TOC
Open TOC
lab2
官方提供了相当多的参考资料
https://pdos.csail.mit.edu/6.824/labs/raft-locking.txt
https://pdos.csail.mit.edu/6.824/labs/raft-structure.txt
https://pdos.csail.mit.edu/6.824/notes/raft_diagram.pdf
https://thesquareplanet.com/blog/students-guide-to-raft/
https://blog.josejg.com/debugging-pretty/
basic (2A + 2B)
参考 debugging-pretty 进行 log 的打印
VERBOSE=1 go test -race -run 2AVERBOSE=1 go test -race -run 2B编写 python 脚本进行并发测试
100--testsTestInitialElection2ATestReElection2ATestManyElections2ATestBasicAgree2BTestRPCBytes2BTestFailAgree2BTestFailNoAgree2BTestConcurrentStarts2BTestRejoin2BTestBackup2BTestCount2B--race由于并发极大的不确定性,暂定 100 次测试无错误为稳定通过
下面是一些设计决策
对于一个 raft peer 而言,初始化时会有三个 goroutine
- 一个负责 timeout 后发起 election
- 一个负责成为 leader 后发送 heartbeat
- 一个负责更新
commitIndex和lastApplied
这三个 goroutine 在 [150ms, 200ms] 内会被唤醒,而 election timeout 的区间设置为 [300ms, 600ms],尽管存在超时时间差无法完成一轮选举的情形,但随机性可以避免连续出现这种情形
适当延长 heartbeat 的触发时间,以通过 TestCount2B
由于 raft peer 会不定期收到其他 peers 的 rpc 请求,所以其中全程 lock 保护 raft peer state
在进行 rpc 时,由于网络可能断开,所以应通过 goroutine 封装调用逻辑,否则 goroutine 将会被阻塞,并且在启动这些 goroutine 时,raft peer 也许本身不应该持有 lock
以 election 为例,ticker 线程会向其他 peers 发送 RequestVote,并进入死循环
- 在 channel 中接收来自其他 peers 的响应
- 当 votes 过半时,则退出循环,成为 leader,并立刻发送 heartbeat
- 由于在非 main goroutine 读取空的 channel 时会阻塞,所以应该使用 select,避免无法感知到 timeout 的情形
在任何时刻从 RPC 的 request 或 response 中得知 term T > currentTerm 时,都应该立即变成 follower,同时重置 votedFor
由于 heartbeat 本质上是 AppendEntries,所以需要在 authorize leader 和 log consistency check 之后响应,避免给 leader 带来错误的信息
也就是说,成为 leader 立刻发送 heartbeat 不仅仅是为了重置 timeout,也是为了同步 leader 和 followers 之间的 log,当 heartbeat 失败后,resend 的 entry 长度就不为 0 了
更新 timeout 的时机
- 开始一次选举
- 在响应
AppendEntries中 authorize leader 之后 - vote for candidate,避免活锁
在发送 AppendEntries 给其他 peers 的例程中,在进入死循环前,需要保存将要填充到 AppendEntriesArgs 的 raft peer state,从而避免在 resend 时发送不一致的 AppendEntries,接收到成功的响应后,更新 nextIndex 和 matchIndex,其数据仍为之前保存的 raft peer state
commitIndex完全基于matchIndex计算
处理 AppendEntries 的例程中,尤其注意对 log entry 的处理,应忠实的参考论文
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it
也就是说,如果已有的 entry 和新的 entry (args 中的 entry) 没有冲突,那么就不应该截断 PrevLogIndex 之后的 entry,这样做是为了优雅的处理迟到的 old AppendEntries,避免与已经成功响应的 new AppendEntries 冲突
accelerated log backtracking,算法与之前的 fast backup 一致
- If a follower does not have
prevLogIndexin its log, it should return withconflictIndex = len(log)andconflictTerm = None. - If a follower does have
prevLogIndexin its log, but the term does not match, it should returnconflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal toconflictTerm. - Upon receiving a conflict response, the leader should first search its log for
conflictTerm. If it finds an entry in its log with that term, it should setnextIndexto be the one beyond the index of the last entry in that term in its log. - If it does not find an entry with that term, it should set
nextIndex = conflictIndex.
猜测由于没有优化 old AppendEntries,大量 rpc 会带来网络拥塞,于是 TestBackup2B 无法通过 😣
后来分析了 TestBackup2B 的日志,发现了一些可以优化的地方
-
发送
AppendEntries的例程中,若发现自己并非 leader,则应立即退出死循环,之前的实现中只在 rpc 回复的情形下进行了判断,实际上无论是否回复,都应该进行判断- 并且判断应该发生在发送 rpc 的前一步
- 也许并不能保证原子性,有可能在判断后调度到其他 goroutine,于是发送 rpc 时并不能保证自己是 leader
-
更新
lastApplied应一步到位,否则会影响测试中nCommitted的判断 -
Start中不立即发送AppendEntries,而是在 heartbeat 到来时发送,这样可以一次性将多个Start同时发送
可以回顾一下 TestBackup2B 的测试内容,TestBackup2B 共有五个 peers
- 五个 peers 首先达成一次共识
假定 server 1 为 term 1 的 leader
| 1 | |
|---|---|
| server 1 | 1 |
| server 2 | 1 |
| server 3 | 1 |
| server 4 | 1 |
| server 5 | 1 |
- 断开除 leader 外的三个 peers,然后 leader 试图达成 50 次共识
假定断开 server 3 / 4 / 5
| 1 | 2 | … | 51 | |
|---|---|---|---|---|
| server 1 | 1 | 1 | … | 1 |
| server 2 | 1 | 1 | … | 1 |
| server 3 | 1 | |||
| server 4 | 1 | |||
| server 5 | 1 |
此时,server 1 对 server 3 / 4 / 5 的 rpc 会一直持续
- 连接 server 3 / 4 / 5,断开 server 1 / 2,新的 leader 试图达成 50 次共识
假定 server 3 为 term 3 的 leader
| 1 | 2 | … | 51 | |
|---|---|---|---|---|
| server 1 | 1 | 1 | … | 1 |
| server 2 | 1 | 1 | … | 1 |
| server 3 | 1 | 3 | … | 3 |
| server 4 | 1 | 3 | … | 3 |
| server 5 | 1 | 3 | … | 3 |
此时,server 3 对 server 1 / 2 的 rpc 会一直持续
- 断开 server 5,新的 leader 再次试图达成 50 次共识
| 1 | 2 | … | 51 | 52 | … | 101 | |
|---|---|---|---|---|---|---|---|
| server 1 | 1 | 1 | … | 1 | |||
| server 2 | 1 | 1 | … | 1 | |||
| server 3 | 1 | 3 | … | 3 | 3 | … | 3 |
| server 4 | 1 | 3 | … | 3 | 3 | … | 3 |
| server 5 | 1 | 3 | … | 3 |
- 只连接 server 1 / 2 / 5,新的 leader 试图达成 50 次共识
假定 server 5 为 term 42 的 leader,那么 server 1 / 2 的 log 就会被 truncate 了
| 1 | 2 | … | 51 | 52 | … | 101 | |
|---|---|---|---|---|---|---|---|
| server 1 | 1 | 3 | … | 3 | 42 | … | 42 |
| server 2 | 1 | 3 | … | 3 | 42 | … | 42 |
| server 3 | 1 | 3 | … | 3 | 3 | … | 3 |
| server 4 | 1 | 3 | … | 3 | 3 | … | 3 |
| server 5 | 1 | 3 | … | 3 | 42 | … | 42 |
此时,server 1 对 server 3 / 4 / 5 的 rpc 中断
- 全部连接,试图达成一次共识
理想情形如下,server 5 仍为 term 42 的 leader
| 1 | 2 | … | 51 | 52 | … | 101 | 102 | |
|---|---|---|---|---|---|---|---|---|
| server 1 | 1 | 3 | … | 3 | 42 | … | 42 | 42 |
| server 2 | 1 | 3 | … | 3 | 42 | … | 42 | 42 |
| server 3 | 1 | 3 | … | 3 | 42 | … | 42 | 42 |
| server 4 | 1 | 3 | … | 3 | 42 | … | 42 | 42 |
| server 5 | 1 | 3 | … | 3 | 42 | … | 42 | 42 |
persistence (2C)
只需在如下字段发生变化时调用 persist 即可
- log
- currentTerm
- votedFor
通常是在辅助函数中更新这些字段,所以需要添加的地方并不多
注意在 Make 初始化中不应调用这些辅助函数,否则会覆盖原来的持久化数据,readPersist 就读取不到了
测试如下
VERBOSE=1 go test -race -run 2C并发测试
100--testsTestPersist12CTestPersist22CTestPersist32CTestFigure82CTestUnreliableAgree2CTestFigure8Unreliable2CTestReliableChurn2CTestUnreliableChurn2C--race测试中发现 TestFigure8Unreliable2C 并不能稳定通过,通过率约为 97%
对于几千甚至上万行的日志,感觉很难找到问题所在,于是只能增加小型测试的测试次数,以期发现细微的 bug
snapshot (2D)
可以通过如下方式实时优化日志显示
VERBOSE=1 go test -race -run TestSnapshotBasic2D | ./dslogs.py -c 3并发测试
100--testsTestSnapshotBasic2DTestSnapshotInstall2DTestSnapshotInstallUnreliable2DTestSnapshotInstallCrash2DTestSnapshotInstallUnCrash2DTestSnapshotAllCrash2D--race主要内容就是实现 Snapshot 函数和 InstallSnapshot rpc
首先需要考虑 shrink log 的实现,使用 log[0] 这个 dummy log 记录 lastIncludedIndex 和 lastIncludedTerm,这样持久化的部分就不必记录额外的字段了
为 LogEntry 添加新的字段 index,对于所有 log[i] 的下标访问,都需要减去 lastIncludedIndex
然后大面积重写 AppendEntries,关键在于定位 prevLogIndex 在原 log 中的下标,若下标 <= 0,代表 prev log 在 snapshot 中,因而无法比对,考虑到存在过时的 AppendEntries,这种情形是可能发生的,因而需要特判一下,不必重传了
接下来修改 startAgreementHelper,需要额外考虑 nextIndex <= lastIncludedIndex 的情形,此时若发送 AppendEntries,那么必定会出现 prev log 在 snapshot 中,所以应当发送 InstallSnapshot
对于 InstallSnapshot request 的响应,只要满足 lastIncludedIndex <= commitIndex,那么就无条件接受该 snapshot,其 safety 的原因是该 snapshot 已经是大多数 peers 达成共识的结果
对于 InstallSnapshot response 的响应,首先不必重传,然后若响应失败,代表 nextIndex 已经过时了,所以需要根据响应更新 nextIndex,否则就会陷入活锁
最后是持久化的部分,在 Snapshot 函数和接受 snapshot 两种情形下需要调用 SaveStateAndSnapshot,在 peer crash 的情形下,框架代码会自动 apply 持久化的 snapshot,所以只需更新 lastApplied 和 commitIndex 即可
其余修改的一些地方
- 异步 applier,也就是 apply 的时候不要持有锁,避免 channel 的阻塞影响 timer
- 在发送 rpc 前进行更多的检查,上文中检查了是否为 leader,还可以检查 term 以及
nextIndex是否已经过时
由于打印日志会消耗一些时间,可以修改 config 的 checkTimeout 延长 2 分钟的时限
test
with
-race
2A

2B 时间有点长

2C

2D 时间也有点长
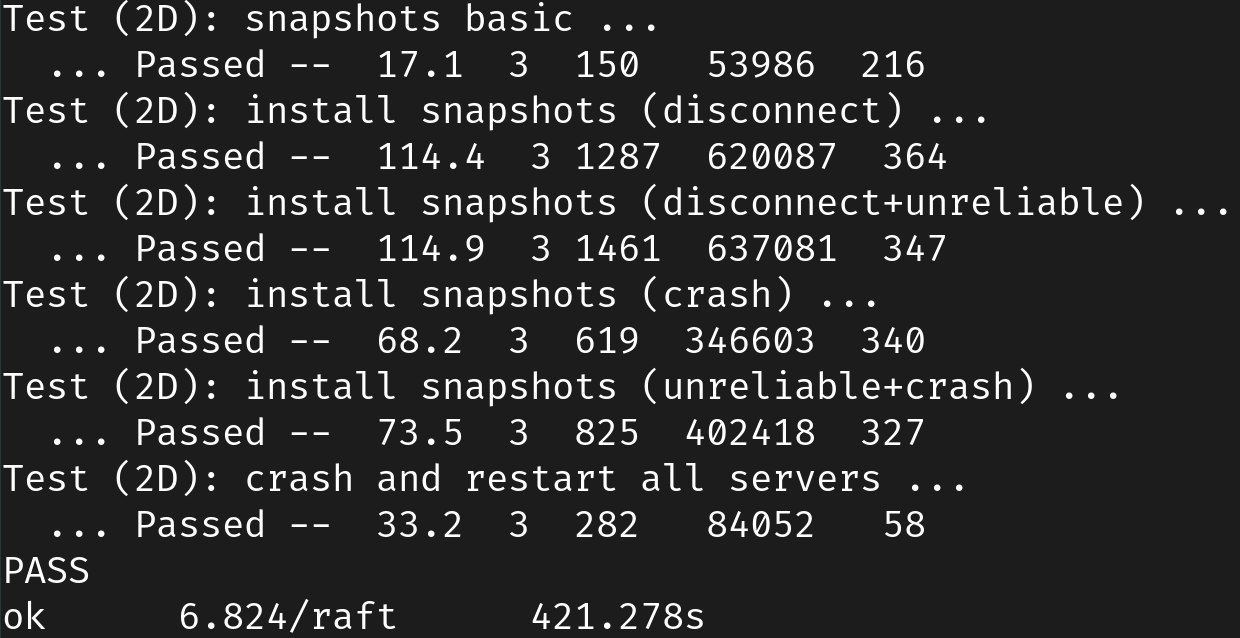
合起来时间略超过 10 分钟