显式记录 offset,若 offset 在 clean 的过程中发生了变化,日志就失效了
- 逻辑日志对于并发的事务难以正确的恢复
所以一般将两种混合使用,即 Physiological Logging
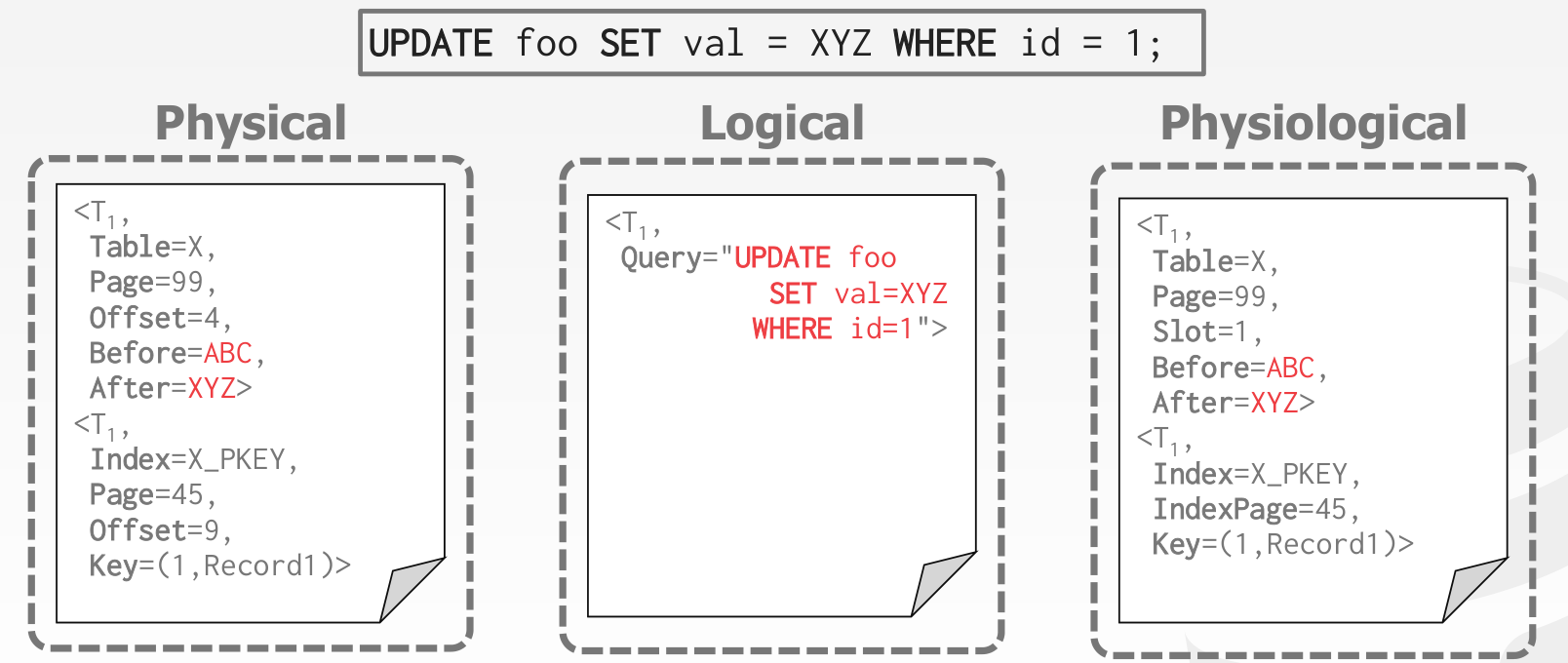
一个实际的例子,nanodb 的 wal 格式可以参考 http://courses.cms.caltech.edu/cs122/javadoc/edu/caltech/nanodb/storage/writeahead/package-summary.html
Checkpoints
用于提升 STEAL + NO-FORCE 策略的 Recovery 性能
Consistent Checkpoint 是最朴素的实现,步骤如下:
- 禁止新事务启动,等待正在执行的事务结束 (停服)
- 遍历 Buffer Pool,将所有 Dirty Page 刷盘
- 记录一条 Checkpoint Log
- 允许所有事务正常执行 (恢复服务)
Recovery 直接从 Checkpoint Log 开始,之前的 Log 一律跳过。
为什么可以跳过之前的 Log?因为 Consistent Checkpoint 先停服然后把所有 Dirty Page 刷盘,保证了 Checkpoint Log 之前的所有 Log 对应的 Page 的改动已经被刷到了磁盘上,并且这些 Page 不包含未提交的数据,不需要再考虑 Redo 或者 Undo,它们的 Log 自然也就不再关心了。
为什么需要停服?如果不停服,并发事务的 Log 可能有一部分在 Checkpoint Log 前,一部分在 Checkpoint Log 后。按照 Recovery 从 Checkpoint Log 开始的规则,并发事务的一部分更新不会被处理,可能导致数据不一致。
虽然 Consistent Checkpoint 解决了上面提到的 Log 制造出的的两个问题,但是它的性能很糟糕。为了做 Checkpoint 而使数据库停服不可接受。ARIES 提出了一种 Fuzzy Checkpoint 的方案,实现了在线 Checkpoint,下文会详细介绍。
Database Recovery
Recovery algorithms have two parts:
- Actions during normal txn processing to ensure that the DBMS can recover from a failure.
- Actions after a failure to recover the database to a state that ensures atomicity, consistency, and durability.
上一节主要讲了第一部分
这一节主要讲第二部分,其核心是 Algorithms for Recovery and Isolation Exploiting Semantics (ARIES)
下面是一些参考资料
- https://web.stanford.edu/class/cs345d-01/rl/aries.pdf
- https://hhwyt.xyz/2021-11-29-aries/
- https://en.wikipedia.org/wiki/Algorithms_for_Recovery_and_Isolation_Exploiting_Semantics
ARIES 的核心思想如下
- WAL with STEAL + NO-FORCE
- 我们要 Runtime 性能
- Repeating history during redo
- Recovery 期间做 Redo 的时候重放历史,无论是已提交,未提交还是已回滚的事务,都要 Redo 一遍
- Logging changes during undo
- 在事务回滚做 Undo 的时候,要为 Undo 产生的更新操作记录 Redo Log
Log Sequence Numbers
每条 log 都记录了一个全局单调递增的字段 lsn
系统中存在下述一些 lsn

page x 能够写入磁盘的条件是,其对应的 page lsn <= flushed lsn,即 wal 的要求
Normal Commit & Abort Operations
Each txn invokes a sequence of reads and writes, followed by commit or abort.
Assumptions in this lecture:
- All log records fit within a single page.
- Disk writes are atomic.
- Single-versioned tuples with Strict 2PL.
- STEAL + NO-FORCE buffer management with WAL.
Transaction Commit
- Write COMMIT record to log.
- 日志落盘
- All log records up to txn’s COMMIT record are flushed to disk.
- When the commit succeeds, write a special TXN-END record to log.
- 数据落盘
下面是一个例子
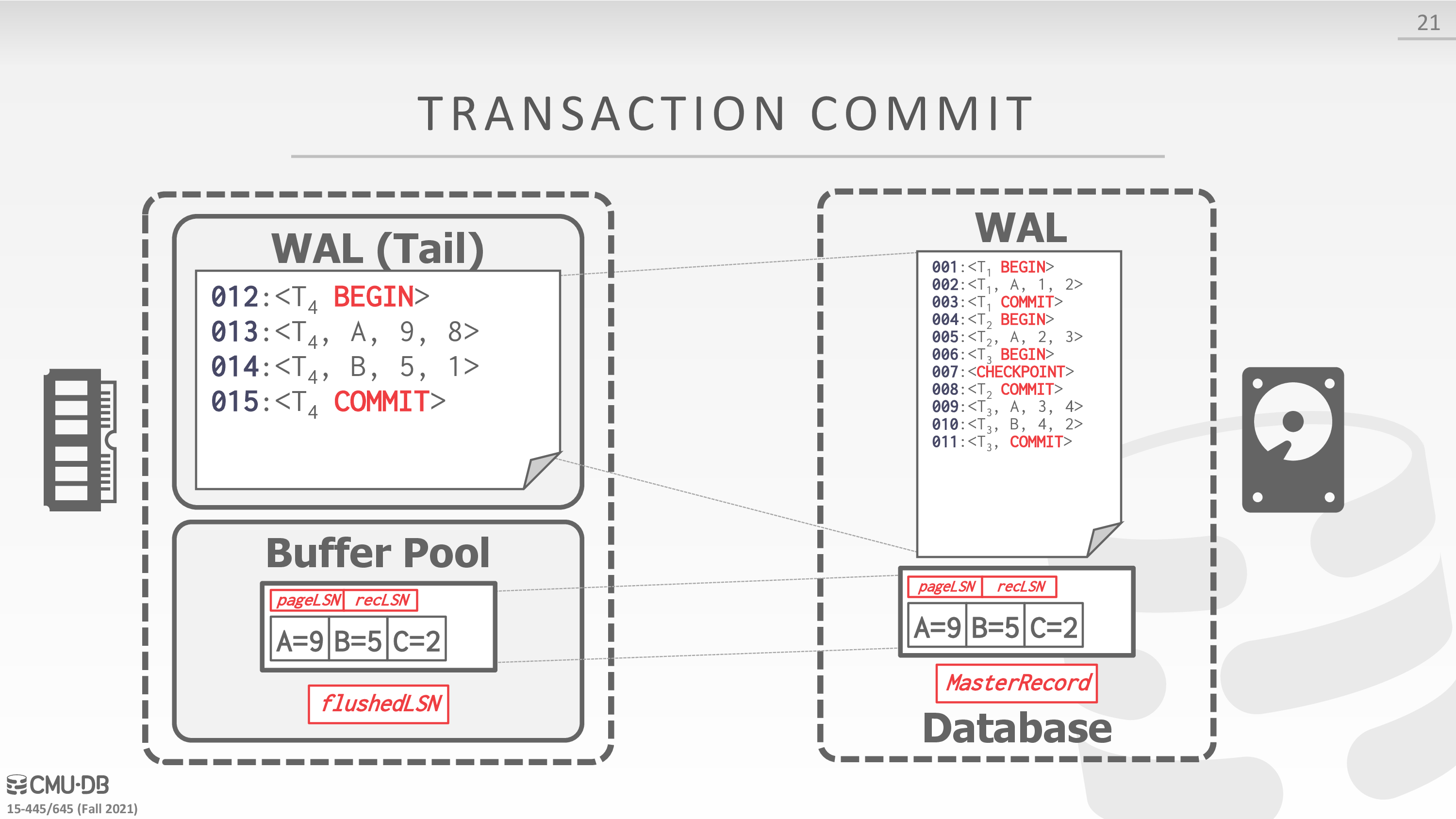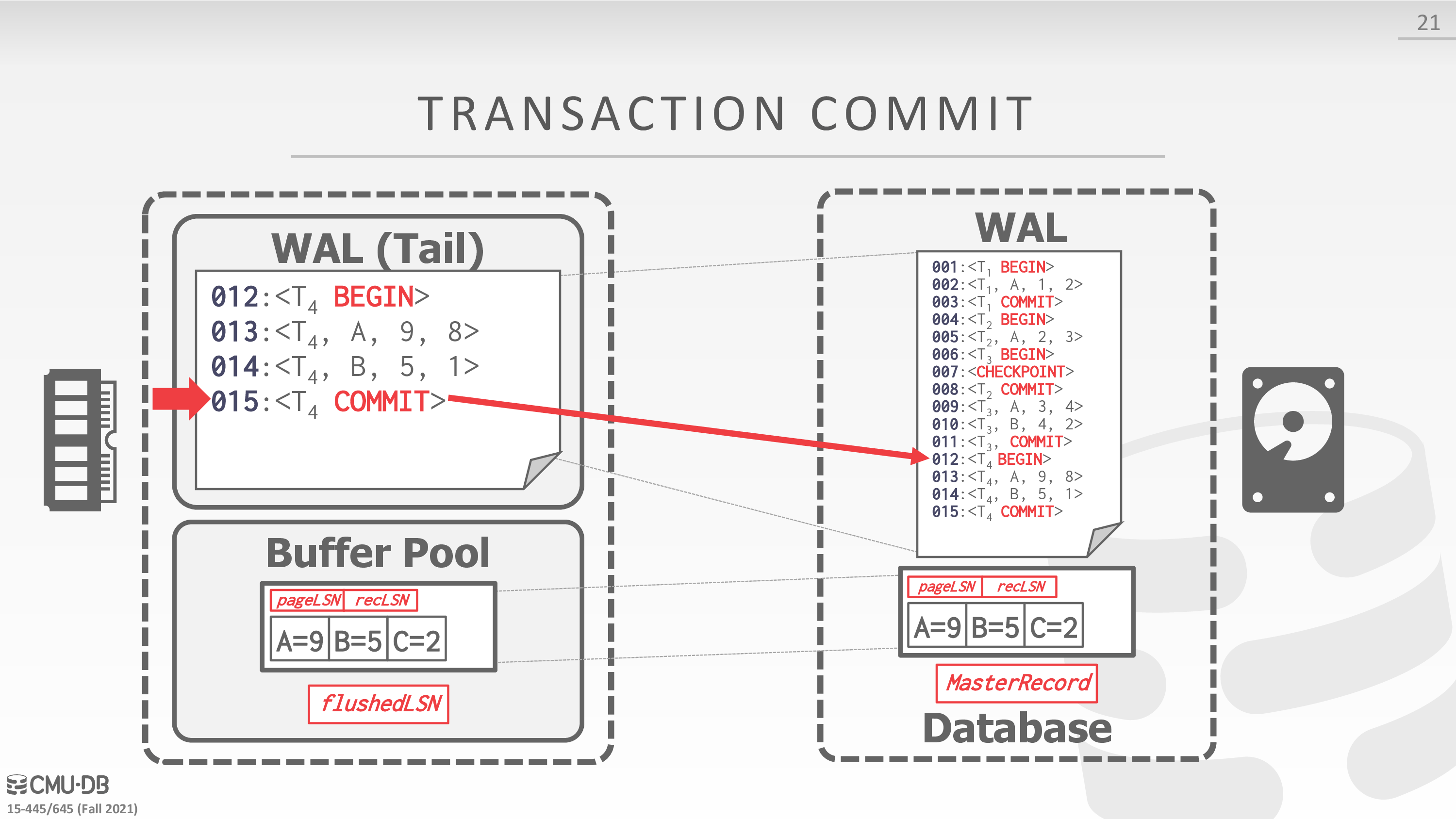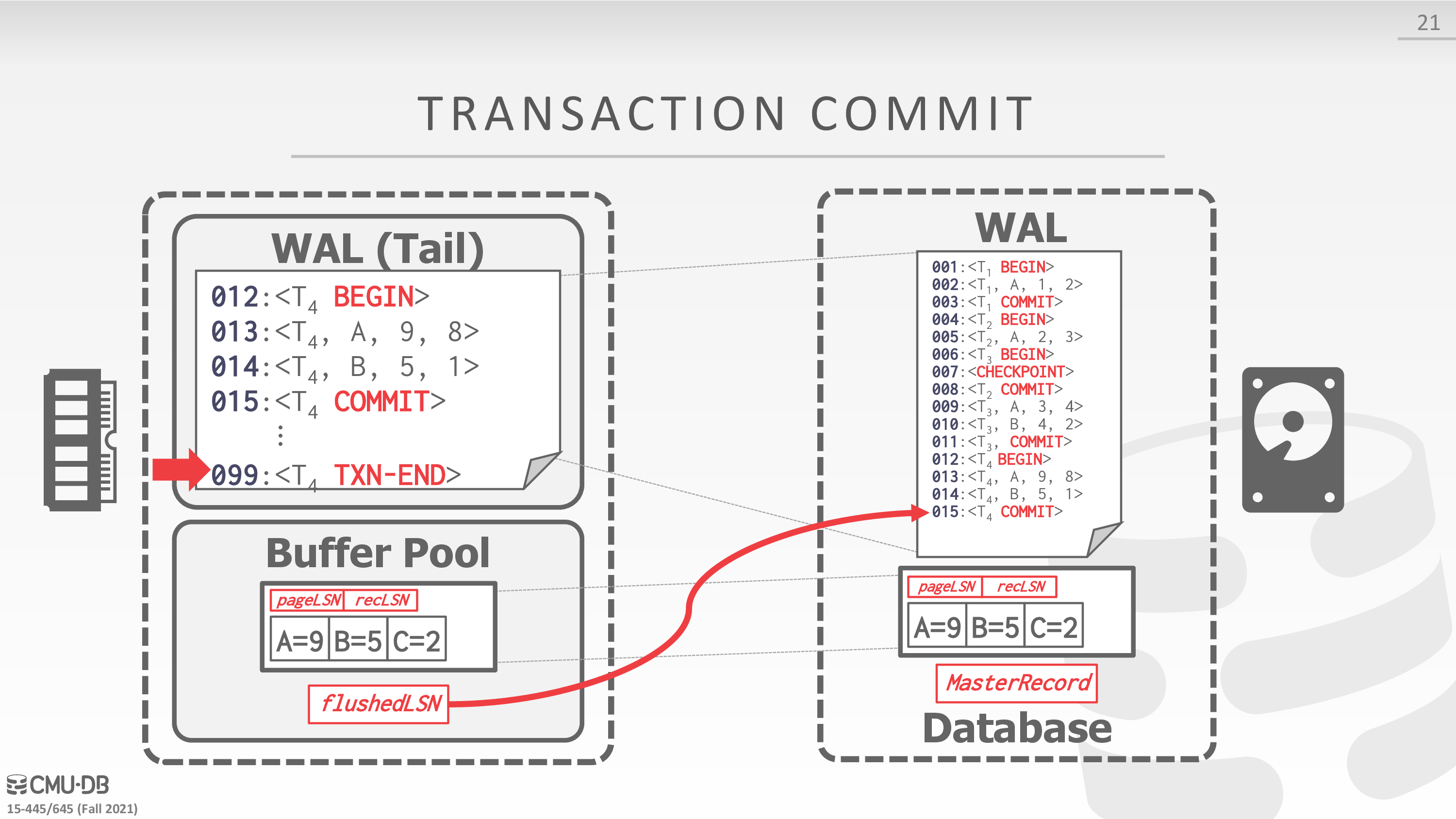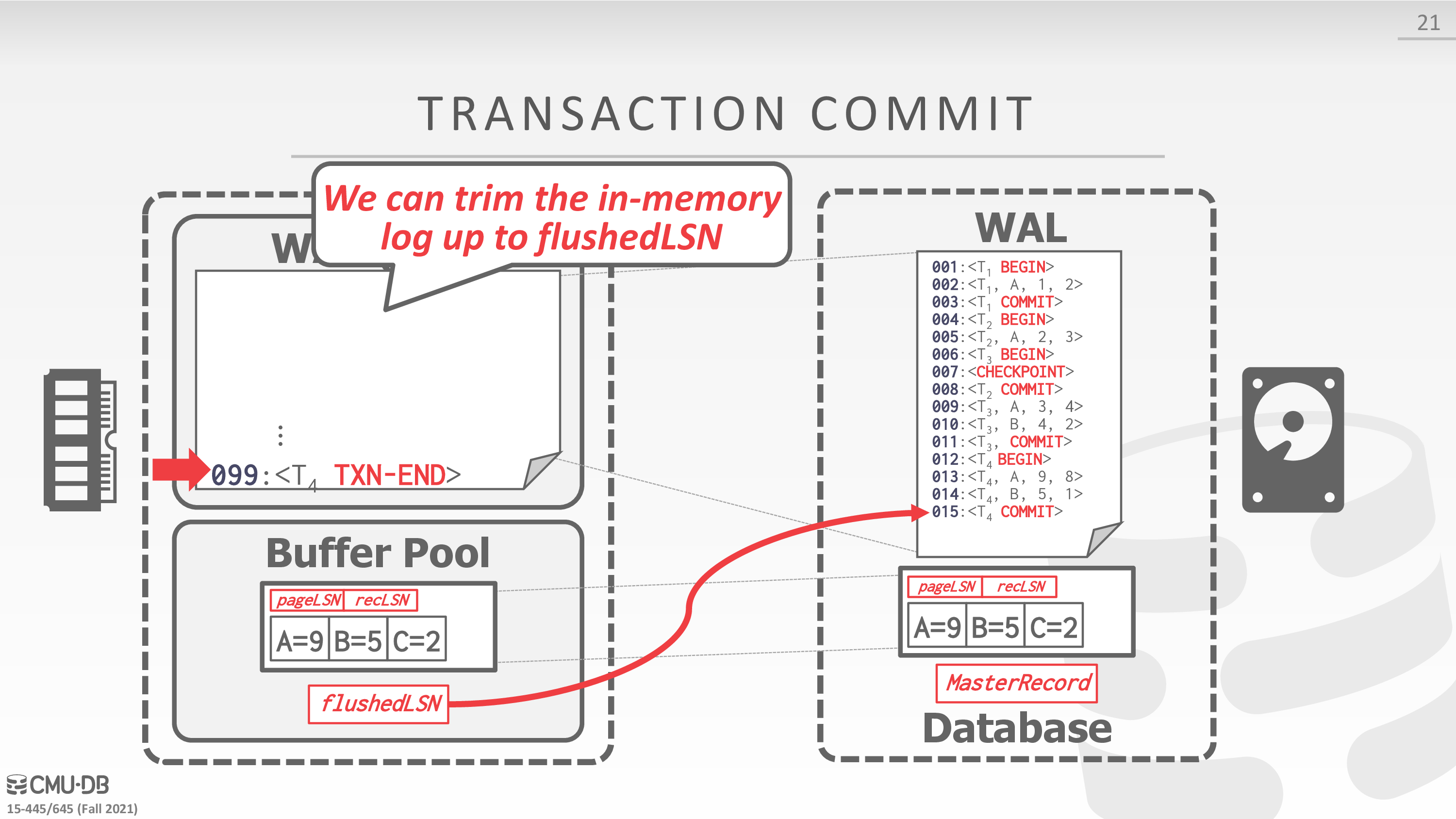
Transaction Abort
- First write an ABORT record to log for the txn.
- Then play back the txn’s updates in reverse order. For each update record:
- Write a CLR entry to the log.
- Restore old value.
- At end, write a TXN-END log record.
CLR:全称是 Compensation Log Record,中文一般翻译为补偿日志。由于 ARIES 采用 Logical Undo,Undo 操作不是幂等的,不可以重复执行。我们通过为 Undo 操作记录 Redo Log 来物化 Undo 操作,同时记录 Undo 的进展(通过 UndoNextLSN 的实现,见下面介绍),保证已经 Undo 了的操作不会再被 Undo。Undo 产生的这些 Redo Log 就叫做 CLR。此外,CLR 是 Redo-Only 的,不支持 Undo,这一特点保证了 Undo 是有界的,Recovery 期间 Undo 过程中挂掉并不会增加 Undo 的工作量。
下面是一个例子
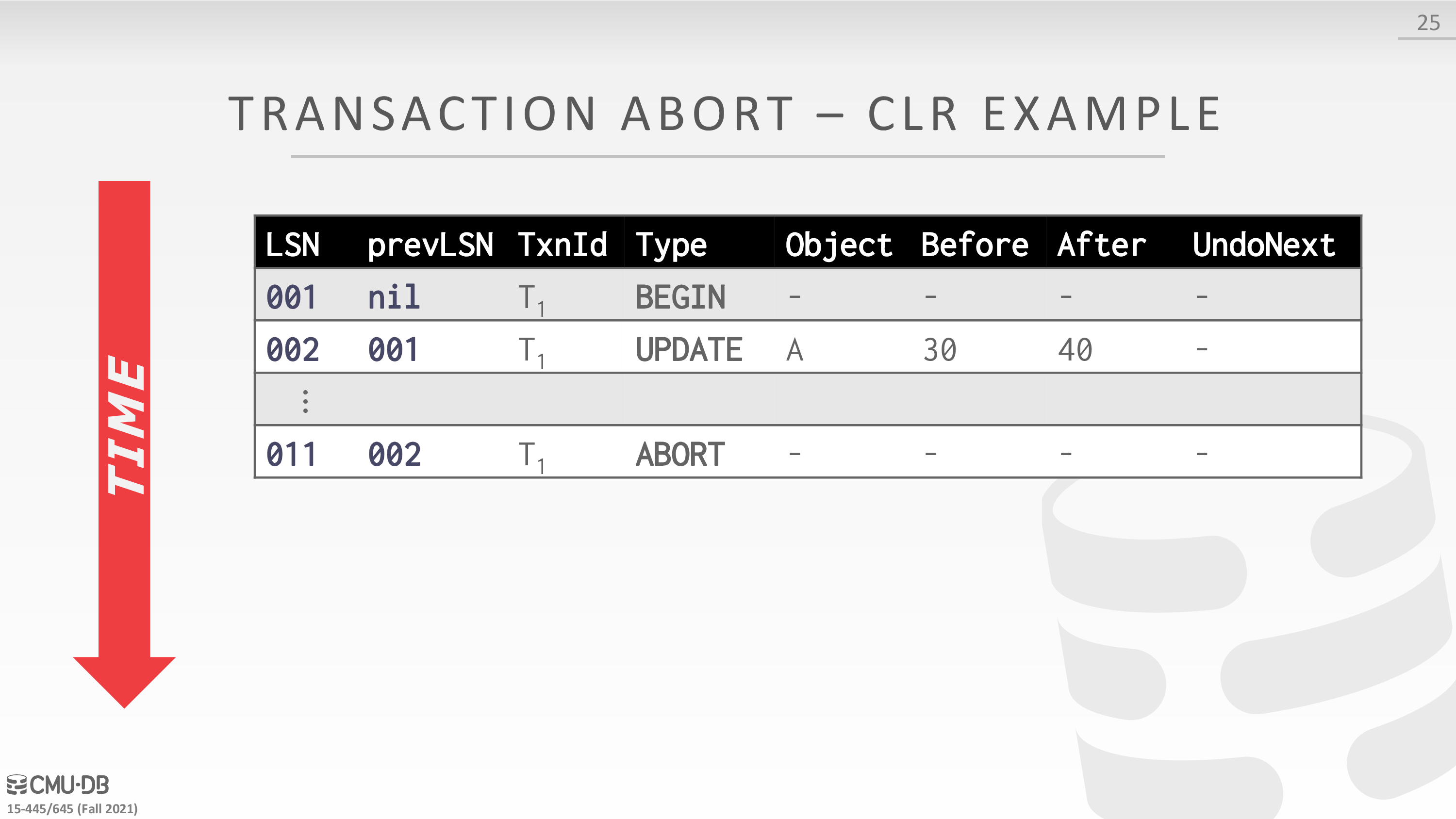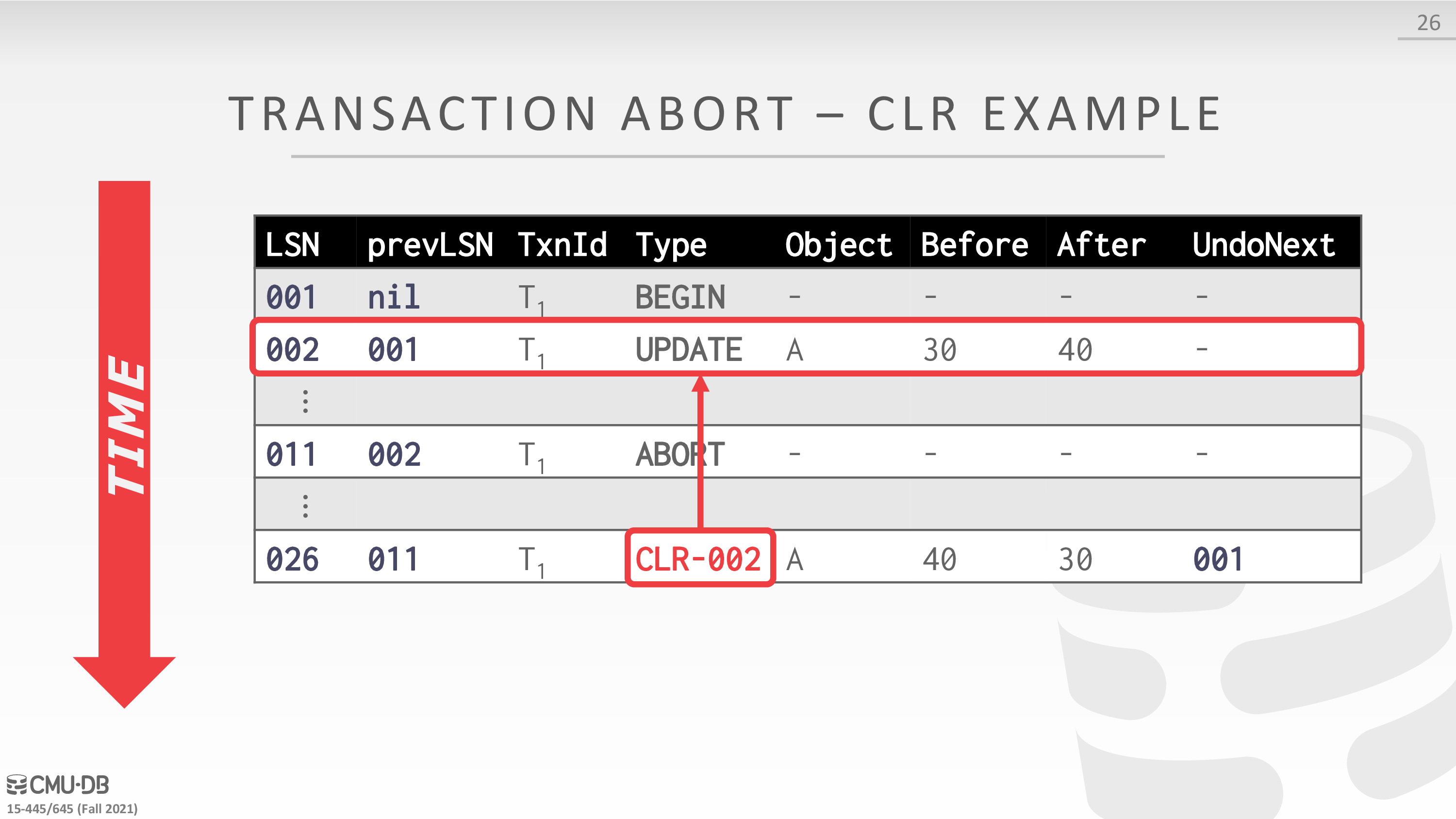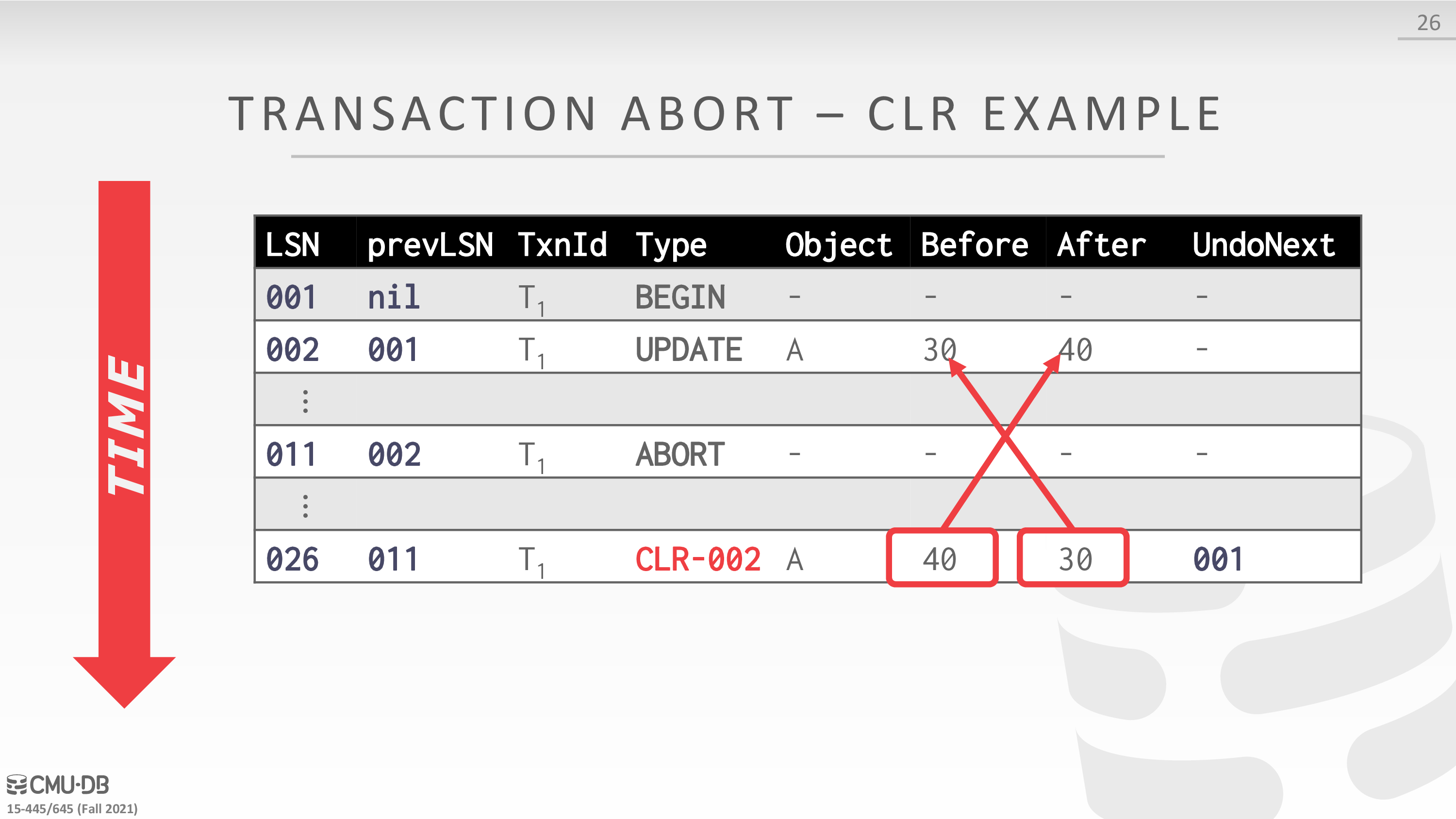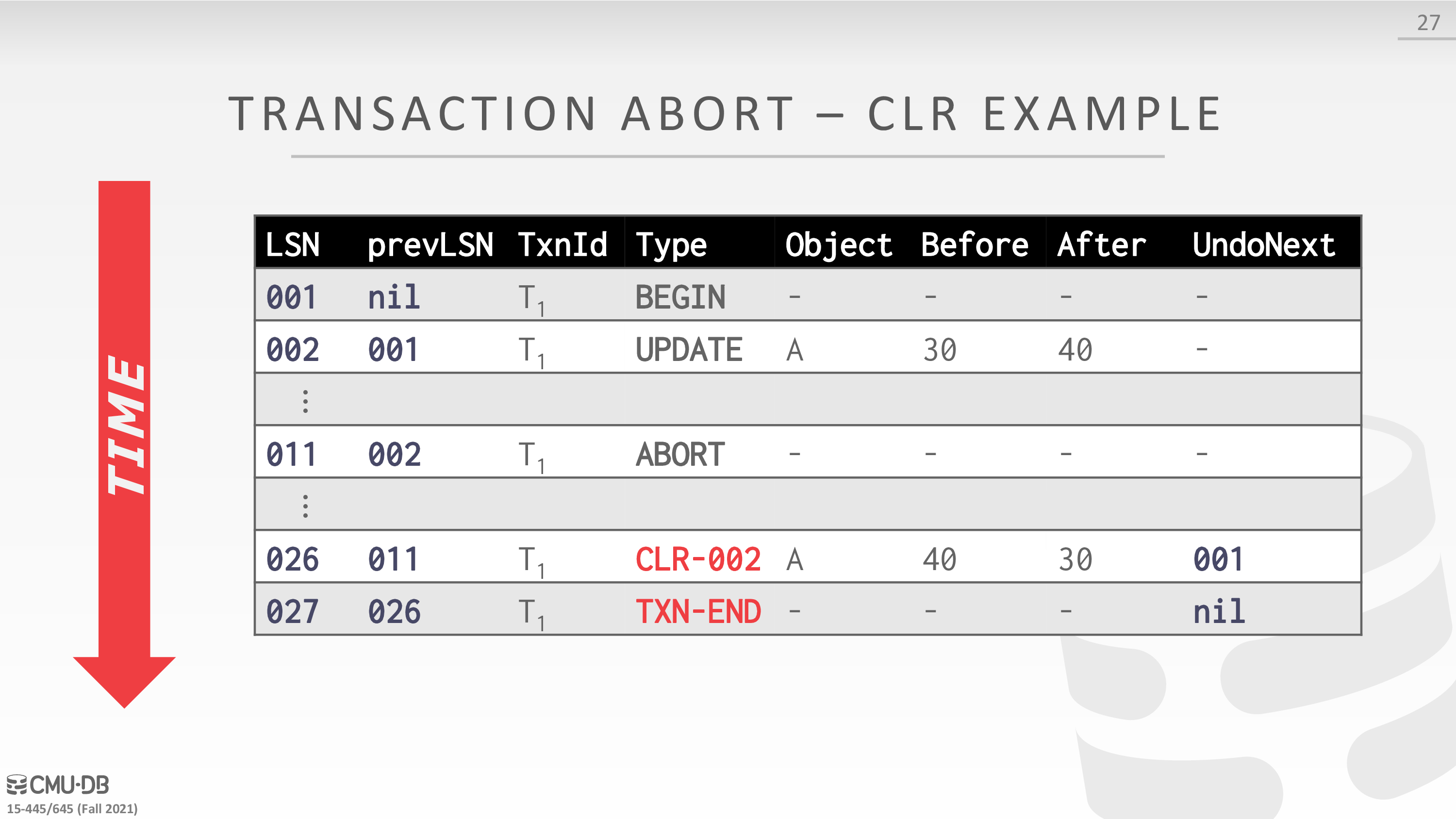
分析一下这里的日志格式
- Prev LSN:同一个事务中后一条 Log 会把前一条 Log 的 LSN 记录在 Log Header 的 Prev LSN 字段中,形成一个反向链表,便于 Undo 时逆序回溯事务的 Log。
- UndoNext LSN:每条 CLR 中都会记录 UndoNext LSN,用来指示下一条需要 Undo 的 Log 的 LSN。如果 Undo 到一半数据库挂掉后重启,我们在重新执行 Undo 时,只需先取出最后一条 CLR Log 的 UndoNext LSN,就能继续之前的 Undo 工作。
Recovery Algorithm
Recovery with Consistent Checkpoint
需要先引入两个概念
- ATT:全称是 Active Transaction Table。记录了所有活跃事务(事务在执行中,还没有提交或回滚)以及它们的状态(Undo Candidate,Committed,下文会介绍)和 Last LSN。它是内存中的一个数据结构。
- DPT:全称是 Dirty Page Table。记录了所有的 Dirty Page 以及它们的 Rec LSN。它也是一个内存中的数据结构。
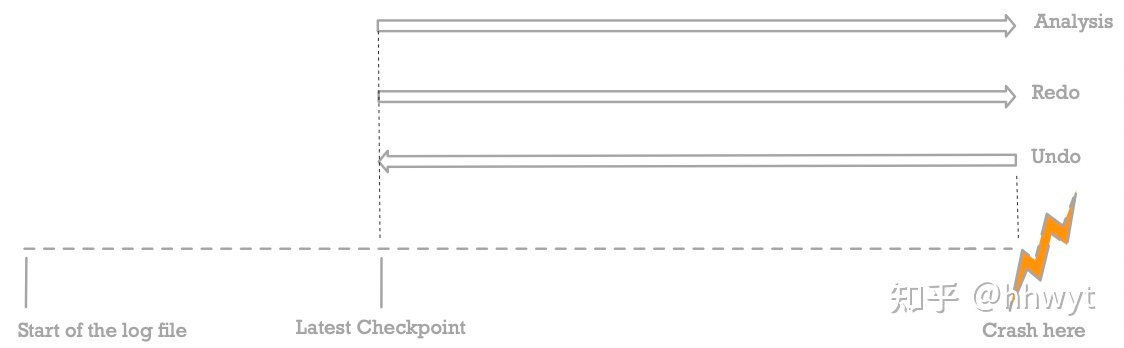
上图是 ARIES 的 Recovery 流程,Checkpoint 采用 Consistent Checkpoint 方案。虚线是我们的 Log,按时间顺序从左到右排列。我们从左往右看,最左侧是 Log 的起始位置,中间有做过一次 Checkpoint,最右侧是数据库挂掉时最新的 Log 的位置。从图中可以看到 Recovery 的三个阶段,对应三个长箭头,箭头的方向表示该阶段扫描 Log 的方向,箭头向右表示顺序扫描,向左表示逆序扫描。
接下来详细介绍一下这三个阶段:
- Analysis
- 从 Master Record 的位置开始,顺序扫描所有 Log,恢复出 ATT 和 DPT
- ATT:对任意一个事务 Ti,如果
- 遇到 Ti 的 Begin Log,就把 Ti 加入 ATT,同时把状态设为 Undo Candidate
- 遇到 Ti 的 Commit Log,就把 ATT 中的 Ti 状态设为 Committed
- 遇到 Ti 的 End Log,就把 Ti 从 ATT 中移除
- 遇到 Ti 的其他 Log (即 Redo / Undo / CLR / Abort Log),更新 Ti 的 Last LSN
- 这里的 Redo Log 和 Undo Log 就是普通的 Log,记到同一条中
- DPT:遇到任意 Redo Log 或 CLR,如果对应的 Page
- 不在 DPT 中:将它加入 DPT,同时记录 Rec LSN
- 已经在 DPT 中:无需处理
- ATT:对任意一个事务 Ti,如果
- 从 Master Record 的位置开始,顺序扫描所有 Log,恢复出 ATT 和 DPT
- Redo
- 找到 DPT 中最小的 Rec LSN,将它作为起始点,顺序扫描 Log 并处理来重放历史
- 实际上就是 Redo 所有事务的 Redo Log 以及 CLR 对应的更新操作
- 当且仅当 Log LSN > Page LSN,一个 Log 对应的更新操作才能在对应的 Page 上 Redo
- 由于 Buffer Pool 可能在 Checkpoint 后对 Page 进行刷盘,所以 Log LSN < Page LSN 的可能性是很大的
- 为 ATT 中所有状态为 Committed 的事务写一条 End Log,同时把它从 ATT 中移除
- Undo
- 找到 ATT 中最大的 Last LSN,Undo 它对应的事务,Undo 完成后把该事务从 ATT 中移除
- 重复上面步骤,直到 ATT 为空
当上述三个阶段执行完毕,Recovery 流程结束,数据库即可正常对外提供服务。
一个简化的例子可以参考 miniob clog 的实现
Recovery with Fuzzy Checkpoint
如果有了 Fuzzy Checkpoint,Recovery 的三个阶段如下
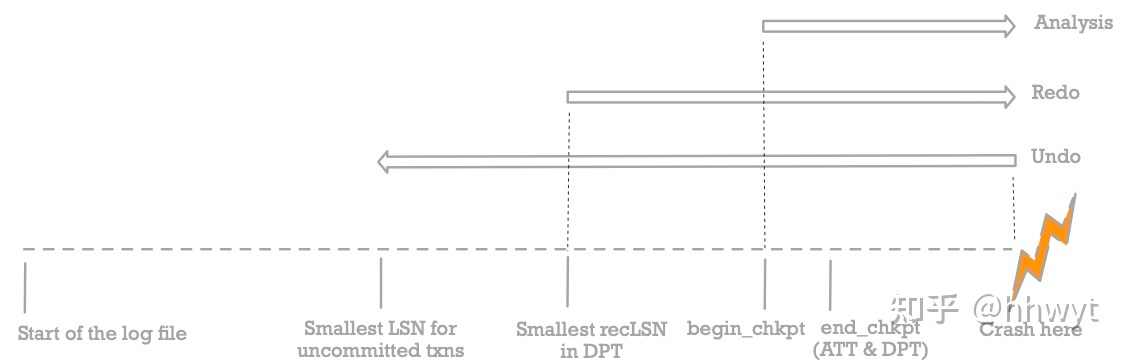
较为复杂,尚未完全理解
Introduction to Distributed Databases
System Architectures
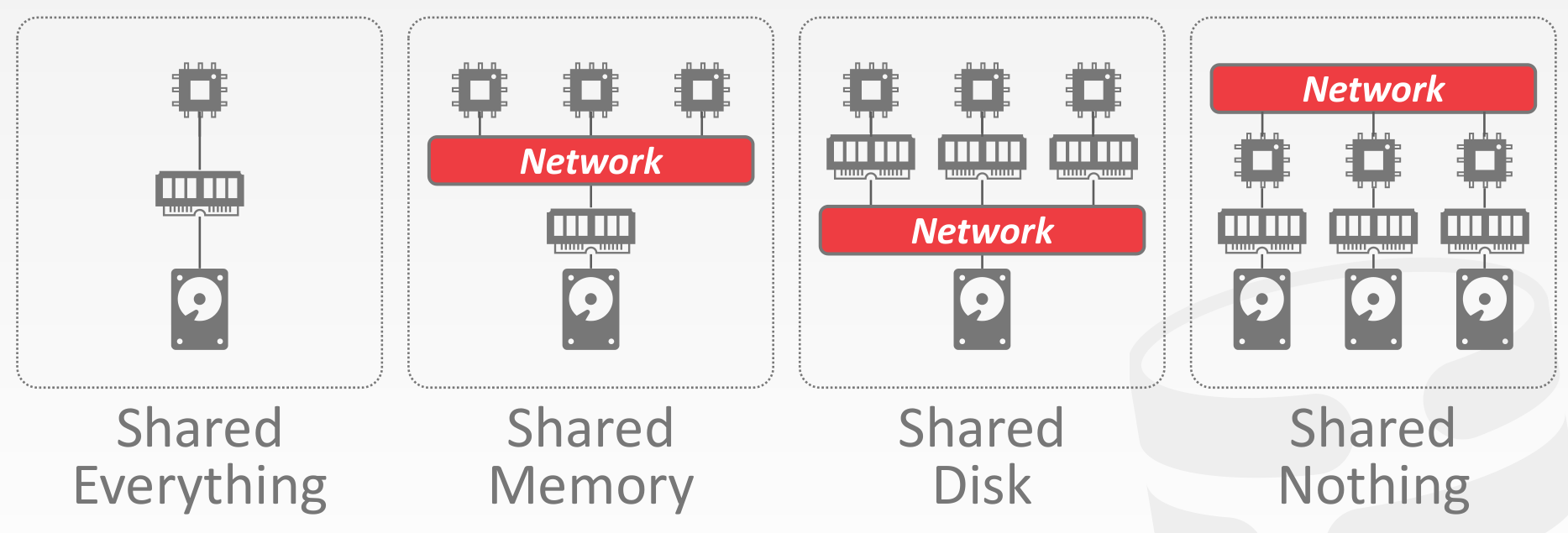
Design Issues
- 应用程序如何查找数据?
- 应该如何对分布式数据执行查询?
- 是否应该将查询推送到数据所在的位置?
- 还是应该将数据集中到一个公共位置以执行查询?
- DBMS 如何确保正确性?
- 同构节点还是异构节点?
- 同构:集群中的每个节点都可以执行相同的任务集(尽管可能在不同的数据分区上),从而很好地适用于无共享架构
- 异构:节点被分配了特定的任务,因此节点之间必须进行通信才能执行给定的任务
Partitioning Schemes
- Logical Partitioning (shared disk architecture)
- Physical Partitioning (shared nothing architecture)
Naive Data Partitioning
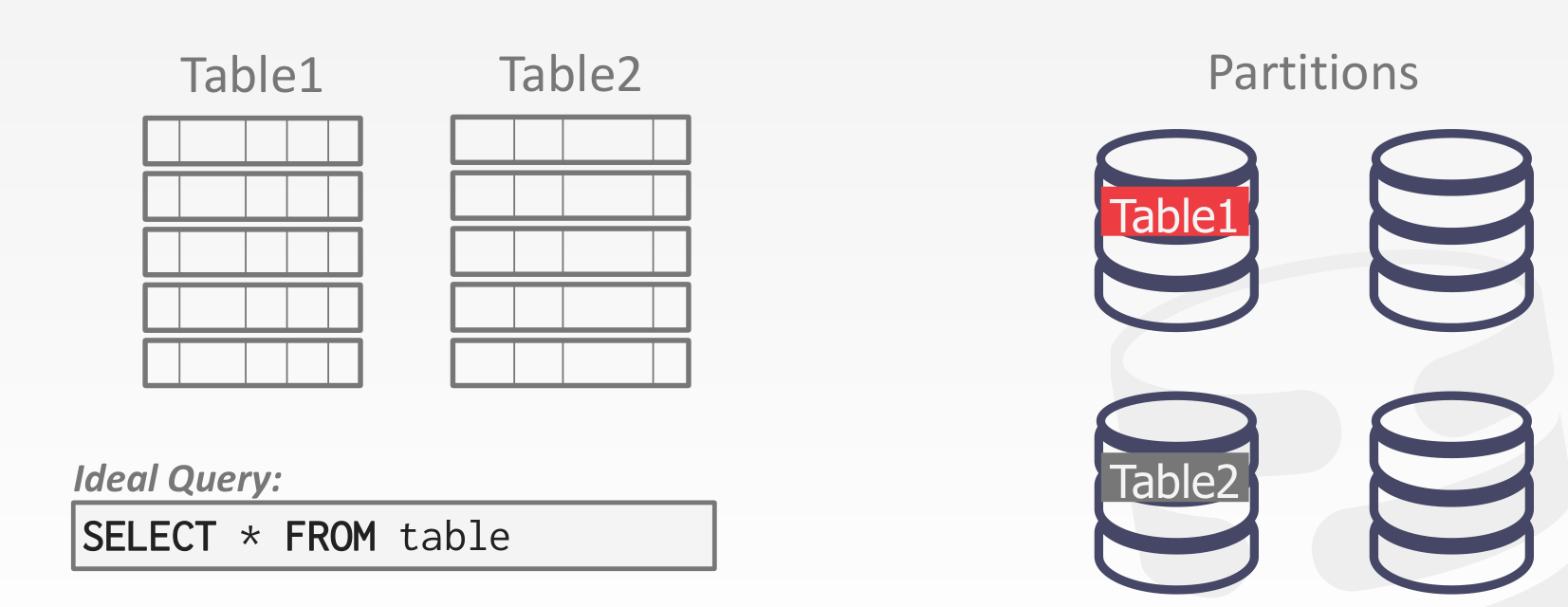
Horizontal Partitioning
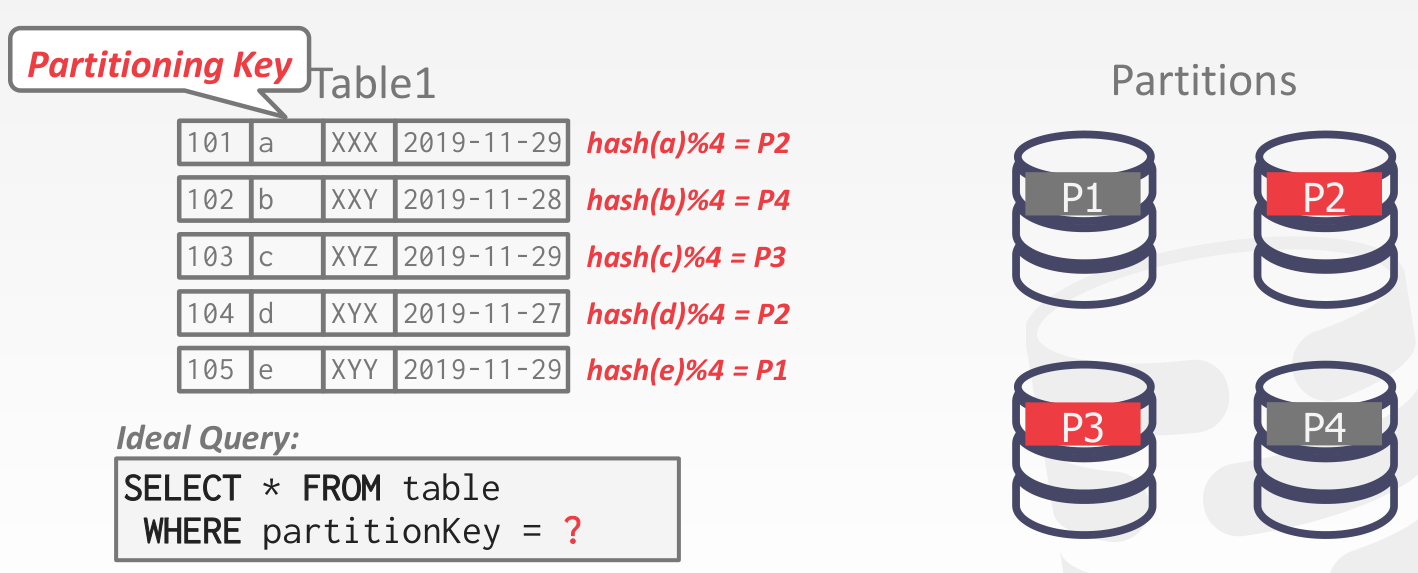
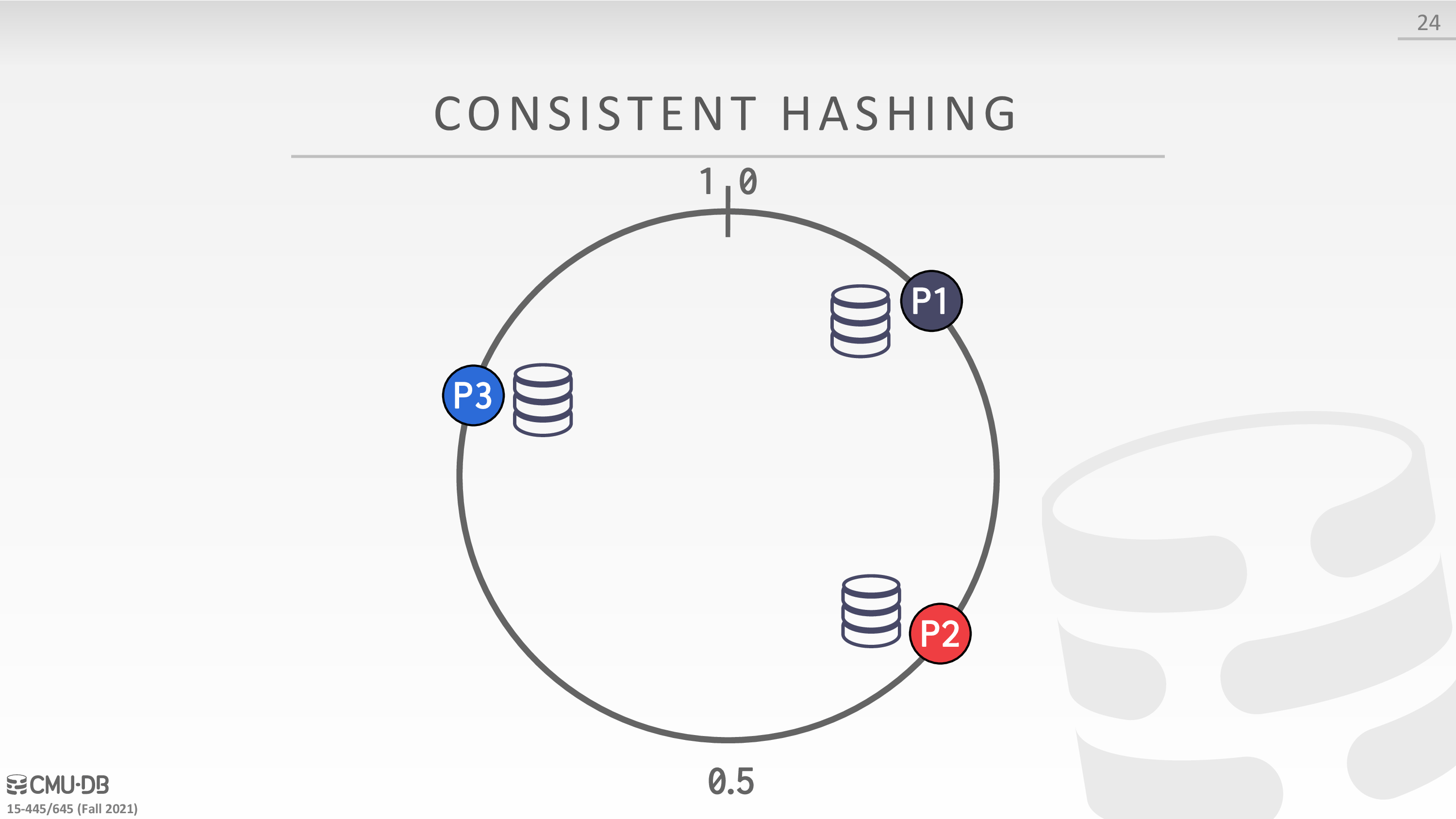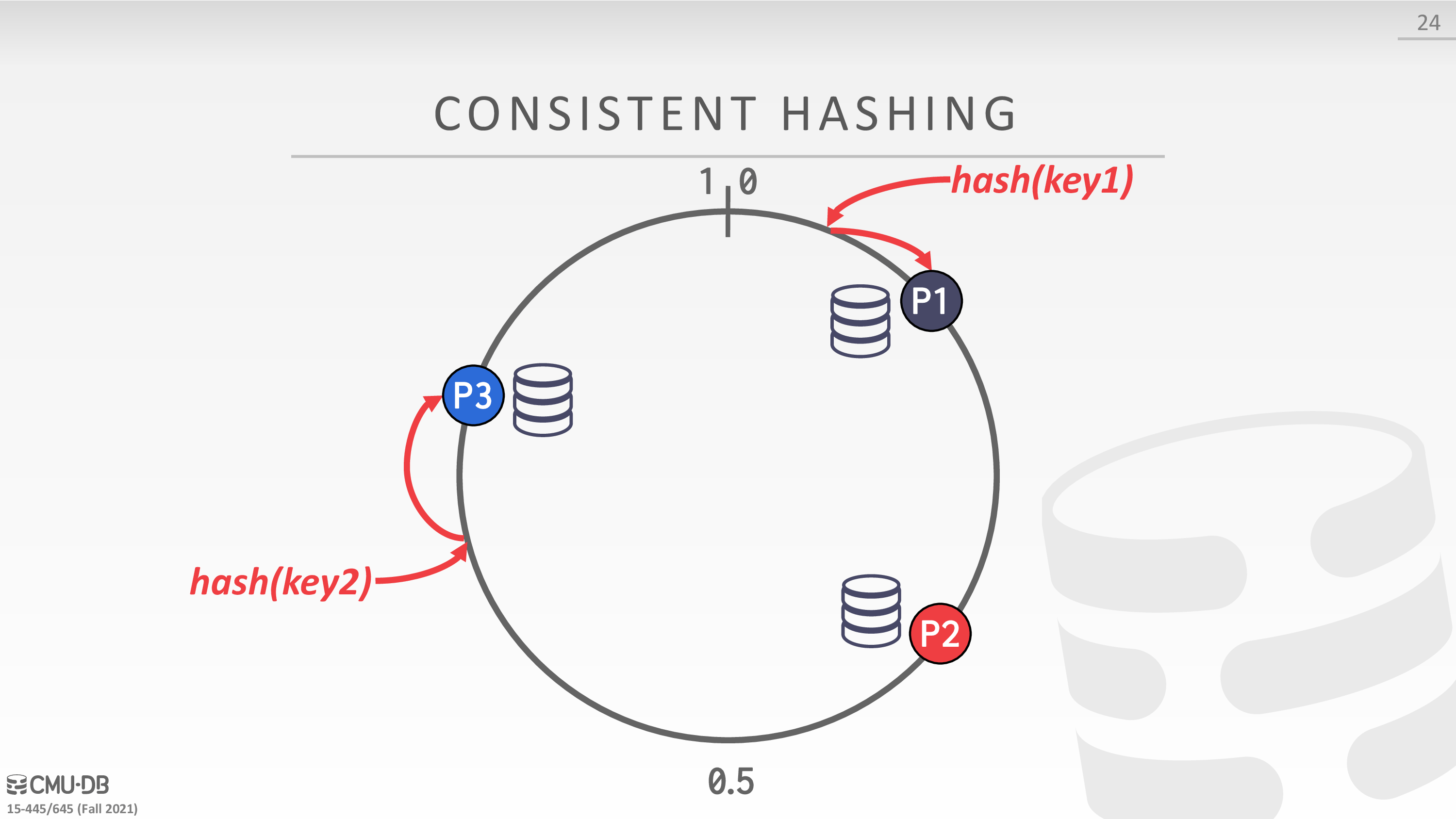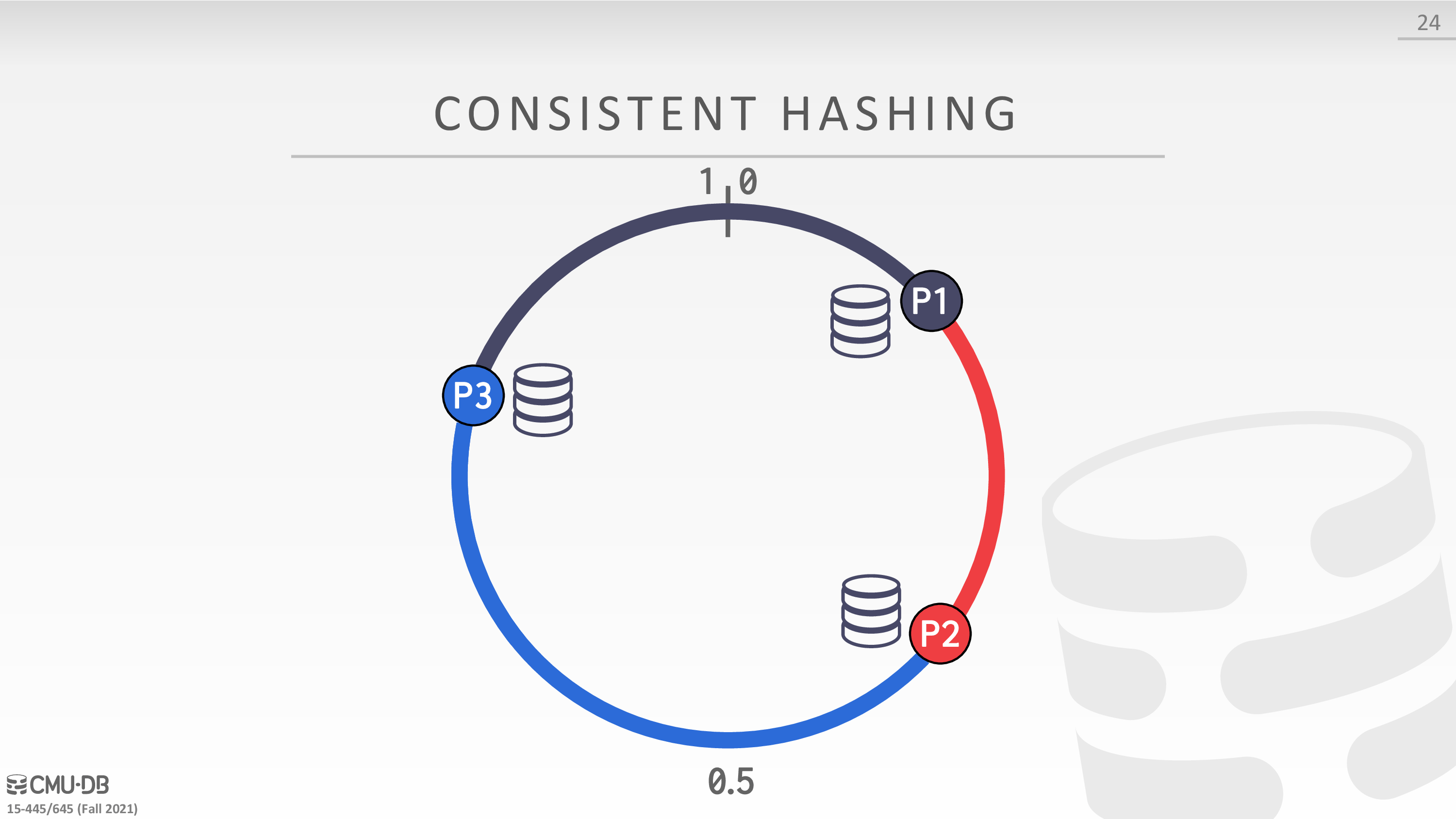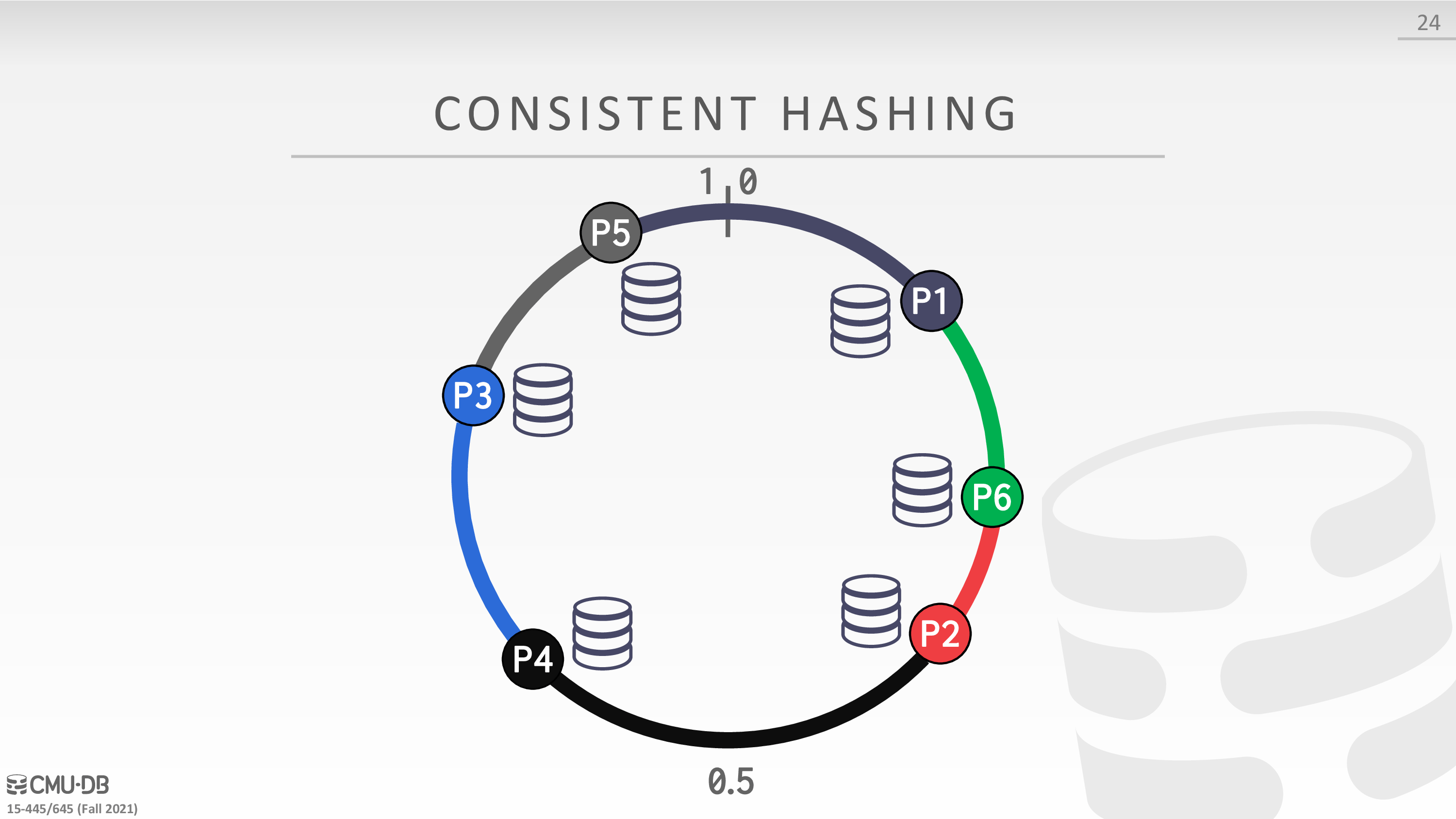
Consistent Hashing
考虑 Horizontal Partitioning 的扩缩容问题
Distributed Concurrency Control
If our DBMS supports multi-operation and distributed txns, we need a way to coordinate their execution in the system.
-
Centralized
- Coordinator
- Middleware
-
Decentralized
- Master Node
Need to allow multiple txns to execute simultaneously across multiple nodes.
Many of the same protocols from single-node DBMSs can be adapted.
This is harder because of:
- Replication.
- Network Communication Overhead.
- Node Failures.
- Clock Skew.
Distributed OLTP Database Systems
We can assume that all nodes in a distributed DBMS are well-behaved and under the same administrative domain.
If you do not trust the other nodes in a distributed DBMS, then you need to use a Byzantine Fault Tolerant protocol for txns (blockchain).
Atomic Commit Protocols
When a multi-node txn finishes, the DBMS needs to ask all the nodes involved whether it is safe to commit.
- Two-Phase Commit
- Three-Phase Commit (not used)
- Paxos
- Raft
- ZAB (Apache Zookeeper)
- Viewstamped Replication
Two-Phase Commit
Paxos
一般用于 replication,协调 txns 用的较少
Replication
可以参考 https://github.com/Vonng/ddia/blob/master/ch5.md
-
Replica Configuration
- Primary-Replica
- Multi-Primary
-
Propagation Scheme
- Synchronous
- Asynchronous
-
Propagation Timing
- Continuous
- On Commit
Consistency Issues (CAP)
https://www.julianbrowne.com/article/brewers-cap-theorem/
给定一致性、可用性、分区耐受性这三个属性,我们只能同时满足其中两个属性
- 可用性:如果客户可以同集群中的某个节点通信,那么该节点就必然能够处理读取及写入操作
- 分区耐受性:如果发生通信故障,导致整个集群被分割成多个无法互相通信的分区时,集群仍然可用
现实含义,当系统可能会遭遇分区状况时,需要在一致性与可用性之间进行权衡
通常来说,我们都会略微舍弃一致性,以获取某种程度的可用性
使用延迟来理解可用性
- 参与交互操作的节点越多,一致性就越好
- 然而,每新增一个节点,都会使交互操作的响应时间变长
- 可用性可以视为能够忍受的最大延迟时间,一旦延迟过高,我们就放弃操作,并认为数据不可用
Federated Databases
Distributed architecture that connects together multiple DBMSs into a single logical system.
A query can access data at any location.
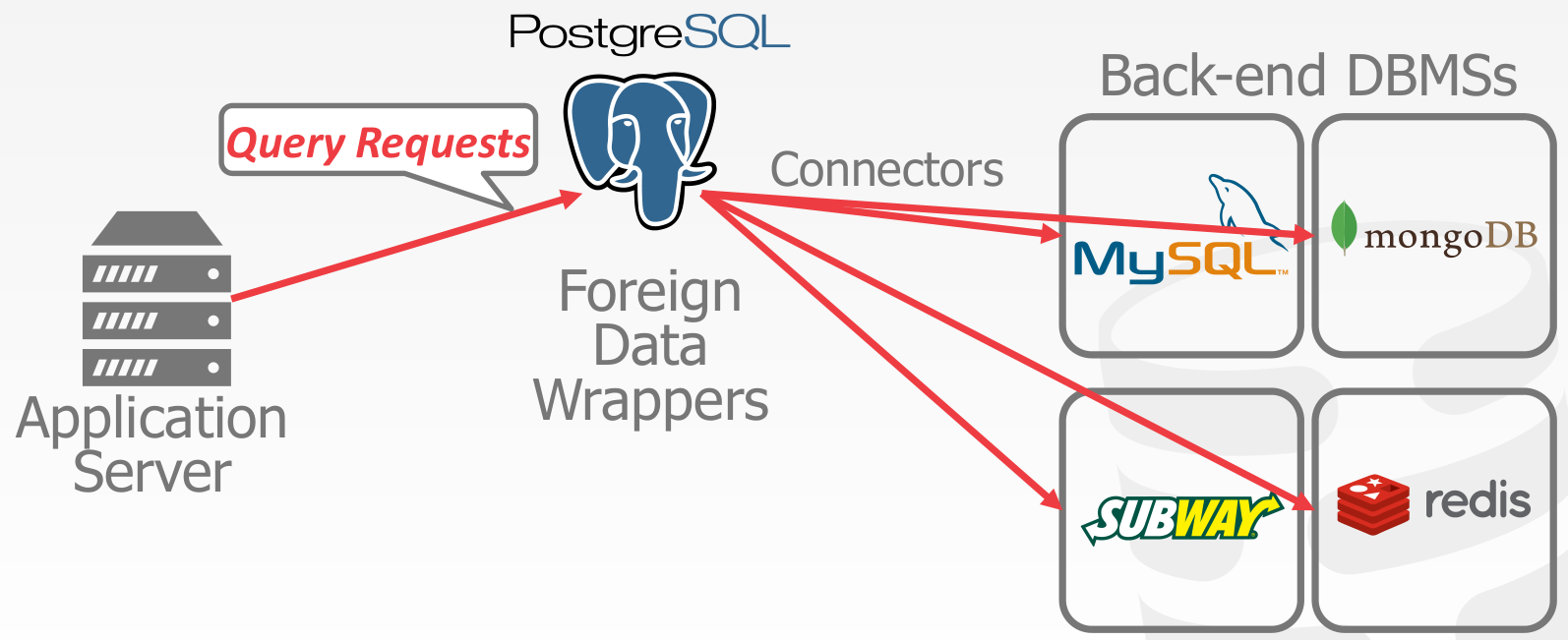
Distributed OLAP Database Systems
- Extract Transform Load (ETL)
- Star Schema vs. Snowflake Schema
- Normalization
- Query Complexity
Execution Models
- Push Query to Data
- Pull Data to Query
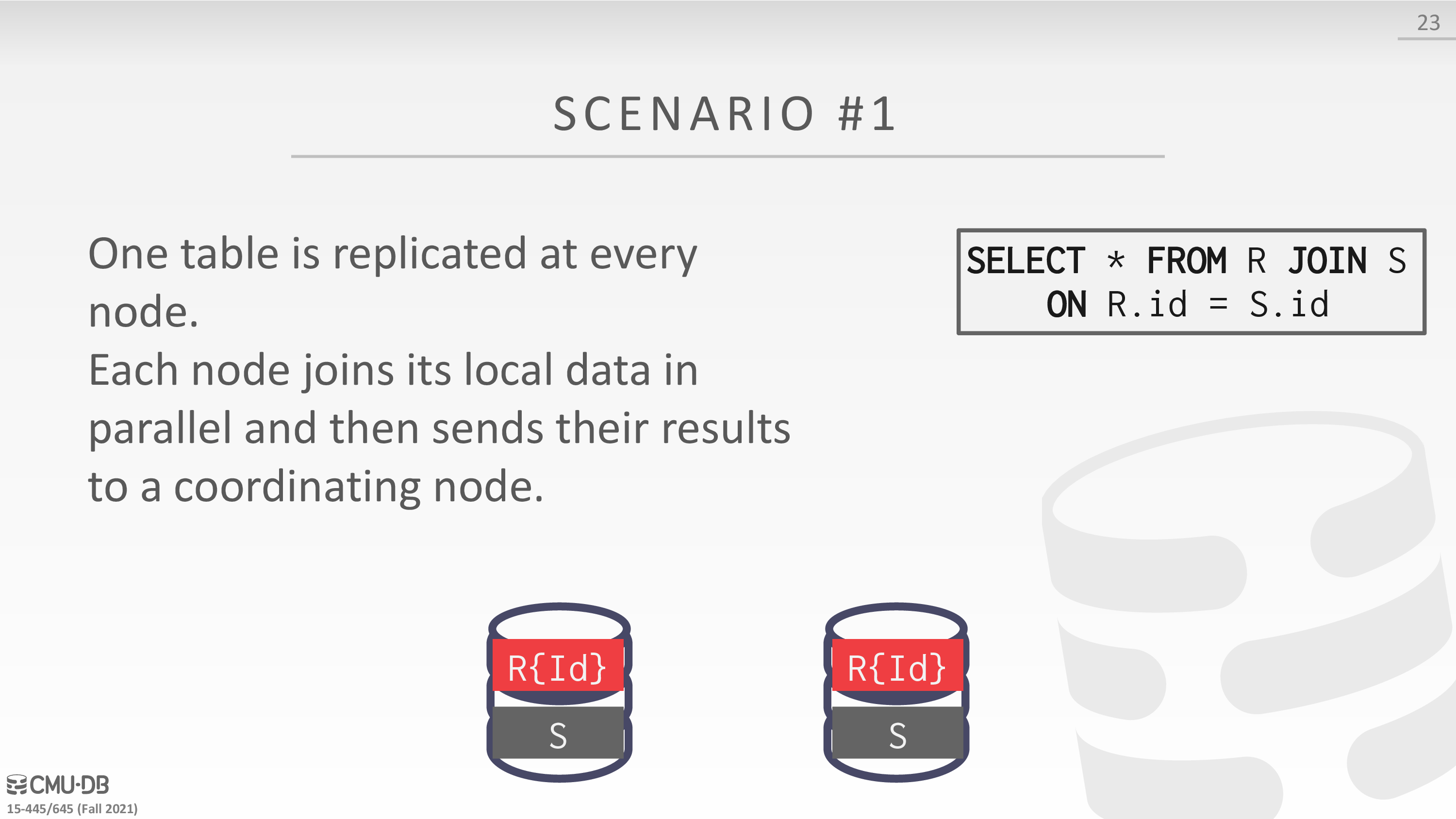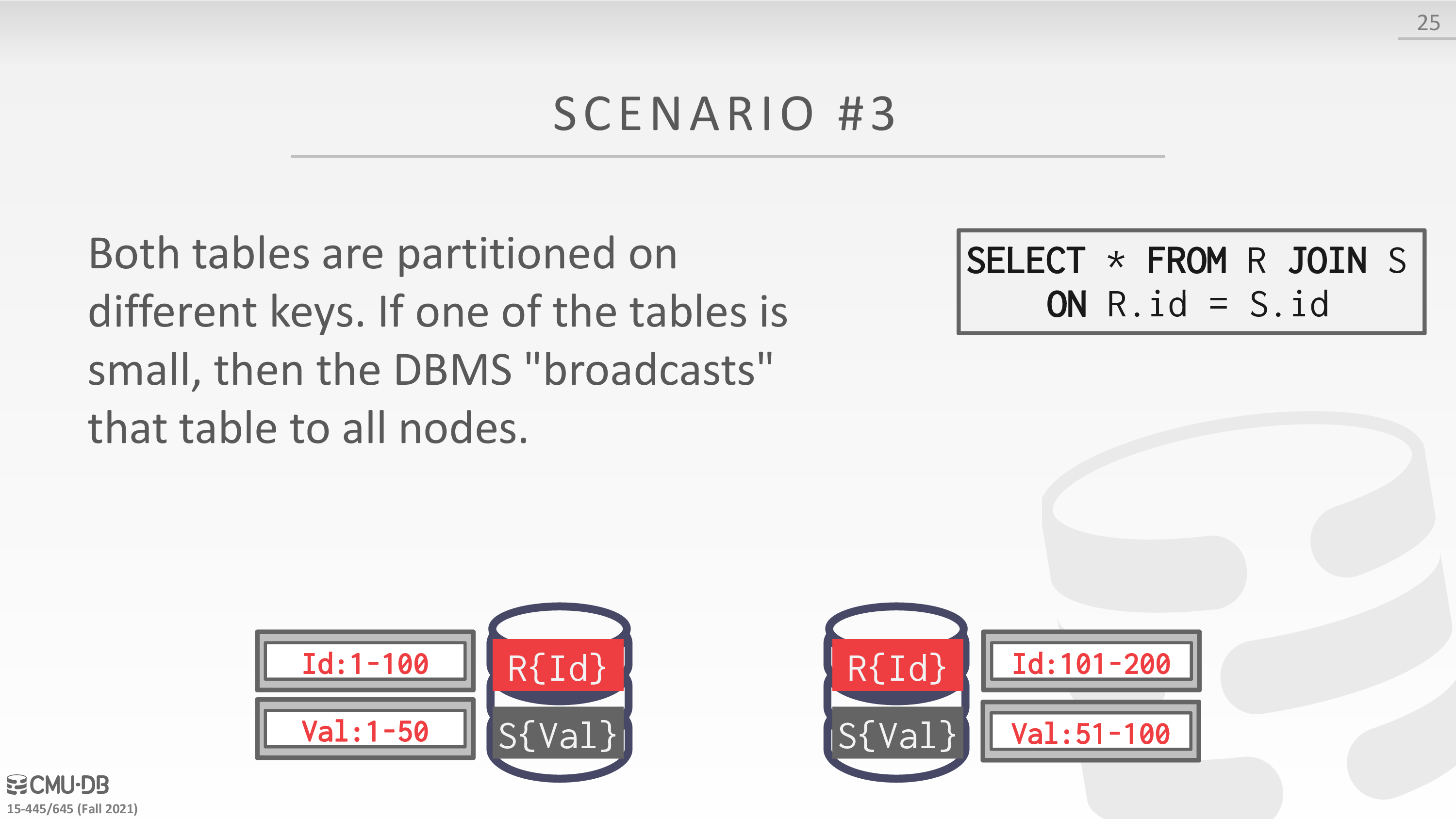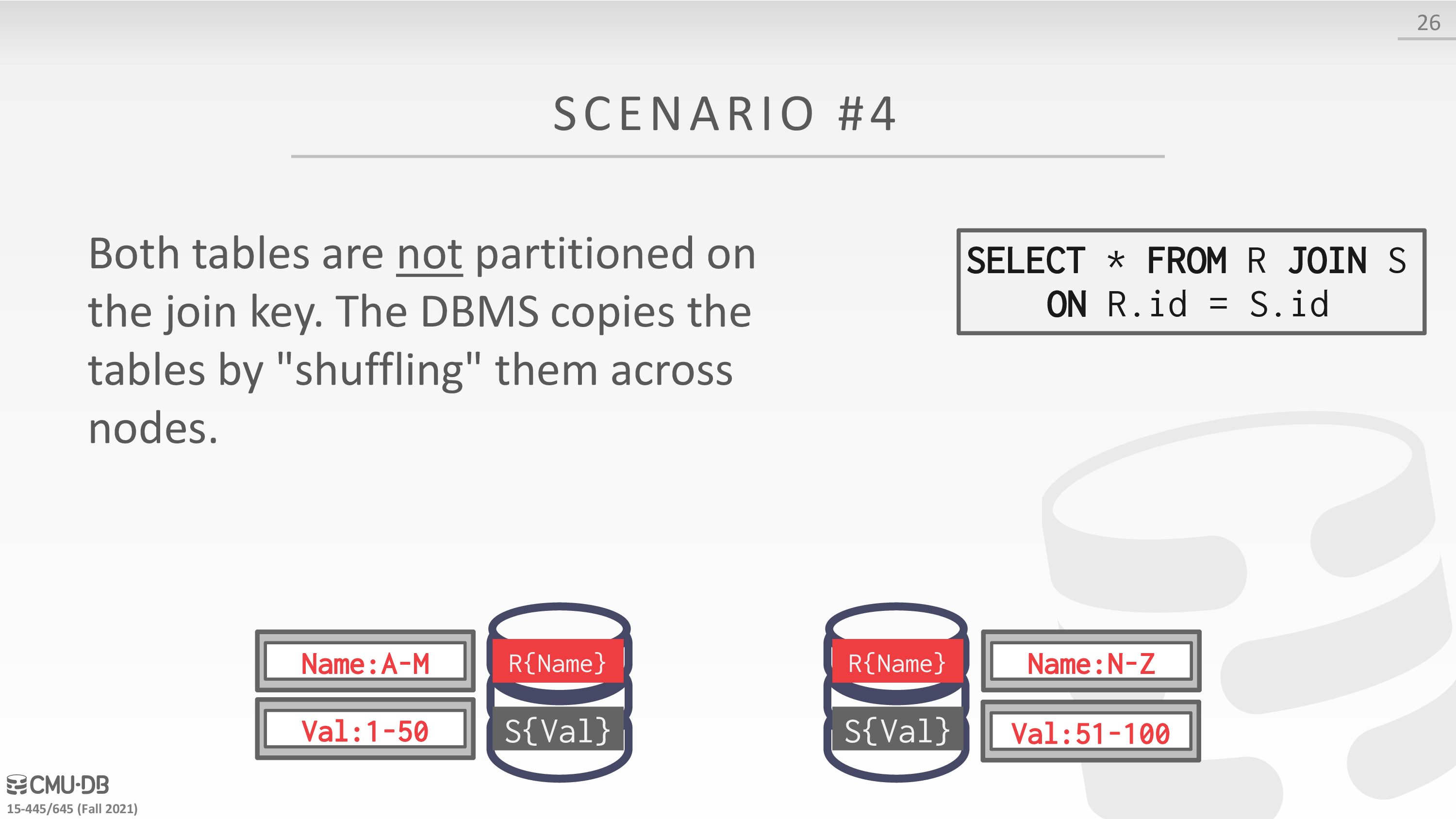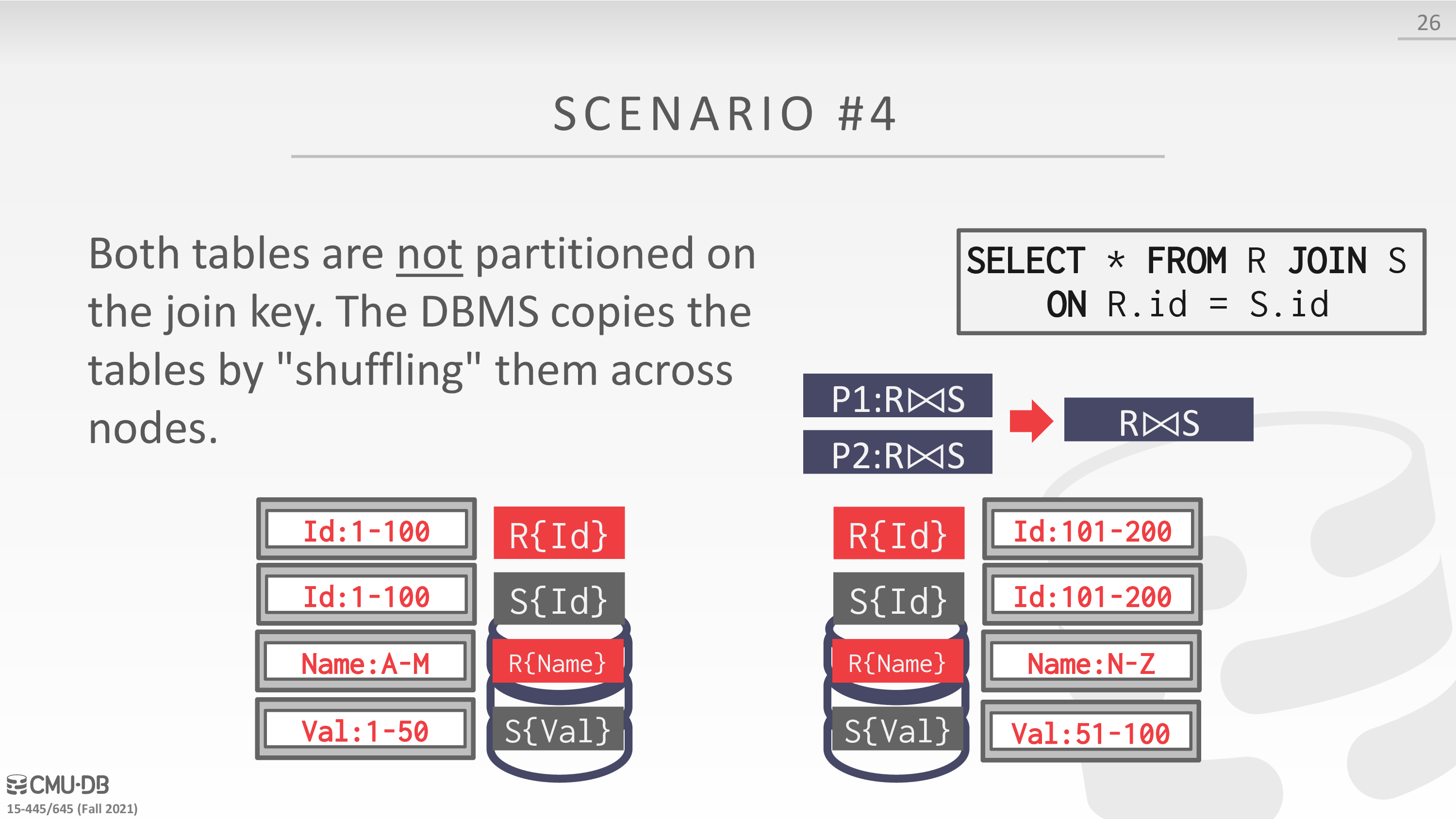
Distributed Join Algorithms
Cloud Systems
Vendors provide database-as-a-service (DBaaS) offerings that are managed DBMS environments.
Newer systems are starting to blur the lines between shared-nothing and shared-disk.
- Managed DBMSs
- No significant modification to the DBMS to be aware that it is running in a cloud environment.
- Cloud-Native DBMS
- The system is designed explicitly to run in a cloud environment.
- Usually based on a shared-disk architecture.
- Serverless Databases

Disaggregated Components
- System Catalogs: HCatalog, Google Data Catalog, Amazon Glue Data Catalog
- Node Management: Kubernetes, Apache YARN, Cloud Vendor Tools
- Query Optimizers: Greenplum Orca, Apache Calcite
- Universal Formats
- Apache Parquet: Compressed columnar storage from Cloudera/Twitter.
- Apache ORC: Compressed columnar storage from Apache Hive.
- Apache CarbonData: Compressed columnar storage with indexes from Huawei.
- Apache Iceberg: Flexible data format that supports schema evolution from Netflix.
- HDF5: Multi-dimensional arrays for scientific workloads.
- Apache Arrow: In-memory compressed columnar storage from Pandas/Dremio.